Deep Residual Learning for Image Recognition
논문 정보
- 제목: Deep Residual Learning for Image Recognition
- 저자: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun (Microsoft Research)
- 학회/저널: arXiv (ILSVRC 2015 우승)
- 발행일: 2015-12-10
- DOI: arxiv.org/abs/1512.03385
- 주요 연구 내용: 네트워크가 깊어질수록 정확도가 떨어지는 'degradation' 문제를 해결하기 위해 잔차 학습(residual learning) 프레임워크를 제안함. 네트워크가 목표 함수를 직접 학습하는 대신, 입력에 대한 잔차 함수(residual function)를 학습하도록 shortcut connection을 도입하여 매우 깊은 네트워크의 최적화를 용이하게 함.
- 주요 결과 및 결론: ImageNet 데이터셋에서 최대 152개 레이어의 매우 깊은 잔차 네트워크(ResNet)를 성공적으로 훈련시켰으며, 이는 VGGNet보다 8배 깊지만 복잡도는 더 낮음. ResNet 앙상블 모델은 ImageNet test set에서 3.57%의 top-5 error를 달성하여 ILSVRC 2015 분류 과제에서 1위를 차지함.
- 기여점: 심층 신경망의 'degradation' 문제를 해결하는 잔차 학습 프레임워크(ResNet)를 제안함. 이전보다 훨씬 깊은 네트워크(152-layer)의 훈련을 가능하게 하여 이미지 인식 분야에서 SOTA(State-of-the-art) 성능을 달성함. 잔차 학습의 효과를 ImageNet 및 CIFAR-10 데이터셋에서 실험적으로 증명하고, COCO 데이터셋을 사용한 객체 탐지에서도 우수성을 입증함.
요약
초록
