PAPER2CODE: AUTOMATING CODE GENERATION FROM SCIENTIFIC PAPERS IN MACHINE LEARNING
논문 정보
- 제목: PAPER2CODE: AUTOMATING CODE GENERATION FROM SCIENTIFIC PAPERS IN MACHINE LEARNING
- 저자: Minju Seo (KAIST), Jinheon Baek (KAIST), Seongyun Lee (KAIST), Sung Ju Hwang (KAIST, DeepAuto.ai)
- 학회/저널: arXiv (v4)
- 발행일: 2025-10-10
- DOI: (N/A)
- 주요 연구 내용: 기계 학습(ML) 논문만 입력받아 완전한 코드 리포지토리를 생성하는 멀티 에이전트 LLM 프레임워크 'PaperCoder'를 제안함. PaperCoder는 1) Planning (계획), 2) Analysis (분석), 3) Generation (생성)의 3단계로 작업을 분해하여 인간 개발자의 워크플로우를 모방함.
- 주요 결과 및 결론: PaperCoder는 자체 구축한 Paper2CodeBench 및 공개된 PaperBench 벤치마크에서 ChatDev, MetaGPT 등 기존 코드 생성 방식들을 큰 차이로 능가함. 생성된 코드는 원본 논문 저자의 평가에서도 88%가 최고로 선택되었으며, 92%가 재현에 도움이 된다고 응답함.
- 기여점: ML 논문에서 코드 자동 생성을 위한 체계적인 3단계(계획-분석-생성) 멀티 에이전트 방법론을 제시함. 생성된 코드는 평균 0.81%의 코드 라인만 수정하면 실행 가능한 '거의 실행 가능한(near-executable)' 수준의 높은 품질을 달성하여 ML 연구의 재현성 위기를 해결하는 데 기여함.
요약
초록
기계 학습(ML) 연구는 빠르게 성장하고 있으나, 연구 결과를 재현하거나 이전 작업을 기반으로 구축하는 데 필요한 코드 구현이 종종 누락되어 있어 연구 속도를 저해함. 최근 LLM(Large Language Models)이 과학 문서를 이해하고 고품질 코드를 생성하는 데 뛰어난 능력을 보이면서, 본 연구는 ML 논문을 기능하는 코드 리포지토리로 변환하는 멀티 에이전트 LLM 프레임워크 'PaperCoder'를 제안한다. PaperCoder는 3단계로 작동함: 1) Planning(계획): 높은 수준의 로드맵 구성, 다이어그램을 포함한 시스템 아키텍처 설계, 파일 종속성 식별, 구성 파일 생성. 2) Analysis(분석): 구현에 특화된 세부 사항 해석. 3) Generation(생성): 모듈화되고 종속성을 인식하는 코드를 생성함. 각 단계는 파이프라인 전반에 걸쳐 효과적으로 협력하도록 설계된 전문 에이전트 세트에 의해 실행됨. PaperCoder는 모델 기반 평가와 논문 저자들의 인적 평가를 통해 검증되었으며, 최근 공개된 PaperBench 벤치마크에서도 강력한 성능을 입증하며 고품질의 충실한 구현을 생성하는 효과를 보임.
서론
과학적 진보의 핵심은 '재현성'이지만, ML 분야에서는 이것이 큰 도전 과제로 남아있다. 특히 논문에 코드가 첨부되지 않는 경우가 많아(2024년 기준 상위 ML 학회 평균 19.5%만이 코드 제공), 연구자들은 논문만 보고 코드를 '리버스 엔지니어링'하는 데 막대한 시간을 소모한다. 반면, 최근 LLM은 자연어와 코드를 모두 이해하고 생성하는 데 탁월한 능력을 보이며 과학적 워크플로우를 가속화할 잠재력을 보여주었다. 하지만 기존 연구들은 대부분 기존 코드베이스, 코드 스니펫, 또는 잘 정의된 API에 의존한다. 본 연구는 이러한 사전 코드 없이, 오직 논문 텍스트만으로 충실한 구현을 생성할 수 있는지에 대한 질문에 답하고자 한다.
배경
본 연구는 세 가지 관련 연구 분야를 기반으로 한다:
- 코드를 위한 LLM (Large Language Models for Code): 코드 특화 LLM은 소프트웨어 설계, 개발, 요구사항 도출 등 다양한 엔지니어링 작업에서 강력한 성능을 보여주었다.
- 리포지토리 수준 코딩 (Repository-Level Coding): 초기 연구는 단일 파일의 짧은 코드 스니펫 생성에 집중했지만, 최근에는 ChatDev나 MetaGPT처럼 다중 파일 리포지토리 생성을 목표로 하는 멀티 에이전트 프레임워크가 등장했다.
- LLM 기반 과학 연구 (LLM-Powered Scientific Research): LLM이 아이디어 도출부터 실험 검증까지 과학 연구 전반을 지원하고 있으나, 많은 자동화 연구가 여전히 원본 코드베이스에 의존한다는 한계가 있다.
