Quality Prediction and Abnormal Processing Parameter Identification in Polypropylene Fiber Melt Spinning Using Artificial Intelligence Machine Learning and Deep Learning Algorithms
논문 정보
- 제목: Quality Prediction and Abnormal Processing Parameter Identification in Polypropylene Fiber Melt Spinning Using Artificial Intelligence Machine Learning and Deep Learning Algorithms
- 저자: Amit Kumar Gope, Yu-Shu Liao, Chung-Feng Jeffrey Kuo (National Taiwan University of Science and Technology)
- 학회/저널: Polymers
- 발행일: 2022-07-04
- DOI: 10.3390/polym14132739
- 주요 연구 내용: 딥러닝 신경망을 사용하여 폴리프로필렌(PP) 용융 방사 공정의 다중 품질 특성을 예측하고 최적의 공정 파라미터를 탐색함. 이후, 품질 이상 데이터가 주어졌을 때 랜덤 포레스트를 포함한 여러 머신러닝 및 딥러닝 방법을 비교하여 이상 원인이 되는 공정 파라미터를 식별하는 2단계 진단 시스템을 개발.
- 주요 결과 및 결론: 랜덤 포레스트 모델이 이상 공정 파라미터 식별에서 가장 우수한 성능을 보임. 단일/이중 요인 식별 정확도 100%, 단일 요인 분류 정확도 98.3%, 이중 요인 분류 정확도 96.0%를 달성하여 제안된 진단 방법의 효과를 입증.
- 기여점: PP 용융 방사 공정에서 제품 품질 저하의 원인이 되는 공정 파라미터를 신속하고 정확하게 진단하는 인공지능 기반 시스템을 제안함. 이를 통해 기존의 전문가 의존적 분석 시간을 단축하고 공정 제어 안정성을 높여 생산 비용 절감에 기여.
요약
초록
본 연구는 인공지능 알고리즘을 활용하여 폴리프로필렌(PP) 용융 방사 공정에서 발생하는 이상 공정 파라미터를 탐지하고 품질 개선 전략을 제안하는 시스템을 개발했다. 6개의 공정 파라미터(스크류 온도, 기어 펌프 온도, 다이 헤드 온도, 스크류 속도, 기어 펌프 속도, 인취 속도)와 4개의 품질 특성(섬도, 파단 강도, 파단 신도, 탄성 에너지 계수)을 다루었다. 첫 번째 단계에서는 440개의 과거 데이터를 사용하여 딥러닝 신경망을 훈련시켜 다중 품질 최적화 방법을 결정했다. 두 번째 단계에서는 최적의 파라미터를 기준으로 품질 이상 데이터의 원인이 되는 공정 파라미터를 찾는 여러 머신러닝 및 딥러닝 방법의 성능을 비교했다. 그 결과, 랜덤 포레스트 방법이 가장 뛰어난 성능을 보였으며, 단일 및 이중 요인 식별에서 100%, 단일 요인 분류에서 98.3%, 이중 요인 분류에서 96.0%의 높은 정확도를 달성했다. 이는 본 연구에서 제안한 진단 방법이 제품 이상을 효과적으로 예측하고 원인 파라미터를 정확히 찾아낼 수 있음을 확인시켜 준다.
서론
용융 방사는 비용 효율성과 공정 안정성으로 인해 합성 섬유 제조에 널리 사용되지만, 장비 마모, 작업자 경험 부족 등 여러 요인으로 인해 제품 품질이 저하될 수 있다. 현재 산업계에서는 이러한 문제 해결을 대부분 기술자의 전문성에 의존하고 있어 시간과 비용이 많이 소요된다. 따라서 본 연구는 품질 이상과 공정 파라미터 간의 연관성을 분석하는 체계적인 기술을 개발하여, 제품 품질을 안정시키고 생산 비용을 절감하는 것을 목표로 한다. 이를 위해 널리 사용되는 PP 섬유를 연구 대상으로 선정하고, 딥러닝 신경망과 랜덤 포레스트를 활용한 효율적인 품질 이상 진단 시스템을 제안한다.
