Small Language Models are the Future of Agentic AI
논문 정보
- 제목: Small Language Models are the Future of Agentic AI
- 저자: Peter Belcak, Greg Heinrich, Saurav Muralidharan, Shizhe Diao, Yonggan Fu, Xin Dong, Yingyan Celine Lin, Pavlo Molchanov (Georgia Institute of Technology, NVIDIA Research)
- 학회/저널: arXiv preprint
- 발행일: 2025-06-02
- DOI: 제공되지 않음
- 주요 연구 내용: 에이전트 AI 시스템의 대부분 작업이 반복적이고 범위가 한정되어 있어, 범용 LLM보다는 특정 작업에 특화된 SLM이 더 적합하다고 주장함. SLM이 충분한 성능을 갖추고 있으며(V1), 운영상 더 적합하고(V2), 경제적으로 필연적인 선택(V3)임을 다양한 근거를 통해 설명함.
- 주요 결과 및 결론: 최신 SLM들은 이미 LLM에 필적하는 성능을 보이며 추론 비용, 미세조정, 엣지 배포 등에서 상당한 이점을 가짐. 따라서 에이전트 시스템은 SLM을 기본으로 사용하고 필요할 때만 LLM을 호출하는 이기종(heterogeneous) 시스템으로 발전해야 하며, 이를 위한 LLM-to-SLM 변환 알고리즘을 제안함.
- 기여점: 에이전트 AI 분야에서 LLM 중심 패러다임에 대한 비판적 관점을 제시하고, SLM의 효용성과 경제성을 강조하여 지속 가능하고 책임감 있는 AI 배포의 필요성에 대한 논의를 촉발함. 또한, 기존 LLM 기반 에이전트를 SLM 기반으로 전환할 수 있는 구체적인 알고리즘을 제공함.
요약
초록
대규모 언어 모델(LLM)은 인간에 가까운 성능과 범용 대화 능력으로 높은 평가를 받는다. 그러나 에이전트 AI 시스템의 부상은 언어 모델이 소수의 전문화된 작업을 반복적으로 수행하는 수많은 애플리케이션을 만들어내고 있다. 이 논문은 소규모 언어 모델(SLM)이 에이전트 시스템의 많은 호출에 대해 충분히 강력하고, 본질적으로 더 적합하며, 필연적으로 더 경제적이므로 에이전트 AI의 미래라고 주장한다. 이러한 주장은 SLM의 현재 역량 수준, 일반적인 에이전트 시스템 아키텍처, 그리고 LM 배포의 경제성에 기반을 둔다. 범용 대화 능력이 필수적인 상황에서는 여러 다른 모델을 호출하는 이기종 에이전트 시스템이 자연스러운 선택이라고 주장한다.
서론
에이전트 AI의 도입은 폭발적으로 증가하고 있으며, 현대 경제에서 상당한 역할을 할 것으로 기대된다. 대부분의 현대 AI 에이전트의 핵심 구성 요소는 LLM으로, 전략적 결정, 작업 흐름 제어, 복잡한 작업 분해 등을 수행하는 데 필요한 기본 지능을 제공한다. 현재 산업은 에이전트가 중앙 집중식 클라우드 인프라에서 호스팅되는 단일 범용 LLM의 API를 통해 요청을 처리하는 운영 모델에 깊이 의존하고 있다. 이 논문은 이러한 현 상태에 도전하며, 상대적으로 단순한 에이전트의 요청을 범용 LLM이 처리하는 관행 대신, 작지만 효율적인 SLM이 에이전트 AI의 미래가 되어야 한다고 주장한다.
모델 아키텍처 / 방법론
이 논문은 새로운 모델을 제안하는 대신, SLM이 에이전트 AI의 미래라는 주장을 뒷받침하는 논리적 근거와 전환 방법론을 제시한다.
-
핵심 주장: 논문의 핵심 주장은 세 가지 관점(V1-V3)으로 구성된다.
- V1: SLM은 에이전트 애플리케이션의 언어 모델링 업무를 처리하기에 원칙적으로 충분히 강력하다.
- V2: SLM은 본질적으로 LLM보다 에이전트 시스템에 사용하기에 운영상 더 적합하다.
