Mamba: Linear-Time Sequence Modeling with Selective State Spaces
논문 정보
- 제목: Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- 저자: Albert Gu (Carnegie Mellon University), Tri Dao (Princeton University)
- 학회/저널: arXiv
- 발행일: 2024-05-31
- DOI: 10.48550/arXiv.2312.00752
- 주요 연구 내용: 기존 상태 공간 모델(SSM)의 한계인 내용 기반 추론(content-based reasoning) 능력 부재를 해결하기 위해, 모델의 파라미터가 입력에 따라 동적으로 변하는 '선택 메커니즘'을 도입함. 이로 인해 비효율적으로 변하는 계산 문제를 해결하기 위해 GPU 메모리 계층 구조를 활용한 하드웨어 친화적인 병렬 스캔 알고리즘을 설계함.
- 주요 결과 및 결론: Mamba는 시퀀스 길이에 대해 선형적으로 확장되며, Transformer 대비 5배 높은 추론 처리량을 보임. 언어, 음성, 유전체 등 다양한 모달리티에서 기존 SOTA 모델 및 Transformer의 성능을 능가했으며, 특히 언어 모델링에서는 동일 크기의 Transformer를 압도하고 2배 큰 모델과 대등한 성능을 달성함.
- 기여점: 첫째, SSM에 입력 의존적인 선택 메커니즘을 도입하여 시퀀스 내 정보를 선택적으로 처리하는 능력을 부여함. 둘째, 이 선택적 SSM을 효율적으로 계산하기 위한 하드웨어 인식 병렬 알고리즘을 개발함. 셋째, 어텐션과 MLP 블록 없이 선택적 SSM을 통합한 단순하고 효율적인 Mamba 아키텍처를 제안함.
요약
초록
현재 딥러닝의 핵심인 파운데이션 모델은 대부분 Transformer 아키텍처에 기반하지만, 긴 시퀀스에 대한 계산 비효율성 문제를 가진다. 이를 해결하기 위해 선형 시간 복잡도를 갖는 여러 모델(선형 어텐션, SSM 등)이 제안되었으나 언어와 같은 주요 모달리티에서 Transformer만큼의 성능을 내지 못했다. 이 연구는 기존 모델들의 핵심 약점이 '내용 기반 추론 능력의 부재'라고 진단하고, SSM의 파라미터를 입력의 함수로 만들어 모델이 토큰에 따라 정보를 선택적으로 전파하거나 잊도록 개선한다. 이로 인해 기존의 효율적인 컨볼루션 연산을 사용할 수 없게 되지만, 하드웨어 친화적인 병렬 알고리즘(scan)을 통해 효율성을 유지했다. 이 선택적 SSM을 어텐션이나 MLP 블록 없이 통합한 Mamba 아키텍처는 Transformer 대비 5배 빠른 추론 속도와 선형적 확장성을 보이며, 언어, 음성, 유전체 등 여러 모달리티에서 SOTA 성능을 달성했다.
서론
파운데이션 모델의 근간은 시퀀스 모델이며, 그중에서도 Transformer가 지배적인 위치를 차지하고 있다. Transformer의 어텐션 메커니즘은 컨텍스트 내 정보를 밀도 높게 처리하여 복잡한 데이터 모델링에 효과적이지만, 유한한 컨텍스트 윈도우와 윈도우 길이에 대한 이차적 계산량 증가()라는 근본적인 한계를 가진다. 기존의 구조적 상태 공간 모델(SSM)은 선형 또는 준선형 시간으로 확장이 가능해 긴 시퀀스 모델링에 유망했지만, 텍스트와 같이 정보 밀도가 높은 데이터에서는 성능이 저조했다. 본 연구는 이러한 SSM의 한계를 극복하고 Transformer의 성능과 SSM의 효율성을 결합한 새로운 아키텍처를 제안하고자 한다.