기존의 심층 신경망은 깊이가 깊어질수록 훈련이 더 어려워지는 문제가 있어, 본 논문은 이 문제를 해결하기 위해 잔차 학습(residual learning) 프레임워크를 제시한다. 기존 방식처럼 참조되지 않은 함수를 학습하는 대신, 레이어의 입력값을 참조하여 잔차 함수를 학습하도록 레이어를 재구성한다. 실험을 통해 잔차 네트워크가 최적화하기 더 쉽고, 깊이가 상당히 증가함에 따라 정확도를 높일 수 있음을 확인했다. ImageNet 데이터셋에서 최대 152개 레이어 깊이의 ResNet을 평가했으며, 이는 VGGNet보다 8배 깊지만 복잡도는 더 낮다. 이 ResNet 앙상블은 ImageNet 테스트에서 3.57%의 오류율로 ILSVRC 2015 분류 과제에서 1위를 차지했다.
서론
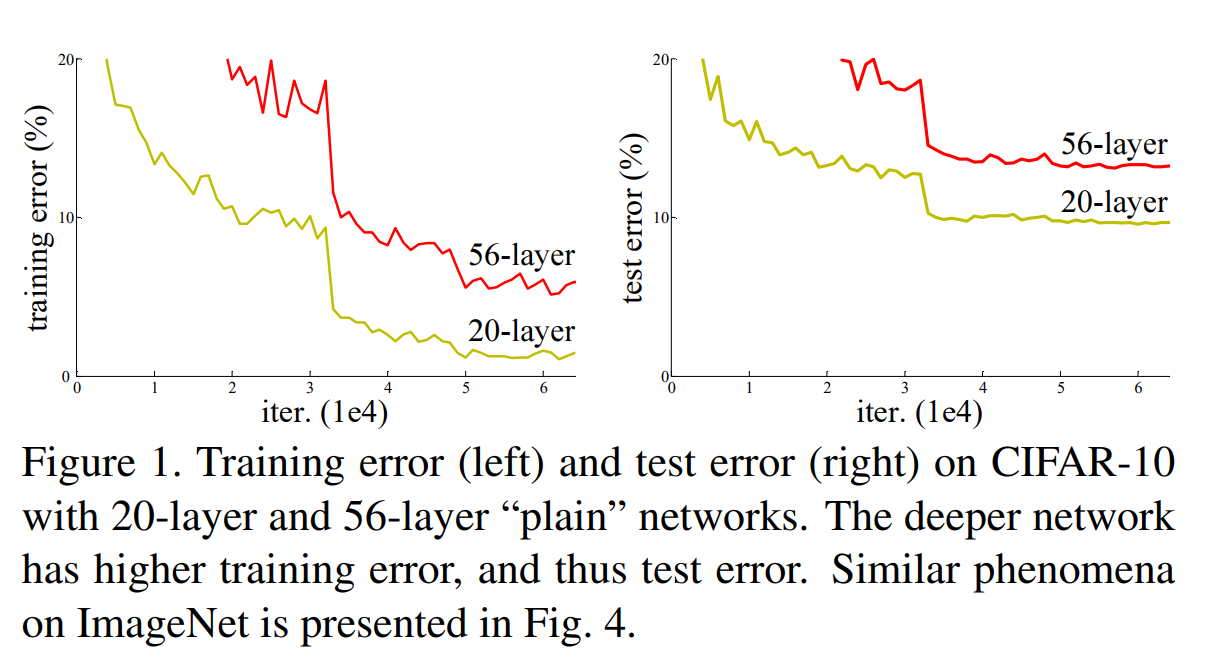
 심층 컨볼루션 신경망(Deep CNNs)의 깊이는 이미지 인식 성능에 매우 중요한 요소이다. 하지만 단순히 레이어를 더 쌓는 것만으로는 네트워크 성능이 향상되지 않는다. 네트워크 깊이가 특정 수준을 넘어서면 정확도가 포화 상태에 이르다가 급격히 감소하는 'degradation' 문제가 발생한다. 이 문제는 과적합(overfitting) 때문이 아니며, 오히려 깊은 모델에서 더 높은 훈련 에러(training error)가 나타나는 현상이다. 논문의 Figure 1은 20-layer 와 56-layer 일반 네트워크(plain network)를 비교하며, 더 깊은 56-layer 네트워크의 훈련 및 테스트 에러가 더 높은 것을 보여준다. 본 연구는 이 degradation 문제를 해결하기 위해 잔차 학습 프레임워크를 제안한다.
심층 컨볼루션 신경망(Deep CNNs)의 깊이는 이미지 인식 성능에 매우 중요한 요소이다. 하지만 단순히 레이어를 더 쌓는 것만으로는 네트워크 성능이 향상되지 않는다. 네트워크 깊이가 특정 수준을 넘어서면 정확도가 포화 상태에 이르다가 급격히 감소하는 'degradation' 문제가 발생한다. 이 문제는 과적합(overfitting) 때문이 아니며, 오히려 깊은 모델에서 더 높은 훈련 에러(training error)가 나타나는 현상이다. 논문의 Figure 1은 20-layer 와 56-layer 일반 네트워크(plain network)를 비교하며, 더 깊은 56-layer 네트워크의 훈련 및 테스트 에러가 더 높은 것을 보여준다. 본 연구는 이 degradation 문제를 해결하기 위해 잔차 학습 프레임워크를 제안한다.