- V3: SLM은 작은 크기 덕분에 대부분의 에이전트 시스템 사용 사례에서 범용 LLM보다 필연적으로 더 경제적이다.
-
주요 구성 요소 (핵심 논거):
- A1 (성능): 최신 SLM들은 이미 LLM에 필적하는 성능을 보인다. 예를 들어 Microsoft의 Phi-2(2.7B)는 30B 모델과 동등한 상식 추론 및 코드 생성 점수를 기록했다.
- A2 (경제성): 7B SLM을 서빙하는 것은 70-175B LLM보다 10-30배 저렴하다. 미세조정 또한 몇 GPU-hour 만에 가능하여 민첩성이 높다.
- A3 (유연성): SLM은 크기가 작아 훈련 및 배포 비용이 낮으므로, 여러 전문 모델을 특정 에이전트 루틴에 맞게 조정하고 배포하기 용이하다. 이는 AI 기술의 민주화에도 기여한다.
- A4 (기능의 제한성): AI 에이전트는 사실상 LLM의 방대한 능력 중 극히 일부의 기능만을 사용하도록 제한된 게이트웨이이다. 따라서 해당 기능에 맞게 미세조정된 SLM으로 충분하다.
- A5 (동작 정렬): 에이전트는 코드와 상호작용할 때 엄격한 형식(예: JSON)을 준수해야 한다. 단일 형식으로 훈련된 SLM은 다양한 형식을 처리하는 LLM보다 오류 가능성이 낮고 예측 가능성이 높다.
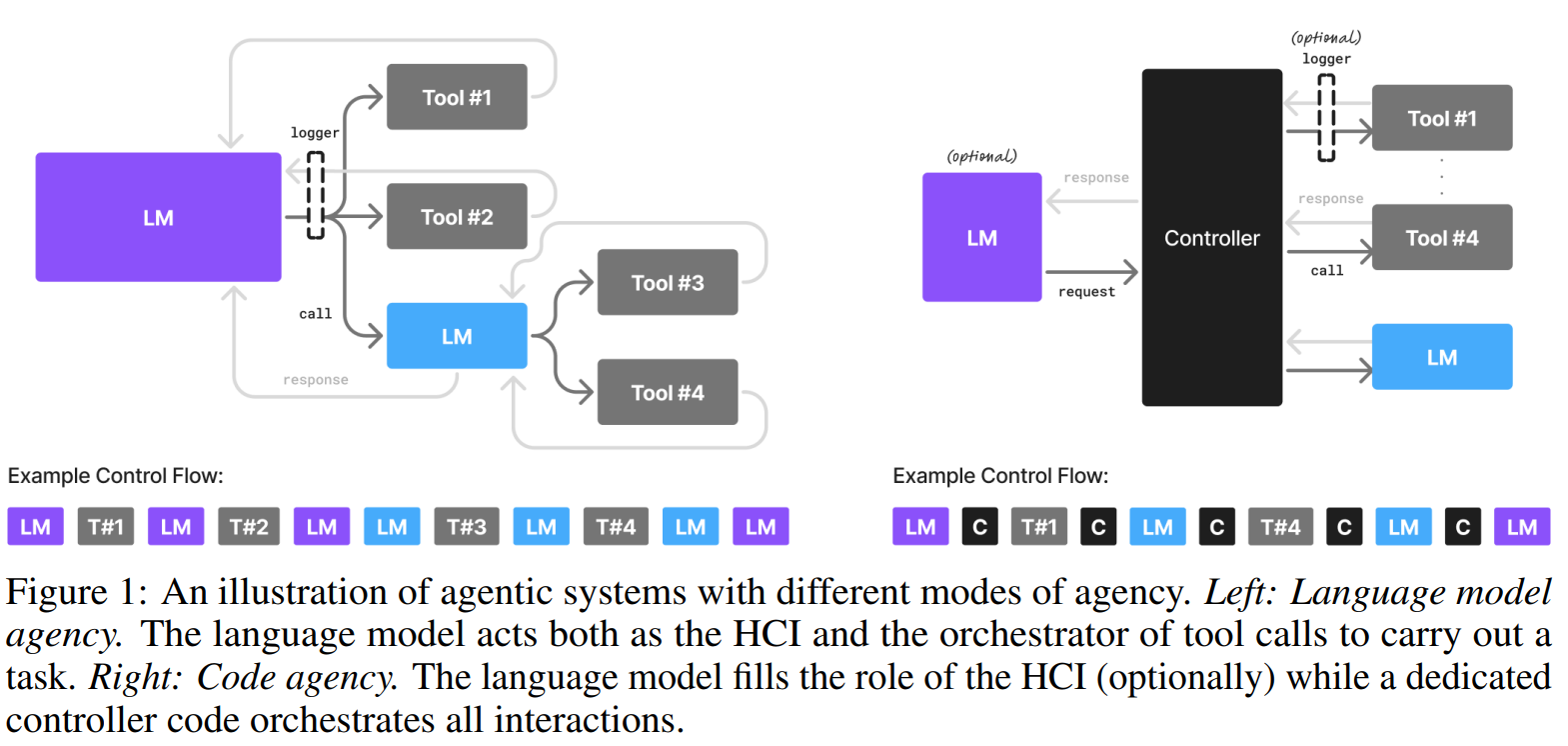
- A6 (이기종 시스템): 에이전트 시스템은 자연스럽게 여러 모델을 사용하는 구조를 허용한다. 논문의 Figure 1은 언어 모델이 다른 언어 모델을 도구로 호출하거나, 컨트롤러가 여러 특화된 SLM(대화용, 작업용 등)을 호출하는 이기종 아키텍처를 보여준다.
-
알고리즘 (LLM-to-SLM 에이전트 변환 알고리즘): 기존 LLM 기반 에이전트를 SLM 기반으로 전환하기 위한 6단계 알고리즘을 제안한다.
- S1. 사용 데이터 수집: 에이전트의 모든 내부 모델 호출(입력 프롬프트, 출력 응답 등)을 로깅한다.