배경
구조적 상태 공간 모델(SSM)은 RNN과 CNN의 특징을 결합한 시퀀스 모델로, 연속적인 시스템 , 에서 영감을 받았다. 이 모델은 이산화(discretization) 과정을 거쳐 이산 파라미터 를 얻고, 이를 통해 두 가지 방식으로 계산될 수 있다.
- 순환(Recurrent) 모드: ,
- 컨볼루션(Convolutional) 모드: 기존 SSM의 핵심 특징은 선형 시불변(Linear Time Invariance, LTI) 성질이다. 즉, 파라미터가 모든 타임스텝에 걸쳐 고정되어 있어, 효율적인 병렬 학습을 위해 컨볼루션 모드를 사용할 수 있다. 하지만 이 LTI 특성은 모델이 입력 내용에 따라 동적으로 상태를 변화시키지 못하게 만들어, 내용 기반 추론이 중요한 작업에서의 성능 한계로 작용한다.
모델 아키텍처 / 방법론
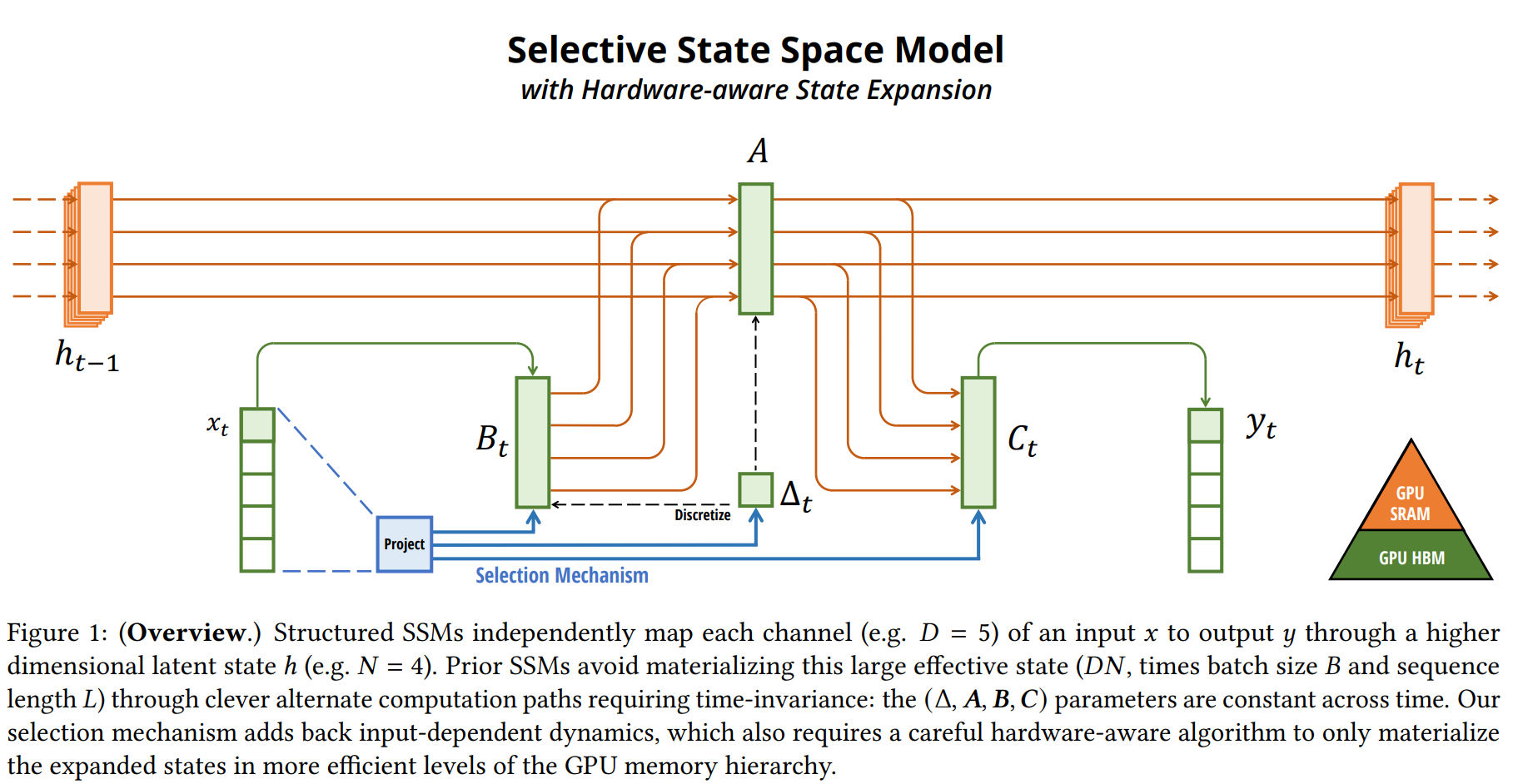
-
핵심 구조/방법: 선택적 SSM (Selective SSM) Mamba의 핵심은 LTI 제약을 제거하여 SSM이 내용(content)에 따라 정보를 선택적으로 처리하게 만든 것이다. 이는 SSM의 주요 파라미터인 를 입력 의 함수로 만들어 동적으로 변화시키는 '선택 메커니즘'을 통해 구현된다. 