모델 아키텍처 / 방법론
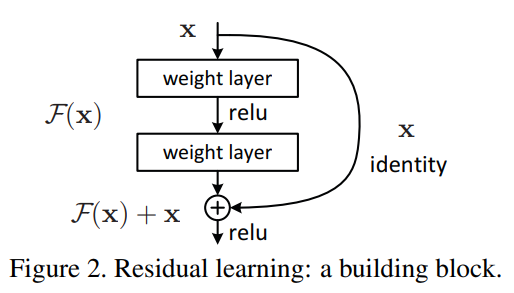
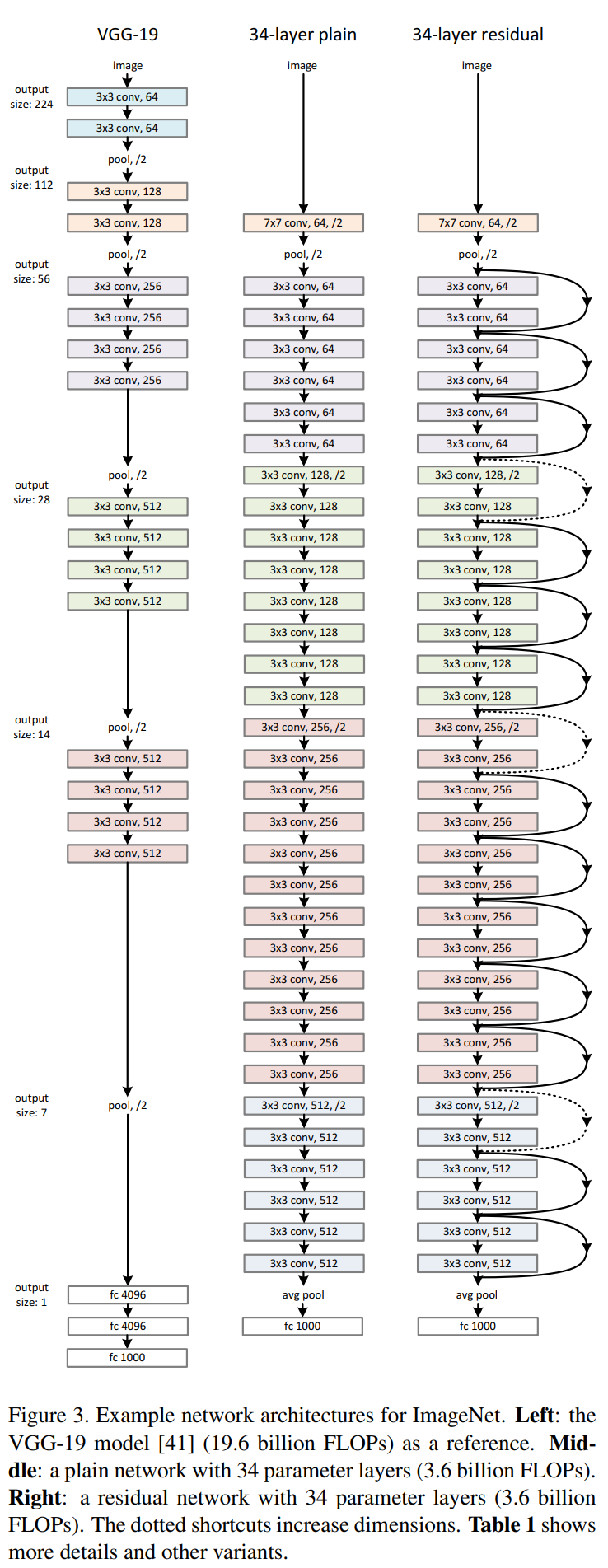
- 핵심 구조/방법: 잔차 학습의 핵심 아이디어는 네트워크의 일부 레이어들이 목표 함수 를 직접 근사하는 대신, 잔차 함수 mathcalF(x):=mathcalH(x)−x를 학습하도록 하는 것이다. 원래 학습하려던 함수는 mathcalH(x)=mathcalF(x)+x 형태로 재구성한다. 이 구조는 'shortcut connection'을 통해 구현되며, 이는 하나 이상의 레이어를 건너뛰어 입력을 출력에 바로 더해주는 연결이다. 논문의 Figure 2는 이 기본 빌딩 블록을 보여준다.
- 주요 구성 요소:
- Residual Block: 여러 개의 가중치 레이어(e.g., 2개의 3x3 Conv 레이어)와 입력
x를 출력에 더해주는 identity shortcut connection으로 구성된다. - Shortcut Connection: 파라미터나 추가적인 계산 복잡성 없이 identity mapping을 수행함. 입력과 출력의 차원이 다를 경우, 차원을 맞추기 위해 1x1 컨볼루션을 사용하는 projection shortcut을 적용할 수 있다.
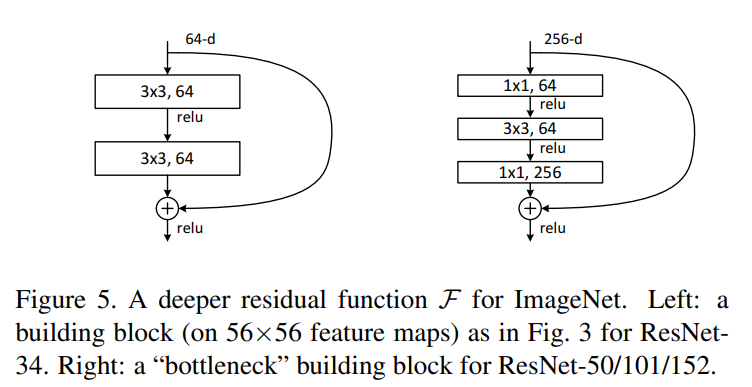
- Bottleneck Architecture: 50개 이상의 깊은 레이어를 가진 ResNet을 효율적으로 구성하기 위해 'bottleneck' 디자인을 사용한다. 이는 1x1, 3x3, 1x1 컨볼루션 레이어 3개로 구성되며, 1x1 컨볼루션이 채널 차원을 줄였다가 다시 늘리는 역할을 하여 3x3 컨볼루션의 연산량을 줄인다. 논문의 Figure 5(우측)에서 구조를 확인할 수 있다.
