차분 테스트를 이용한 내광성 등급 예측 모델 성능 향상
논문 정보
- 제목: Performance Improvement of Lightfastness Grade Prediction Model using Differential Testing
- 저자: 이대규, 서강복, 김덕엽, 이우진 (경북대학교 컴퓨터학부)
- 학회/저널: 2024 한국컴퓨터종합학술대회 논문집
- 발행일: 2024-06-26
- DOI: 제공되지 않음
- 주요 연구 내용: 산업 현장의 요구사항을 반영한 내광성 등급 예측 모델의 성능 저하 문제를 해결하기 위해 차분 테스트 기법을 응용한 데이터 정제 방법을 제안함. 다수의 머신러닝 모델(LSTM, RF-MLP, AutoML)을 학습시킨 후, 일정 기준 이상의 정확도를 보이는 모델들 중 과반수가 예측에 실패한 데이터를 이상치로 간주하여 제거하고, 정제된 데이터로 모델을 재학습시켜 성능을 향상시킴.
- 주요 결과 및 결론: 제안된 기법을 적용한 결과, AutoML 모델은 1%, RF-MLP 앙상블 모델은 3%, LSTM 모델은 10%의 성능 향상을 보여 평균 4.6%의 정확도 상승을 확인함. 특히 LSTM 모델에서 예측 실패율이 높았던 데이터가 주로 제거되었는데, 이는 염색 공정의 순서상 발생한 데이터 오기입일 가능성이 높으며, 이를 이상치로 판단하여 제거한 것이 성능 향상의 주요 원인으로 분석됨.
- 기여점: 데이터의 양이 부족하고 신뢰성이 낮은 산업 데이터 환경에서 모델의 성능을 향상시키기 위한 실용적인 접근법을 제시함. 여러 모델의 예측 결과를 교차 검증하는 차분 테스트의 아이디어를 활용하여 학습을 저해하는 이상치를 효과적으로 식별하고 제거함으로써, 추가 데이터 확보 없이 예측 정확도를 높이는 방법을 제안함.
요약
초록
기존 내광성 예측 모델은 산업 현장에서 필요한 염료 및 조제 정보를 활용하지 않고, 주로 ANN(Artificial Neural Network) 기반으로 개발되어 특정 조건에서 성능이 저하되는 한계가 있었다. 본 연구에서는 이러한 문제를 해결하기 위해 차분 테스트 개념을 도입하여 모델 성능을 개선하는 기법을 제안한다. 다수의 모델을 학습시킨 뒤, 특정 정확도 기준을 넘는 모델들을 대상으로 과반수 이상이 예측하지 못한 데이터를 이상치로 판단하여 학습 데이터에서 제외한다. 이후 정제된 데이터로 모델을 재학습시켜 각 모델의 예측 성능이 유의미하게 향상되는 것을 확인했다.
서론
섬유 산업에서는 품질 향상을 위해 머신러닝 도입을 시도하고 있으나, 체계적인 데이터 수집 시스템의 부재로 데이터의 양이 부족하고 정확하지 않은 경우가 많다. 특히 내광성 등급은 육안 판정으로 인해 주관적 오류가 포함될 수 있어 예측 모델의 성능을 저하시키는 요인이 된다. 데이터 증강이나 일반적인 이상치 제거 기법은 데이터가 부족한 환경에 적용하기 어렵다. 이러한 한계를 극복하기 위해, 본 연구에서는 차분 테스트 기법을 응용하여 제한된 데이터 내에서 학습을 저해하는 요소를 제거함으로써 모델 성능을 향상시키는 방법을 제안한다.
배경
기존 내광성 예측 연구는 주로 ANN을 사용했으나, 광원 노출 시간과 색상 파장 기반 예측은 실제 산업 현장에서 요구하는 염료 및 조제 투입량에 대한 정보를 제공하지 못했다. 특정 염료에 한정된 연구도 있었지만 범용성이 부족했다. 일반적인 다중 분류 모델 성능 향상 기법들은 데이터의 양이 충분하고 객관적인 판단 기준이 필요하지만, 내광성 데이터는 이러한 조건을 충족하지 못하는 경우가 많다. 한편, 소프트웨어 공학의 차분 테스트는 여러 라이브러리 간의 동작 차이를 비교하여 결함을 찾는 연구에 활용되는데, 본 연구는 이 아이디어를 모델 학습 데이터 정제에 적용했다.