모델 아키텍처 / 방법론
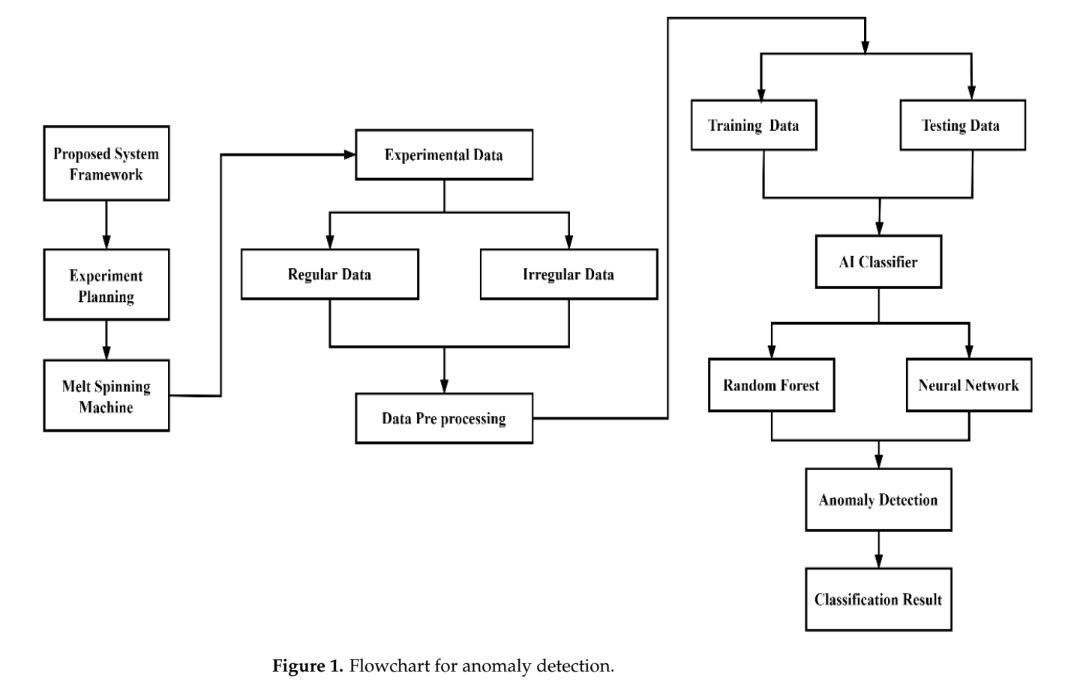
-
핵심 구조/방법: 연구는 논문의 Figure 1에 제시된 흐름도에 따라 2단계로 진행된다. 첫째, 딥러닝 신경망(DNN)을 사용하여 6개의 공정 파라미터 입력에 대해 4개의 품질 특성을 예측하는 모델을 구축하고, 이를 통해 최적의 공정 조건을 탐색한다. 둘째, 최적 조건에서 벗어난 이상 품질 데이터가 주어졌을 때, 그 원인이 되는 공정 파라미터를 식별하기 위해 AI 분류기(특히 랜덤 포레스트)를 사용한다. 이 분류 과정은 (1) 이상 요인이 1개인지 2개인지 판별하는 '단일/이중 식별', (2) 단일 요인일 경우 원인을 분류하는 '단일 요인 분류', (3) 이중 요인일 경우 원인 조합을 분류하는 '이중 요인 분류'의 세 단계로 구성된다.