- Residual Block: 여러 개의 가중치 레이어(e.g., 2개의 3x3 Conv 레이어)와 입력
- 수식: 잔차 블록의 연산은 다음 수식으로 표현된다. 여기서
x는 입력,y는 출력, 는 학습할 잔차 매핑이다.- Identity Shortcut: y=mathcalF(x,W_i)+x
- Projection Shortcut: y=mathcalF(x,W_i)+W_sx
- 알고리즘: VGGNet을 기반으로 한 plain network 아키텍처(Figure 3, 중앙)에 shortcut connection을 추가하여 residual network(Figure 3, 우측)를 구성한다. 특징 맵의 크기가 절반으로 줄어들고 채널 수가 두 배로 늘어나는 지점에서 차원을 맞추기 위해 stride 2를 갖는 projection shortcut 또는 zero-padding을 사용한다.
실험 결과
- 주요 데이터셋: ImageNet 2012 (1,000개 클래스, 128만장 학습 이미지)와 CIFAR-10 (10개 클래스, 5만장 학습 이미지)데이터셋을 사용하여 실험을 진행한다.
- 핵심 성능 지표:
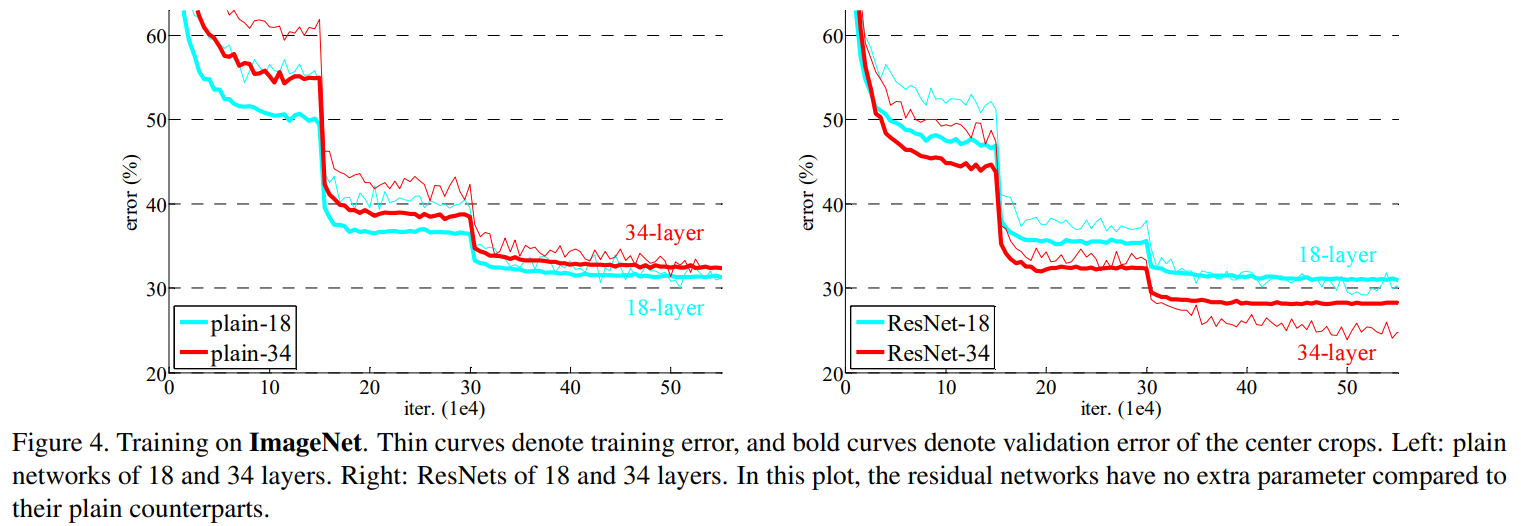
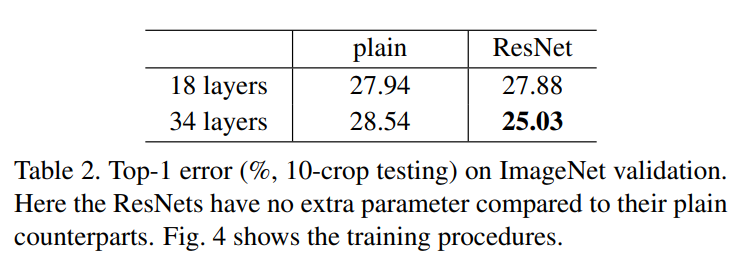
- Degradation 문제 해결: ImageNet 실험에서 34-layer plain network는 18-layer plain network보다 높은 에러율을 보인 반면, 34-layer ResNet은 18-layer ResNet보다 2.8% 더 낮은 에러율을 기록한다(Table 2). 이를 통해 ResNet이 깊이가 깊어짐에 따라 발생하는 성능 저하 문제를 효과적으로 해결했음을 보여준다. 논문의 Figure 4는 plain network의 degradation 현상과 ResNet의 성능 향상을 시각적으로 비교한다.