이로 인해 모델은 시불변(time-invariant)이 아닌 시변(time-varying)이 되어, 컨볼루션으로 계산할 수 없게 된다. 이 문제를 해결하기 위해, 확장된 상태를 GPU의 느린 HBM에 저장하지 않고 빠른 SRAM 내에서 순환 계산을 수행하는 하드웨어 친화적 병렬 스캔 알고리즘을 사용한다. 이는 커널 퓨전, 병렬 스캔, 재계산 기법을 활용하여 효율성을 극대화한다. 논문의 Figure 1은 이러한 선택적 SSM의 전체적인 구조를 보여준다.
-
주요 구성 요소:
- 선택 메커니즘(Selection Mechanism): 파라미터가 입력 에 따라 결정되어, 시퀀스를 따라 정보의 흐름을 조절한다. 예를 들어, 특정 토큰을 무시해야 할 때 모델은 게이트를 닫는 것처럼 상태 전이를 조절할 수 있다.
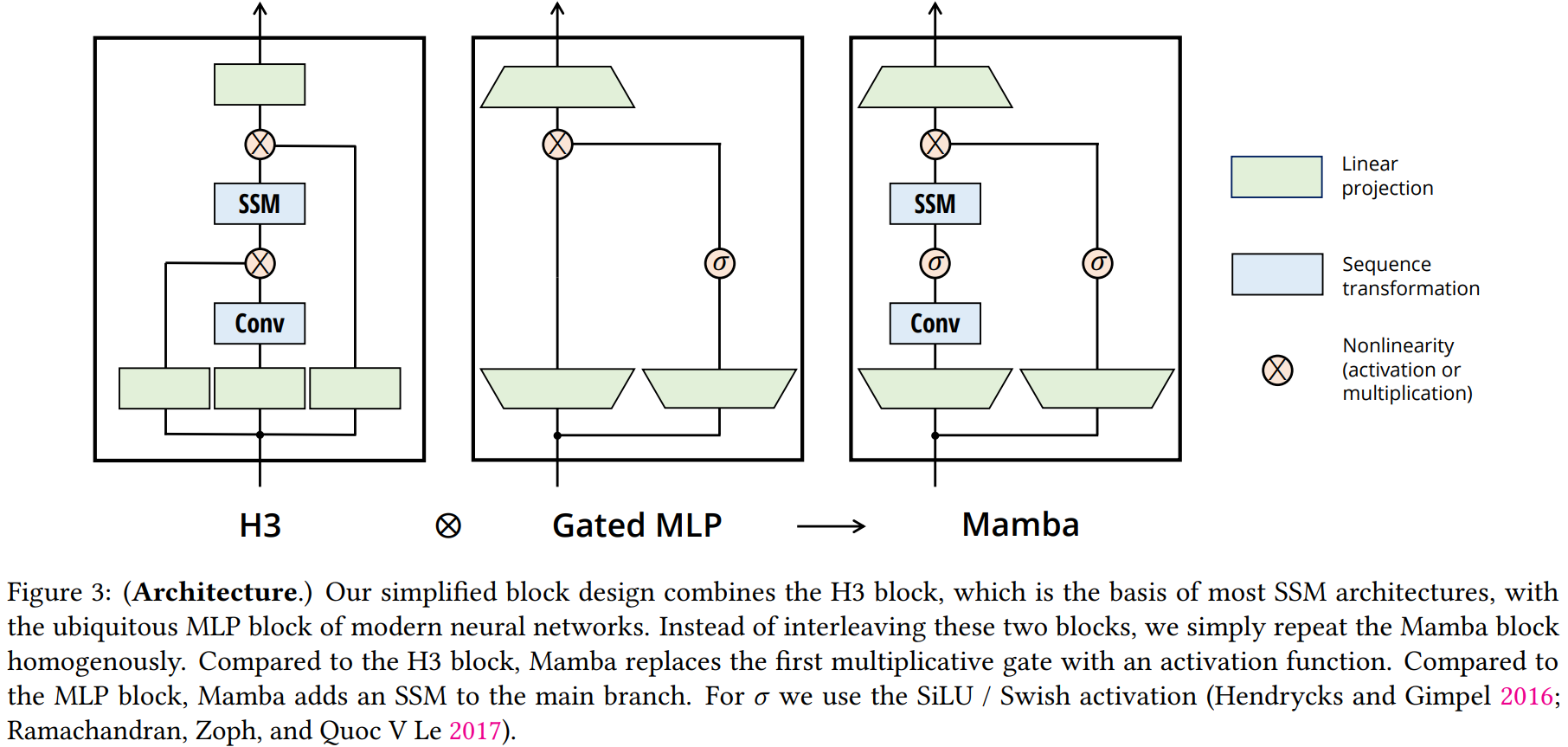
- Mamba 아키텍처: 기존 H3 블록과 MLP 블록을 하나로 결합한 단순화된 'Mamba 블록'을 반복적으로 쌓는 동종(homogenous) 구조를 가진다. 이는 어텐션 메커니즘 없이 구성되며, SwiGLU 활성화 함수를 포함한다. 논문의 Figure 3에서 H3, Gated MLP와 Mamba 블록의 구조를 비교하여 보여준다.