- S2. 데이터 큐레이션 및 필터링: 수집된 데이터에서 민감 정보를 제거하고 정제한다.
- S3. 작업 클러스터링: 수집된 데이터를 클러스터링하여 반복되는 요청 패턴을 식별하고 SLM 전문화 대상을 정의한다.
- S4. SLM 선택: 각 작업에 맞는 후보 SLM을 성능, 라이선스, 배포 요구사항 등을 고려하여 선택한다.
- S5. 전문 SLM 미세조정: PEFT나 지식 증류 같은 기술을 사용하여 선택된 SLM을 해당 작업 데이터로 미세조정한다.
- S6. 반복 및 개선: 새로운 데이터를 사용하여 주기적으로 SLM을 재훈련하여 성능을 유지하고 개선한다.
실험 결과
이 논문은 자체적인 실험 대신, SLM의 능력을 입증하는 기존 연구 결과와 사례 연구를 제시한다.
-
주요 데이터셋: 특정 데이터셋을 사용한 실험은 없으나, 주장의 근거로 다양한 SLM 모델들의 벤치마크 성능을 인용한다.
-
핵심 성능 지표:
- Microsoft Phi-3 small (7B): 언어 이해 및 상식 추론에서 동시대 70B 모델과 동등한 성능을 보였다.
- NVIDIA Nemotron-H family (9B): 추론 FLOPs가 훨씬 적음에도 불구하고 30B LLM과 유사한 명령어 준수 및 코드 생성 정확도를 달성했다.
- Salesforce xLAM-2-8B: 8B 크기에도 불구하고 GPT-4o 및 Claude 3.5와 같은 최신 모델을 능가하는 도구 호출(tool calling) 성능을 보였다.
- DeepSeek-R1-Distill-Qwen-7B: Claude-3.5-Sonnet, GPT-4o-0513과 같은 대형 독점 모델보다 뛰어난 상식 추론 능력을 보여주었다.
-
비교 결과 (사례 연구): 부록 B에서 세 가지 유명 오픈소스 에이전트에 대해 LLM 호출을 SLM으로 대체할 수 있는 잠재력을 분석했다.