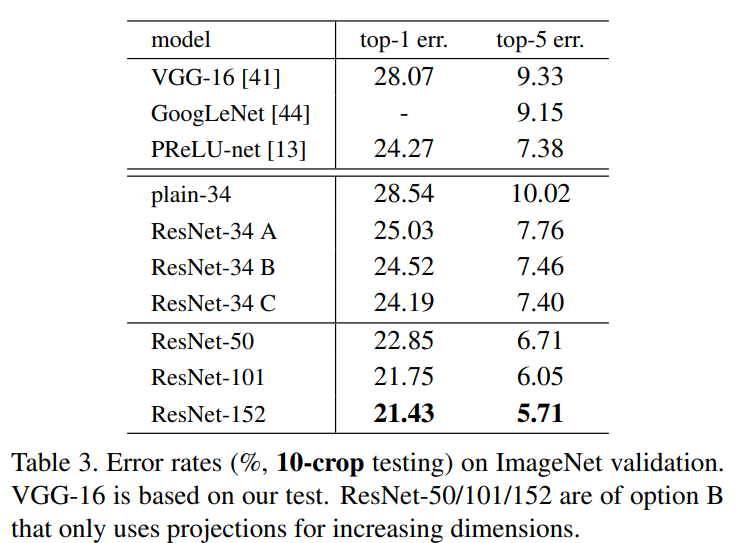
- 깊이에 따른 성능 향상: ResNet-34, ResNet-50, ResNet-101, ResNet-152로 깊이를 늘려감에 따라 ImageNet 검증 데이터셋에서의 top-1 에러율이 각각 25.03%, 22.85%, 21.75%, 21.43%로 꾸준히 감소함을 확인했다(Table 3).
- SOTA 달성: 152-layer ResNet 기반의 앙상블 모델은 ImageNet 2015 테스트 데이터셋에서 3.57%의 top-5 error를 달성하여 대회에서 1위를 차지했다.
- 1000-layer 이상 네트워크: CIFAR-10 데이터셋에서 110-layer ResNet이 우수한 성능(6.43% error)을 보였으며, 심지어 1202-layer 네트워크도 최적화 문제 없이 훈련이 가능함을 보여줬다(테스트 에러 7.93%). 이는 과적합 문제를 보였지만, 잔차 학습이 극도로 깊은 네트워크의 최적화를 가능하게 함을 증명한다.
- 비교 결과: 34-layer plain network와 34-layer ResNet을 비교했을 때, ResNet이 top-1 에러를 3.5% 가량 낮췄다(28.54% → 25.03%). 이는 잔차 학습이 깊은 네트워크의 훈련 에러를 성공적으로 줄인 결과다(Table 2). 또한, 152-layer ResNet의 단일 모델 성능(top-5 error 4.49%)은 이전의 모든 앙상블 모델 결과를 능가한다.
결론
본 연구는 네트워크 깊이가 증가할 때 발생하는 degradation 문제를 해결하기 위해 심층 잔차 학습(Deep Residual Learning) 프레임워크를 제안한다. 제안된 ResNet은 shortcut connection을 통해 네트워크가 잔차 함수를 학습하도록 함으로써, 기존보다 훨씬 깊은 네트워크의 최적화를 가능하게 한다. 실험을 통해 152개 레이어, 나아가 1000개 이상의 레이어를 가진 네트워크도 성공적으로 훈련할 수 있음을 보였으며, ImageNet 및 COCO 챌린지에서 SOTA를 달성하여 그 효과를 입증했다. 이 잔차 학습 원리는 이미지 인식뿐만 아니라 다른 분야에도 적용될 수 있는 일반적인 원리이다.