모델 아키텍처 / 방법론
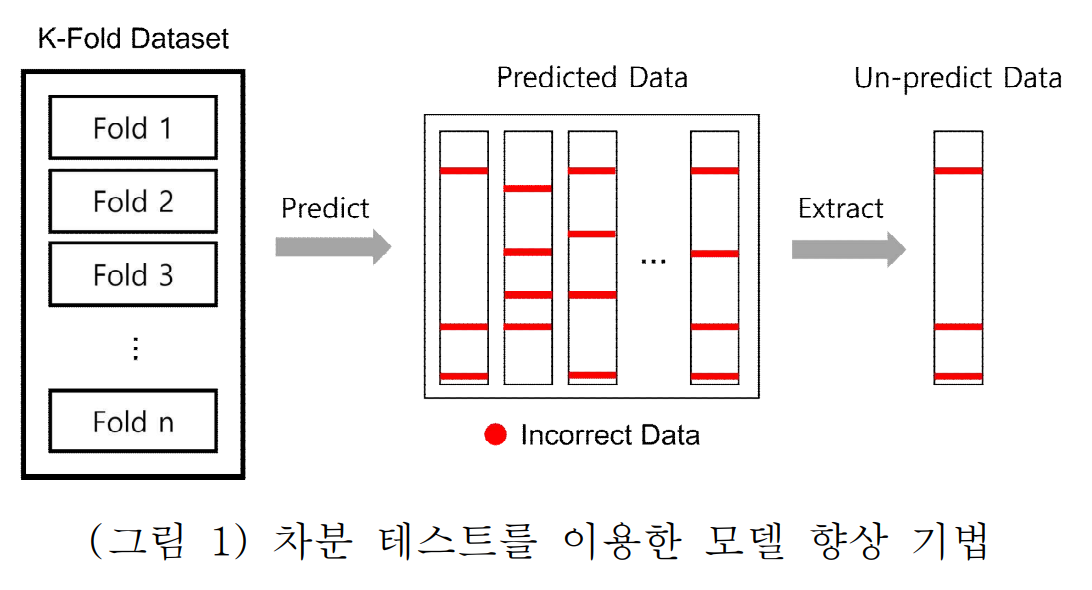
- 핵심 구조/방법: 제안하는 기법은 논문의 Figure 1에 도식화되어 있으며, 다음과 같은 절차로 진행된다.
- 전체 데이터를 K-Fold로 분할하여 교차 검증을 준비한다.
- LSTM, RF-MLP 앙상블, AutoML 세 가지 모델을 학습시킨다.
- 일정 수준 이상의 예측 정확도를 보이는 모델들을 선별한다.
- 선별된 모델들 중 과반수가 예측에 실패한 데이터를 '학습 저해 데이터(Un-predict Data)'로 식별한다.
- 이 데이터를 원본 데이터셋에서 제거한다.
- 정제된 데이터셋으로 각 모델을 다시 학습시켜 최종 모델을 얻는다.
- 주요 구성 요소:
- LSTM: 시계열 특성을 가진 염색 공정 데이터를 처리하기 위해 사용.
- RF-MLP 앙상블: Random Forest와 Multi-Layer Perceptron을 Voting 방식으로 결합한 모델.
- AutoML: AutoGluon 라이브러리를 사용하여 최적의 모델을 자동으로 탐색.
- 알고리즘: 본 연구의 핵심은 차분 테스트의 원리를 이용하여 다수 모델이 공통적으로 오분류하는 데이터를 이상치로 규정하고 제거하는 것이다. 이는 단일 모델의 편향에서 벗어나, 데이터 자체의 문제점을 식별하려는 시도이다.
실험 결과
- 주요 데이터셋: 총 9,254개의 섬유 염색 가공 공정 데이터를 사용했다. 데이터는 소재 정보, Lab/Pilot 가공 공정, 측정 결과로 구성되며, 초기 392개의 변수 중 단일 값을 갖는 변수 등을 제외하고 내광성에 직접적인 영향을 미치는 염료, 조제, 온도 등 46개의 주요 변수를 최종적으로 사용했다.