- MetaGPT: 약 60%의 LLM 쿼리를 특화된 SLM으로 대체 가능하다고 추정했다.
- Open Operator: 약 40%의 LLM 쿼리를 대체 가능하다고 추정했다.
- Cradle: 약 70%의 LLM 쿼리를 대체 가능하다고 추정했다.
결론
에이전트 AI 산업은 혁신적인 변화를 약속하고 있으며, 비용 절감이나 AI 인프라의 지속가능성 개선은 이러한 변화의 촉매제가 될 것이다. 저자들은 LLM 중심의 현재 패러다임에서 벗어나, 성능, 경제성, 유연성 등 여러 장점을 가진 SLM을 적극적으로 채택하는 것이 에이전트 AI의 자연스럽고 필연적인 미래라고 주장한다. 이 논문은 이러한 전환을 촉진하기 위한 논의를 활성화하고, AI 자원의 효과적인 사용과 비용 절감 노력을 발전시키고자 한다.
부록 B
B LLM-to-SLM Replacement Case Studies
This appendix assesses the potential extent of replacing large language model invocations with small language models in three popular open-source agents: MetaGPT, Open Operator, and Cradle. Each case study examines the use of LLMs, evaluates where SLMs may be viable replacements, and concludes with an estimated percentage of replaceable queries.
B.1 Case study 1: MetaGPT
Name.
MetaGPT
License.
Apache 2.0
Purpose.
MetaGPT is a multi-agent framework designed to emulate a software company. It assigns roles such as Product Manager, Architect, Engineer, and QA Engineer to collaboratively handle tasks including requirement drafting, system design, implementation, and testing.
LLM Invocations.
- Role-Based Actions. Each agent role invokes LLMs to fulfill its specialized responsibilities (e.g., coding, documentation).
- Prompt Templates. Structured prompts used for consistent outputs.
- Dynamic Intelligence. Used for planning, reasoning, and adaptation.
- Retrieval-Augmented Generation (RAG). Retrieves relevant documents to enhance generation.
Assessment for SLM Replacement.
SLMs would be well-suited for routine code generation and boilerplate tasks, as well as for producing structured responses based on predefined templates. However, they would require further fine-tuning data to reliably perform more complex tasks, such as architectural reasoning and adaptive planning or debugging, which would initially benefit from the broader contextual understanding and the generality of LLMs.
Conclusion.
In the case of MetaGPT, we estimate that about 60% of its LLM queries could be reliably handled by appropriately specialized SLMs.
B.2 Case study 2: Open Operator
Name.
Open Operator
License.
MIT License
Purpose.
Open Operator is a workflow automation agent enabling users to define behaviours of agents that can perform tasks like API calls, monitoring, and orchestration using tools and services.
LLM Invocations.
- Natural Language Processing. Parses user intent.
- Decision Making. Guides execution flow.
- Content Generation. Writes summaries, reports.
Assessment for SLM Replacement.
SLMs would be well-suited for tasks such as simple command parsing and routing, as well as generating messages based on predefined templates. They could be meeting their limitations when dealing with more complex tasks that would require multi-step reasoning or the ability to maintain conversation flow and context over time—areas where LLMs would continue to offer significant advantages.
Conclusion.
In the case of Open Operator, we estimate that about 40% of its LLM queries could be reliably handled by appropriately specialized SLMs.
B.3 Case study 3: Cradle
Name.
Cradle
License.
MIT License
Purpose.
Cradle is designed for General Computer Control (GCC), enabling agents to operate GUI applications via screenshot input and simulated user interaction.
LLM Invocations.
- Interface Interpretation. Understands visual context.
- Task Execution Planning. Determines sequences of GUI actions.
- Error Handling. Diagnoses and reacts to unexpected software states.
Assessment for SLM Replacement.
SLMs would be well-suited for handling repetitive GUI interaction workflows and the execution of pre-learned click sequences. However, they would face challenges when it comes to tasks involving dynamic GUI adaptation or unstructured error resolution, which would require a higher degree of contextual understanding typically provided by LLMs.
Conclusion.
In the case of Cradle, we estimate that about 70% of its LLM queries could be reliably handled by appropriately specialized SLMs.