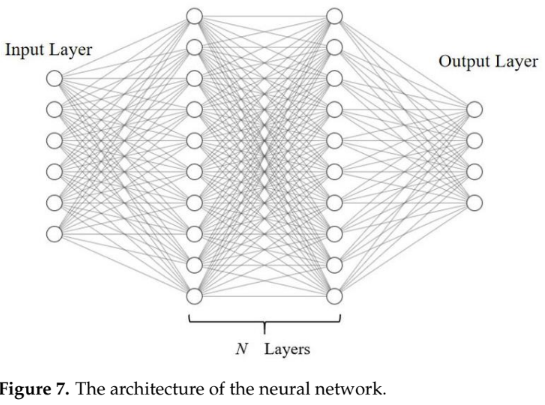
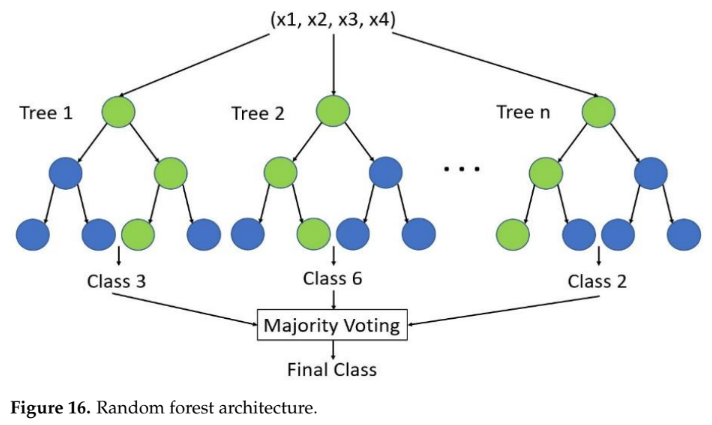
-
주요 구성 요소:
- 딥러닝 신경망 (DNN): 다중 품질 예측을 위해 사용되었다. 입력층(6개 파라미터), 은닉층, 출력층(4개 품질 특성)으로 구성된다. 은닉층에는 Mish 활성화 함수, 출력층에는 Sigmoid 함수를 사용했으며, SGDM 옵티마이저로 최적화하여 최상의 성능을 얻었다. 논문의 Figure 7은 신경망의 기본 아키텍처를 보여준다.
- 랜덤 포레스트 (Random Forest): 이상 원인 분류에 사용된 핵심 모델이다. 