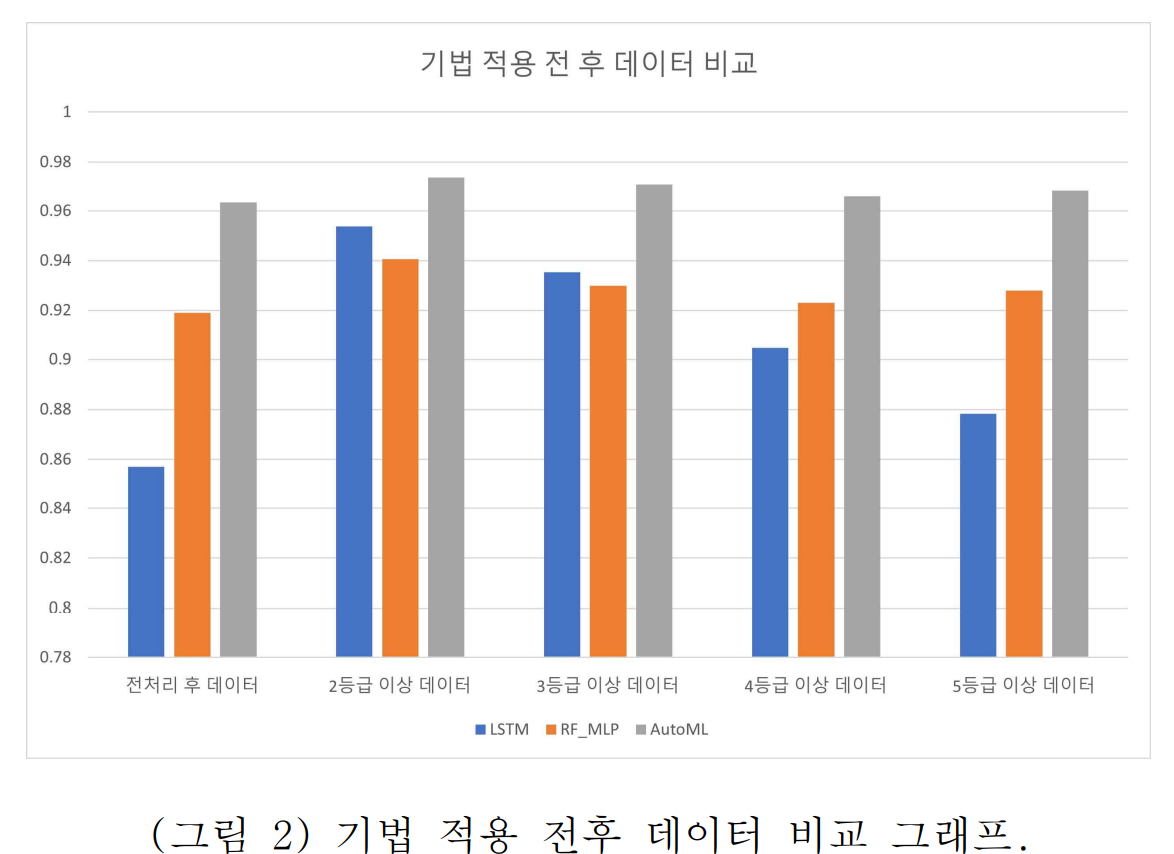
- 핵심 성능 지표: 기법 적용 전후의 예측 정확도 변화를 통해 성능 향상을 측정했다. 논문의 Figure 2 그래프는 기법 적용 후 모든 모델의 성능이 전반적으로 향상되었음을 보여준다.
- 비교 결과: 기법 적용 후, AutoML은 1%, RF-MLP 앙상블은 3%, LSTM은 10%의 성능 향상을 기록하여, 평균 4.6%의 정확도가 상승했다. 제거된 데이터는 주로 LSTM 모델이 예측에 실패한 데이터였으며, 이는 시간에 따라 순차적으로 진행되는 염색 공정 데이터가 잘못 기입되었을 가능성을 시사한다. 이러한 데이터 이상치를 제거함으로써 각 모델의 성능을 효과적으로 개선할 수 있었다.
결론
본 연구는 차분 테스트 기법을 응용하여 내광성 등급 예측 모델의 성능을 향상시키는 방법을 제안하고 그 유효성을 입증했다. 과반수의 모델이 예측하지 못하는 데이터를 이상치로 간주하고 제거 후 재학습하는 이 방식은 데이터가 부족하고 노이즈가 많은 산업 현장에서 특히 유용할 것으로 기대된다. 향후 데이터가 충분히 확보된다면, 현재 이상치로 처리된 데이터를 포함하여 재학습함으로써 모델의 전체적인 강건함과 정확도를 더욱 높일 수 있을 것이다.