- 선택 메커니즘(Selection Mechanism): 파라미터가 입력 에 따라 결정되어, 시퀀스를 따라 정보의 흐름을 조절한다. 예를 들어, 특정 토큰을 무시해야 할 때 모델은 게이트를 닫는 것처럼 상태 전이를 조절할 수 있다.
-
수식: 선택 메커니즘을 통해 SSM의 이산 파라미터는 각 타임스텝 마다 달라진다: . 특히 파라미터 의 선택성은 RNN의 게이팅 메커니즘과 깊은 관련이 있다. 특정 조건 하에서() 선택적 SSM은 고전적인 RNN 게이트 형태인 와 동일해진다(단, ).
실험 결과
- 주요 데이터셋: 언어 모델링(The Pile), 유전체 서열 모델링(HG38), 음성 파형 모델링(YouTubeMix, SC09), 그리고 모델의 핵심 능력을 검증하기 위한 합성 데이터셋(Selective Copying, Induction Heads)을 사용한다.
- 핵심 성능 지표:
- 합성 데이터셋: Mamba는 기존 LTI 모델들이 실패하는 Selective Copying과 Induction Heads 과제를 완벽하게 해결했으며, 훈련 시보다 4000배 이상 긴 백만 토큰 길이의 시퀀스에서도 성능 저하 없이 일반화하는 능력을 보인다.