다수의 결정 트리를 앙상블하여 과적합을 방지하고 높은 분류 정확도를 달성한다. 논문의 Figure 16은 랜덤 포레스트의 구조를 나타낸다.
-
수식:
- 뉴런 출력:
- 가중치 업데이트 (경사 하강법):
- Mish 활성화 함수:
- 평균 절대 오차 (MAE):
- 평균 제곱근 오차 (RMSE):
- 분류기 입력 특징 (예측값과 실제값의 차이):
실험 결과
- 주요 데이터셋:
- 품질 예측 모델 학습: 440개의 과거 용융 방사 측정 기록을 사용 (훈련 330개, 검증 110개).
- 이상 분류기 학습: 최적 파라미터로 생성한 정상 샘플 20개와 의도적으로 파라미터를 변경하여 생성한 비정상 샘플 420개(단일 요인 이상 120개, 이중 요인 이상 300개)를 사용. 이 데이터는 훈련 220개와 검증 220개로 분할되었다.
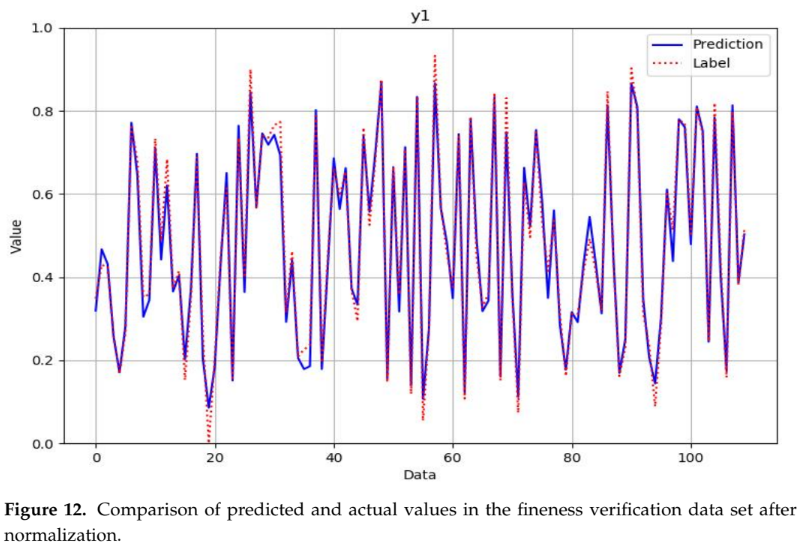
- 핵심 성능 지표:
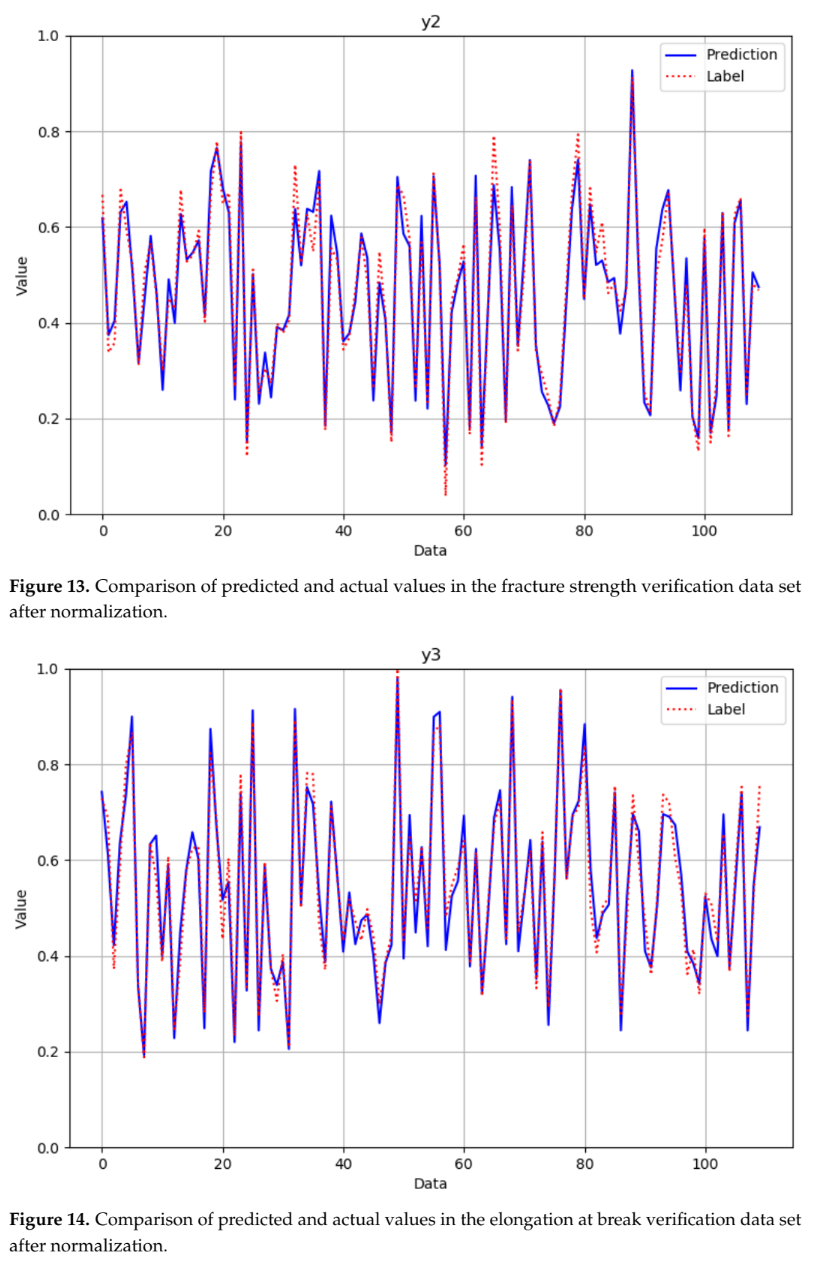
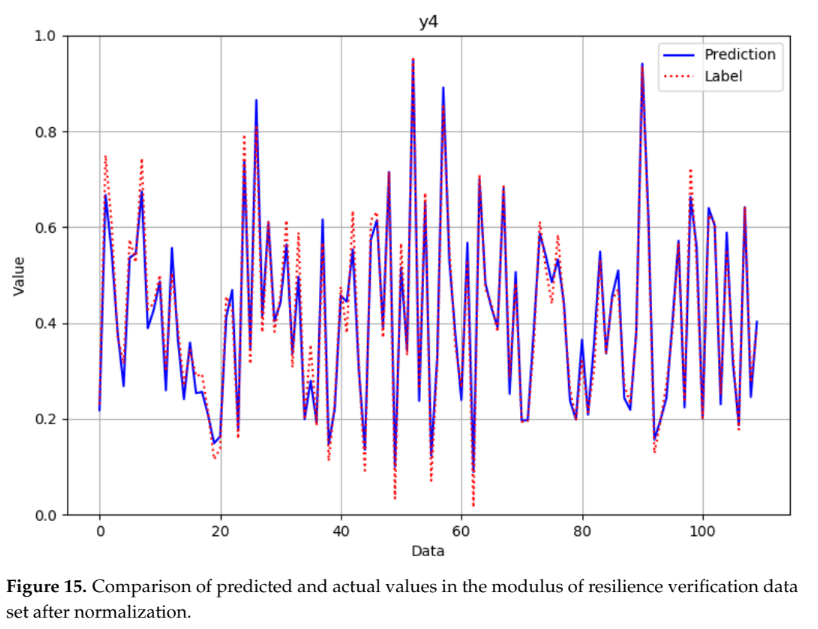
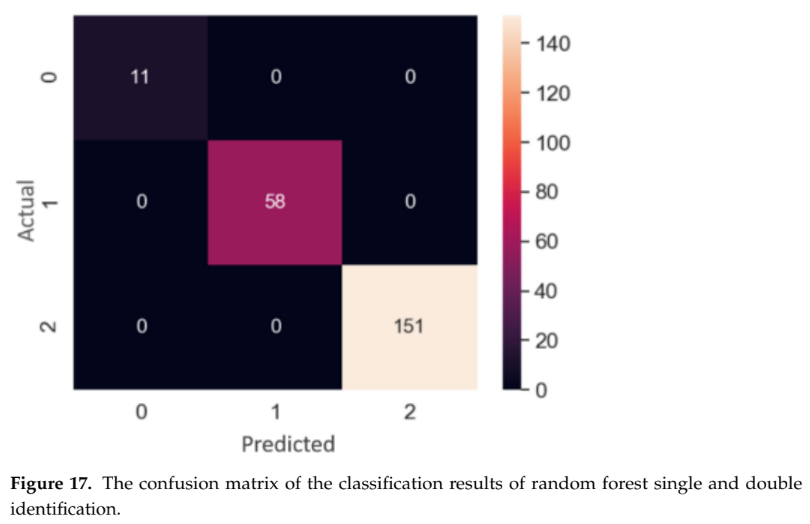
- DNN 품질 예측 모델: 검증 데이터셋에서 MAE 0.071, RMSE 0.091의 낮은 오차율을 기록했다. 논문의 Figure 12부터 15까지의 그래프는 모델의 예측값과 실제값이 매우 근접함을 보여준다.
