섬유의 변퇴색 기준 판정 내광성 등급 기반 이상치 처리 기법
논문 정보
- 제목: 섬유의 변퇴색 기준 판정 내광성 등급 기반 이상치 처리 기법 (Outlier Processing Techniques Based on Colorfastness Rating Determination Based on Change in Color of Textile)
- 저자: 이대규, 서강복, 김덕엽, 이우진 (경북대학교 IT대학 컴퓨터학부)
- 학회/저널: 2023 한국컴퓨터종합학술대회
- 발행일: 2023-06-21
- DOI: 제공되지 않음
- 주요 연구 내용: 본 연구는 섬유 염색 공정 데이터에서 내광성 등급 예측 모델의 성능을 향상시키기 위한 이상치 처리 기법을 제안함. 제안된 기법은 기기으로 측정한 변퇴색() 기반의 내광성 등급과 현장에서 수집된 내광성 등급을 비교해 두 등급 간의 차이가 특정 임계값을 초과하는 데이터를 이상치로 간주하고 제거하는 방식임.
- 주요 결과 및 결론: 수집된 내광성 등급과 변퇴색 기준 등급 간의 차이가 1.5를 초과하는 데이터를 이상치로 제거했을 때, 예측 모델의 정확도가 0.94953으로 가장 높게 나타남. 이는 원본 데이터(0.86301)나 일반적인 이상치 처리 기법(Z-score: 0.91359, IQR: 0.87477)을 적용했을 때보다 우수한 성능임.
- 기여점: 노동집약적인 섬유 산업 분야의 데이터가 갖는 비정규 분포 특성을 고려한 도메인 특화 이상치 처리 기법을 제안함. 이를 통해 데이터의 신뢰성을 높이고 머신러닝 모델의 예측 정확도를 향상시켜, 제품 생산 효율성 증대에 기여할 수 있는 실용적인 방법론을 제시함.
요약
초록
섬유 산업에서 AI 활용이 증가하고 있지만, 노동집약적 특성상 체계적인 데이터 관리가 어려워 이상치가 자주 포함된다. 데이터 내 이상치는 예측 모델의 성능을 저하시키므로 효과적인 처리가 필수적이다. 이 논문은 변퇴색 기준 판정 등급과 실제 수집된 내광성 등급을 비교하여 이상치를 식별하고 제거하는 기법을 제안하며, 이 기법이 예측 모델의 성능을 개선함을 보인다.
서론
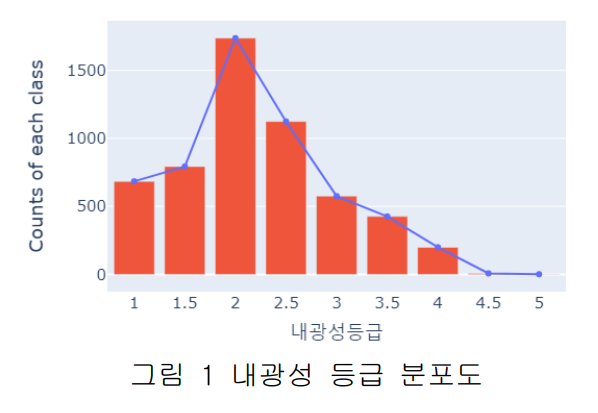 섬유 염색 공정과 같이 복잡한 변수를 가진 노동집약적 산업에서는 체계적인 데이터 수집이 어려워 데이터에 이상치가 포함될 가능성이 높다. 특히, 내광성 등급 데이터는 정규분포를 따르지 않는 경우가 많아(논문의 Figure 1 참조) Z-score나 IQR 같은 일반적인 이상치 처리 기법으로는 효과적인 처리가 어렵다. 따라서 데이터의 특성을 고려한 도메인 특화 이상치 처리 기법이 필요하며, 본 연구는 변퇴색 기준을 활용한 새로운 방식을 제안한다.
섬유 염색 공정과 같이 복잡한 변수를 가진 노동집약적 산업에서는 체계적인 데이터 수집이 어려워 데이터에 이상치가 포함될 가능성이 높다. 특히, 내광성 등급 데이터는 정규분포를 따르지 않는 경우가 많아(논문의 Figure 1 참조) Z-score나 IQR 같은 일반적인 이상치 처리 기법으로는 효과적인 처리가 어렵다. 따라서 데이터의 특성을 고려한 도메인 특화 이상치 처리 기법이 필요하며, 본 연구는 변퇴색 기준을 활용한 새로운 방식을 제안한다.
모델 아키텍처 / 방법론
-
핵심 구조/방법: 제안된 기법의 핵심은 두 가지 종류의 내광성 등급을 비교하는 것이다. 첫째는 염색 공정에서 실제로 수집된 내광성 등급이고, 둘째는 시험편의 내광성 측정 전후 색상 차이를 계측하여 표준에 따라 계산된 '변퇴색 기준 내광성 등급'이다. 이 두 등급 간의 차이를 계산하고, 이 차이가 특정 임계값을 넘는 데이터를 '이상치'로 규정하여 데이터셋에서 제거한다.
-
주요 구성 요소:
- 염색 공정 데이터: 총 5,546개의 데이터 샘플을 사용했으며, 각 샘플은 392개의 공정 변수와 1개의 내광성 등급으로 구성된다. 이 중 단일 값을 갖는 변수를 제외하고 내광성에 직접적인 영향을 미치는 조제, 염료, 온도 등 40개의 주요 변수를 분석에 사용했다.
- 변퇴색() 기반 등급: 시험편의 측정 전후 색상을 CIELAB 색 공간에서 측정하여 변퇴색 값을 계산하고, 이를 기반으로 내광성 등급을 판정한다.