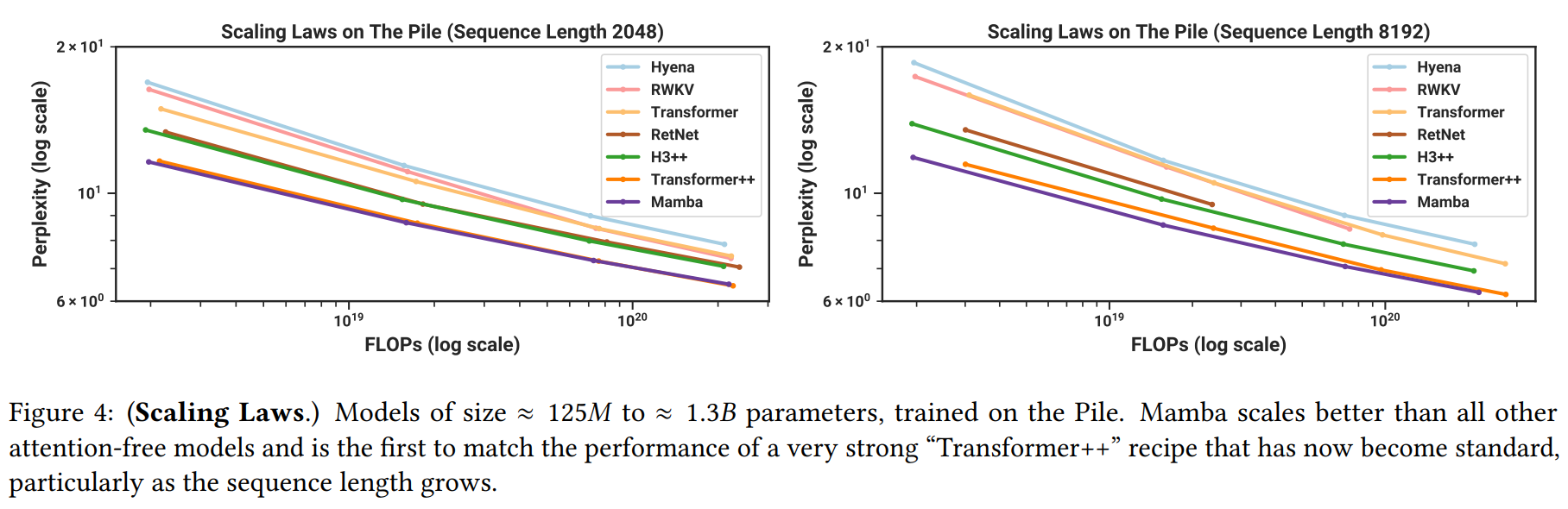
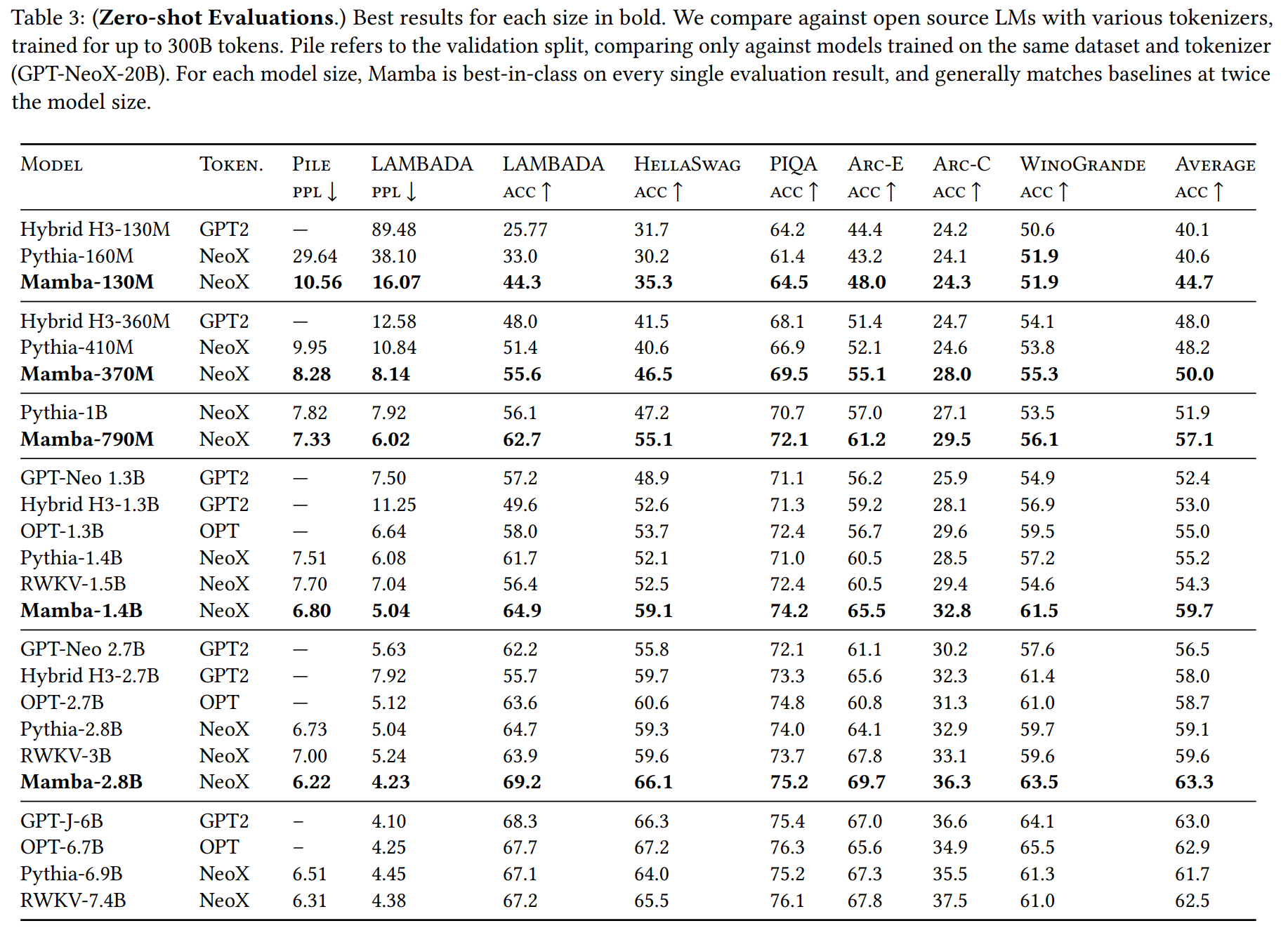
- 언어 모델링: The Pile 데이터셋에 대한 스케일링 법칙 실험(Figure 4)에서 Mamba는 강력한 Transformer++ 베이스라인과 대등한 성능을 보였고, 다른 모든 선형 시간 모델을 능가한다. 제로샷 평가(Table 3)에서는 Mamba-2.8B 모델이 Pythia-6.9B와 같은 두 배 큰 모델과 유사하거나 더 나은 성능을 기록했다.