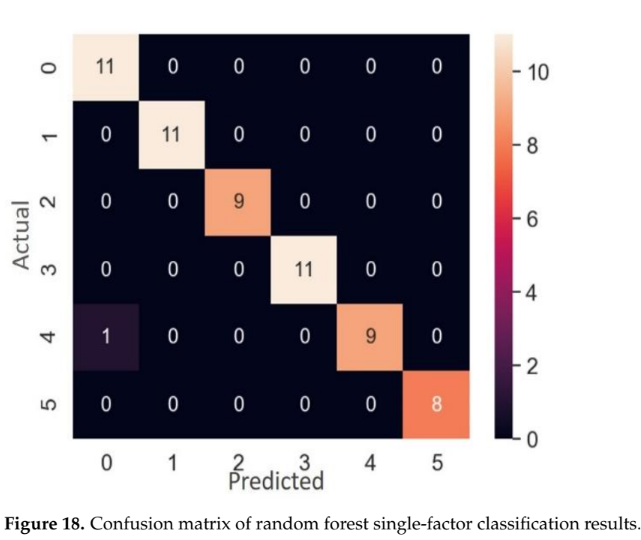
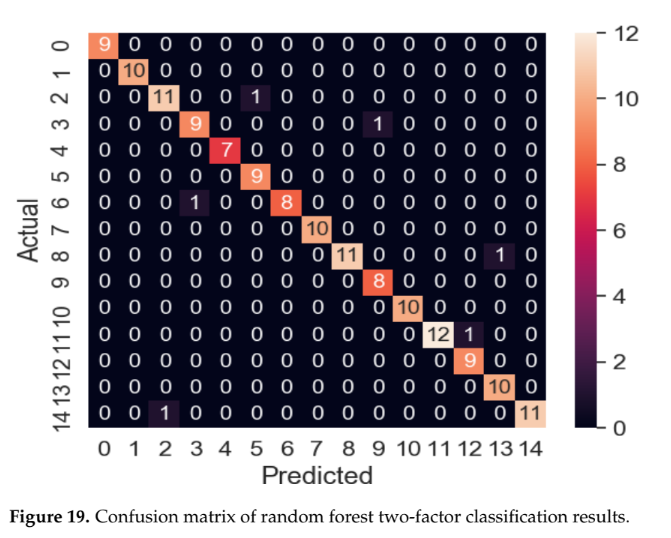
- 랜덤 포레스트 이상 분류 모델: '탐지 성공률'을 주요 지표로 사용했다. 단일/이중 식별에서 100%, 단일 요인 분류에서 98.3%, 이중 요인 분류에서 96.0%의 높은 정확도를 달성했다. 논문의 Figure 17, 18, 19의 혼동 행렬은 각 분류 단계에서의 우수한 성능을 시각적으로 보여준다.
- 비교 결과:
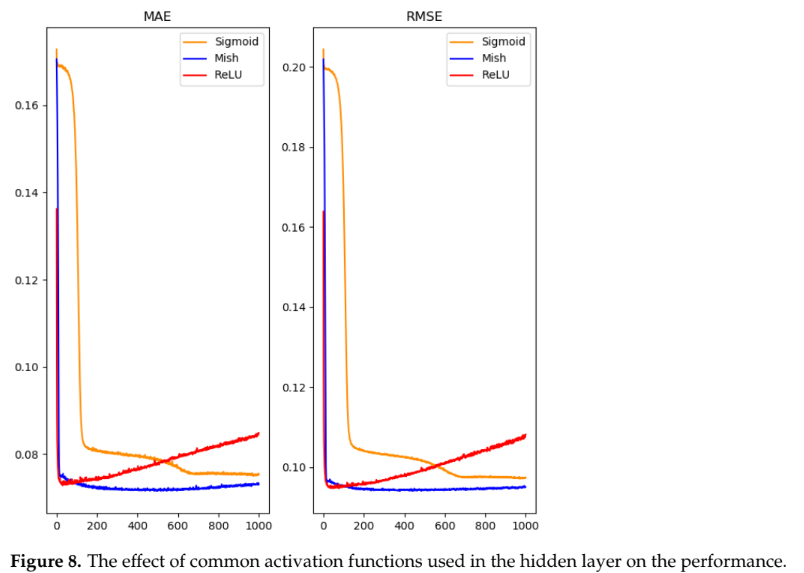
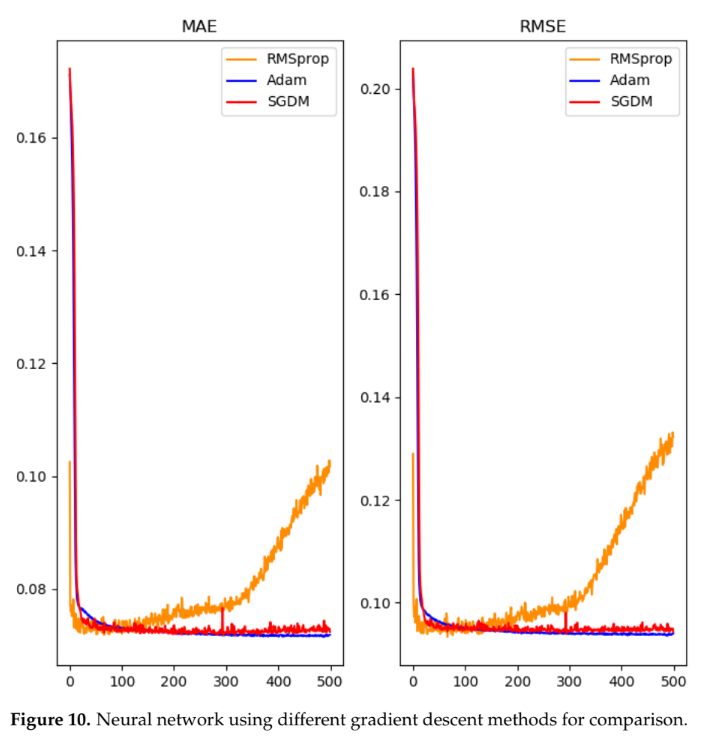
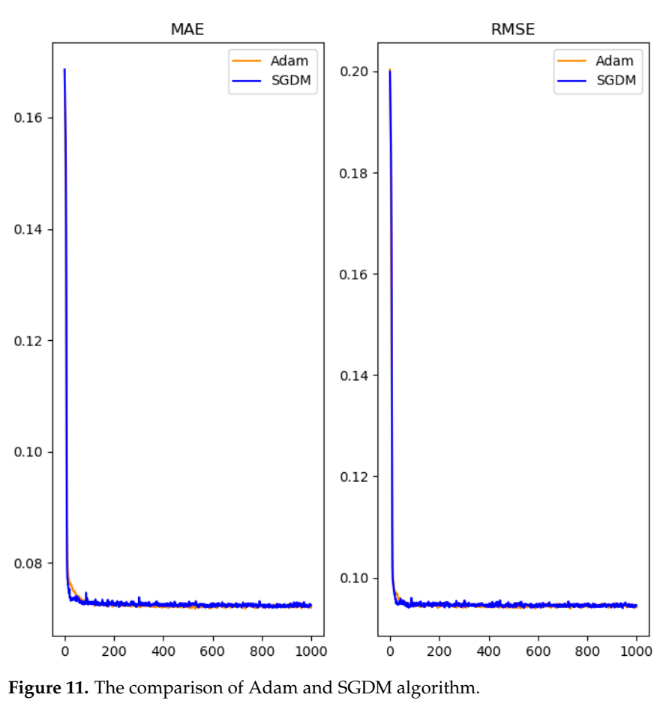
- 활성화 함수 및 옵티마이저: DNN 훈련 시, Mish 활성화 함수가 ReLU나 Sigmoid보다 빠르고 안정적으로 수렴했으며(Figure 8), SGDM 옵티마이저가 Adam이나 RMSProp보다 약간 더 나은 성능을 보였다(Figure 10, 11).
- 분류 알고리즘: 이상 원인 분류에서 랜덤 포레스트는 모든 단계에서 결정 트리, 서포트 벡터 머신(SVM), 신경망 등 다른 머신러닝 알고리즘보다 월등한 성능을 보였다.
결론
본 연구는 딥러닝 신경망과 랜덤 포레스트를 결합하여 PP 용융 방사 공정의 품질을 예측하고 이상 원인을 진단하는 효과적인 시스템을 성공적으로 개발했다. 제안된 DNN 모델은 전통적인 실험 계획법보다 빠르고 효율적으로 최적의 공정 파라미터를 도출할 수 있었다. 또한, 랜덤 포레스트 기반의 분류기는 96% 이상의 높은 정확도로 품질 이상의 원인이 되는 공정 파라미터를 식별해냈다. 이 시스템은 현장 엔지니어가 신속하게 문제를 진단하고 조치하여 생산 수율을 높이고 비용을 절감하는 데 실용적인 도구가 될 수 있다.