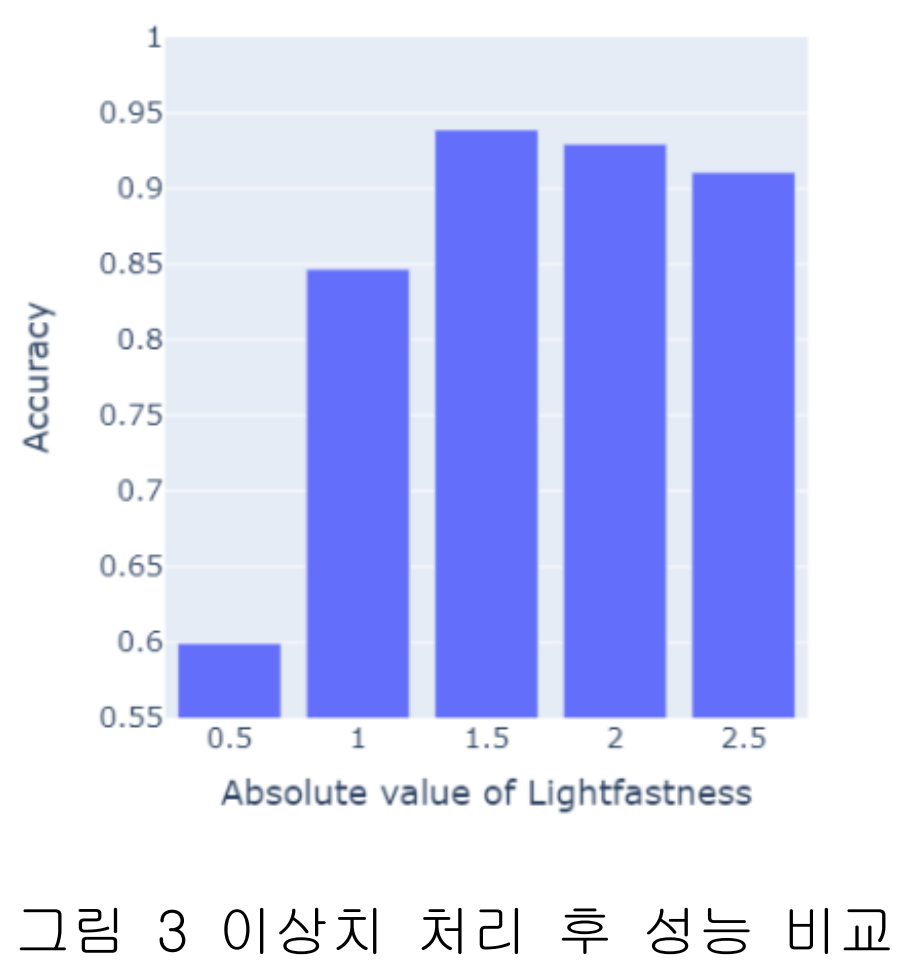
- 이상치 제거 기준: 수집된 등급과 변퇴색 기준 등급 간 차이의 절댓값을 기준으로 실험을 진행했다. 그 결과, 차이가 1.5를 초과하는 데이터를 제거했을 때 모델 성능이 가장 높았다.

-
수식: 변퇴색 는 내광성 등급 판정의 핵심 지표로, 논문의 Figure 2에 제시된 복잡한 계산을 통해 구해진다. 핵심이 되는 최종 색차 계산식은 다음과 같다.
-
알고리즘:
- 모든 데이터에 대해 변퇴색 계산식을 이용하여 '변퇴색 기준 내광성 등급'을 산출한다.
- 기존에 수집된 내광성 등급과 변퇴색 기준 등급 간의 차이(절댓값)를 계산한다.
- 등급 간 차이를 임계값(0.5, 1.0, 1.5, 2.0, 2.5)으로 설정하여 데이터를 필터링하고, 각 데이터셋으로 AutoML 모델(AutoGluon)을 학습시킨다.
- 성능 비교 결과(논문의 Figure 3), 임계값이 1.5일 때 정확도가 가장 높게 나타나, 이를 최종 이상치 제거 기준으로 확정한다.
실험 결과
- 주요 데이터셋: 섬유 염색 가공 공정에서 수집된 5,546개의 데이터를 사용했으며, 8:2 비율로 학습 및 테스트 데이터로 분할했다.
- 핵심 성능 지표: 모델의 예측 정확도(Accuracy)를 성능 지표로 사용했다. 제안된 기법(등급 차이 1.5 초과 데이터 제거)을 적용했을 때 정확도는 0.94953으로 가장 높은 성능을 기록했다.
- 비교 결과: 제안된 기법의 성능을 여러 기준과 비교한 결과(논문의 Table 3 참조)는 다음과 같다.
- 수집된 원본 데이터: 0.86301
- 변퇴색 기준 데이터: 0.83273
- Z-score 기법 적용: 0.91359
- IQR 기법 적용: 0.87477
- 제안 기법 (차이 > 1.5 제거): 0.94953 실험 결과, 제안된 도메인 특화 기법이 일반적인 통계 기반 이상치 제거 기법보다 월등히 높은 성능을 보였다.
결론
본 연구는 변퇴색 기준 등급과 실제 수집 등급 간의 차이를 활용하여 섬유 내광성 예측 데이터의 이상치를 효과적으로 제거하는 기법을 제안했다. 등급 간 차이가 1.5를 초과하는 데이터를 제거했을 때 예측 모델의 성능이 가장 크게 향상됨을 실험적으로 입증했다. 이 기법은 섬유 산업뿐만 아니라, 시각적 판정에 의존하는 다른 노동집약적 산업에서 머신러닝 모델의 정확도를 높여 생산 효율성을 개선하는 데 기여할 수 있을 것으로 기대된다.