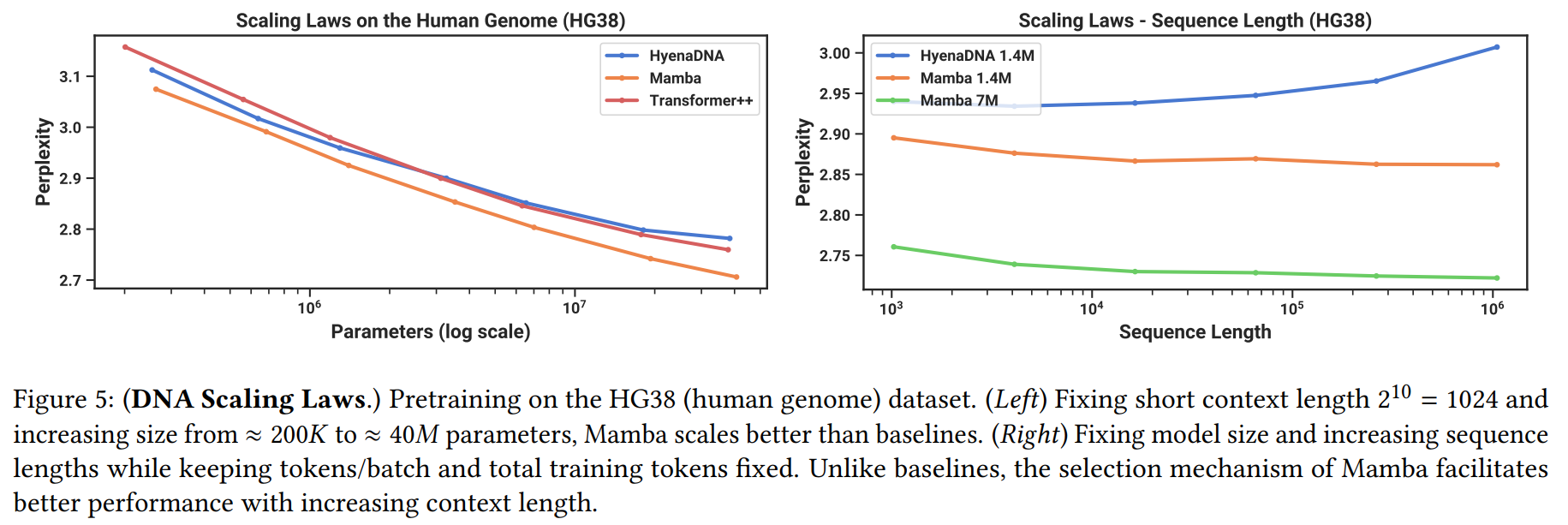
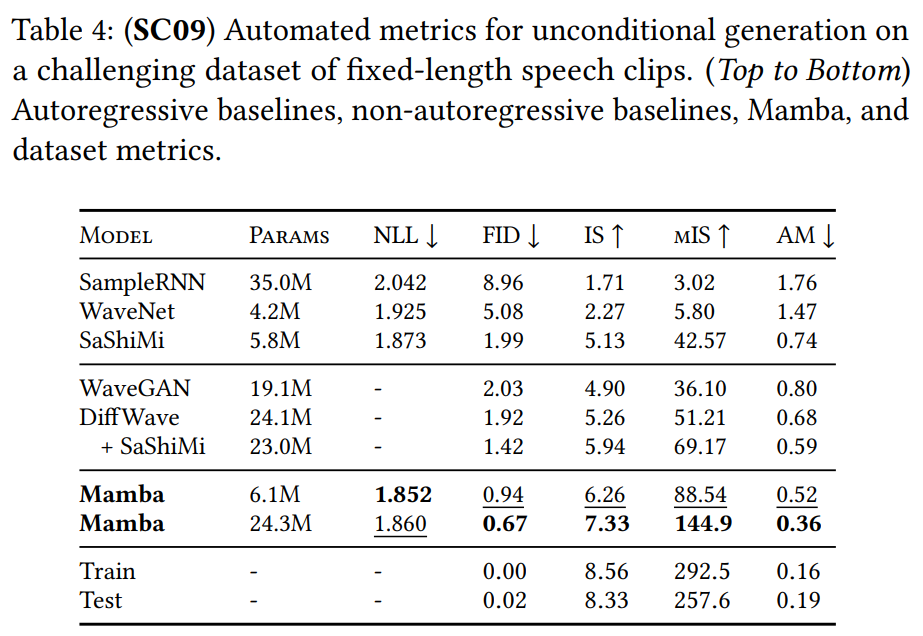
- 유전체 및 음성: DNA 모델링에서 Mamba는 더 긴 컨텍스트(최대 1M)를 효과적으로 활용하여 성능이 향상된 반면, 비교 모델인 HyenaDNA는 성능이 저하되었다(Figure 5). 음성 생성에서는 기존 SOTA 모델인 SaShiMi를 능가했으며, 생성 품질(FID)을 절반 이상 감소시켰다(Table 4).
- 합성 데이터셋: Mamba는 기존 LTI 모델들이 실패하는 Selective Copying과 Induction Heads 과제를 완벽하게 해결했으며, 훈련 시보다 4000배 이상 긴 백만 토큰 길이의 시퀀스에서도 성능 저하 없이 일반화하는 능력을 보인다.
- 비교 결과:
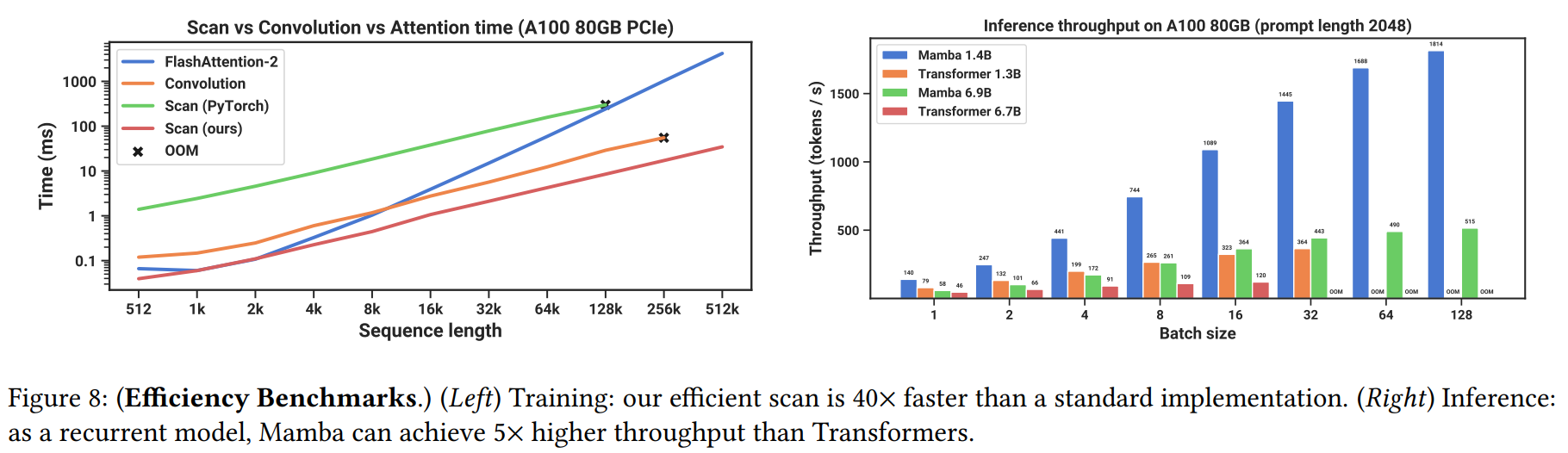
- 효율성: KV 캐시가 없어 추론 시 Transformer보다 4~5배 높은 처리량을 달성했다. Mamba의 핵심 연산인 선택적 스캔은 2K 이상의 시퀀스 길이에서 FlashAttention-2보다 빠르며, 메모리 사용량은 최적화된 Transformer와 유사하다(Figure 8).
- 성능: 전반적으로 Mamba는 Transformer의 성능에 필적하거나 이를 뛰어넘으면서도 선형 시간 복잡도의 효율성을 가진다.
결론
이 연구는 SSM에 '선택 메커니즘'을 도입하여 내용 기반 추론 능력을 부여하고, 이를 효율적으로 구현하는 하드웨어 친화적 알고리즘을 제안했다. 이를 바탕으로 설계된 Mamba 아키텍처는 어텐션 없이도 다양한 모달리티에서 Transformer를 능가하는 성능을 보이며, 특히 긴 컨텍스트를 다루는 데 강점을 가졌다. 이러한 결과들은 Mamba가 긴 시퀀스 모델링이 필요한 여러 도메인에서 효과적인 파운데이션 모델의 백본이 될 수 있는 강력한 후보임을 시사한다.