모델 아키텍처 / 방법론
PaperCoder는 논문(R)을 코드 리포지토리(C)로 매핑하는 함수 를 구현하는 것을 목표로 한다. LLM에 논문 전체를 입력해 한 번에 생성하는() 'Naive' 방식은 논문의 복잡성, 긴 컨텍스트, 파일 간 일관성 유지 문제로 인해 비현실적이다.

대신 PaperCoder는 작업을 3단계로 분해하는 멀티 에이전트 프레임워크를 제안한다 (논문의 Figure 2와 Figure 4에 전체 개요가 시각화되어 있음).
- Planning (계획):
- Analysis (분석):
- Coding (코딩):
1. Planning (계획)
논문의 비정형 텍스트를 구현 가능한 추상화된 구조로 변환하는 단계.
- 1.1 Overall Plan (전체 계획): 논문 전체에서 핵심 컴포넌트(모델, 학습 목표, 데이터 처리, 평가 프로토콜)를 식별하여 고수준 요약을 생성한다.
- 1.2 Architecture Design (아키텍처 설계): 리포지토리의 전체 아키텍처를 정의한다. 파일 목록, 모듈 간의 정적 관계를 보여주는 클래스 다이어그램(Class Diagram), 동적 상호작용을 모델링하는 **시퀀스 다이어그램(Sequence Diagram)**을 생성한다.
- 1.3 Logic Design (로직 설계): 컴포넌트가 '어떻게' 인스턴스화되어야 하는지에 초점을 맞춘다. 특히 파일 간의 의존성을 고려하여, 파일이 구현되고 실행되어야 할 순서를 정의하는 **정렬된 파일 목록(ordered file list)**을 생성한다.
- 1.4 Configuration Generation (구성 생성): 하이퍼파라미터, 모델 설정, 런타임 옵션 등을 포함하는
config.yaml파일을 생성한다.
2. Analysis (분석)
계획 단계에서 정의된 구조를 바탕으로, 각 파일 내부 모듈의 구체적인 구현 세부 사항을 명세화하는 단계. 각 파일()에 대해 기능적 목표, 입출력 동작, 파일 내/외부 의존성, 논문의 알고리즘 사양 등을 포함하는 상세 분석()을 생성한다.
3. Coding (코딩)
모든 이전 단계의 산출물(논문 R, 계획 P, 분석 A)을 기반으로 실제 코드를 생성하는 마지막 단계. 'Logic Design'에서 결정된 실행 순서에 따라 파일을 순차적으로 생성한다. 번째 파일을 생성할 때는 이전에 생성된 코드 파일 을 컨텍스트로 함께 제공하여 리포지토리 전체의 일관성을 보장한다.
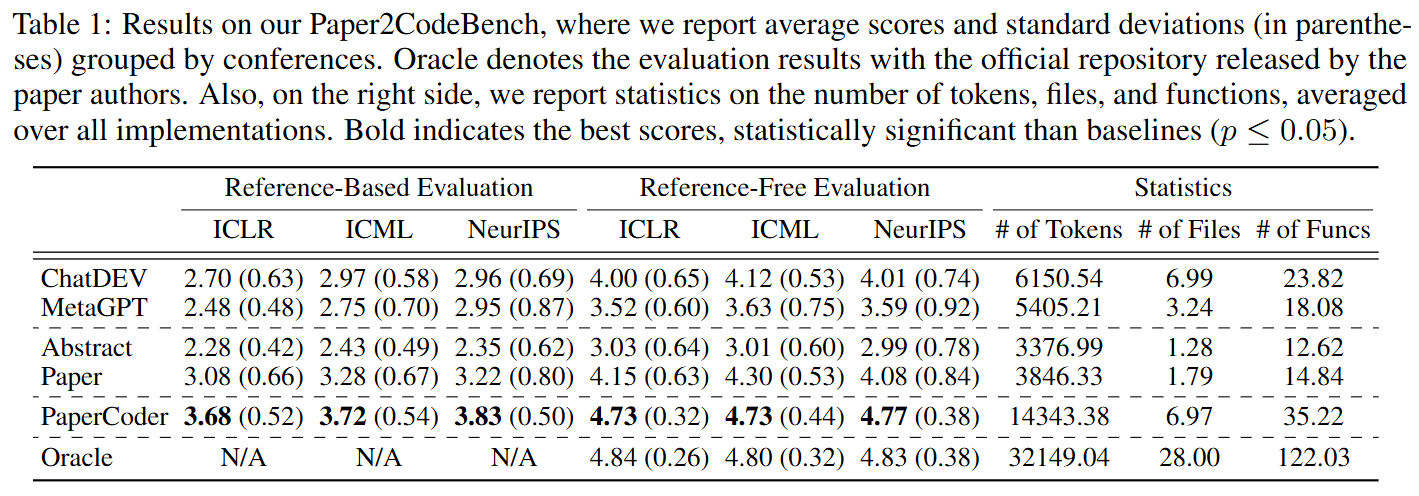
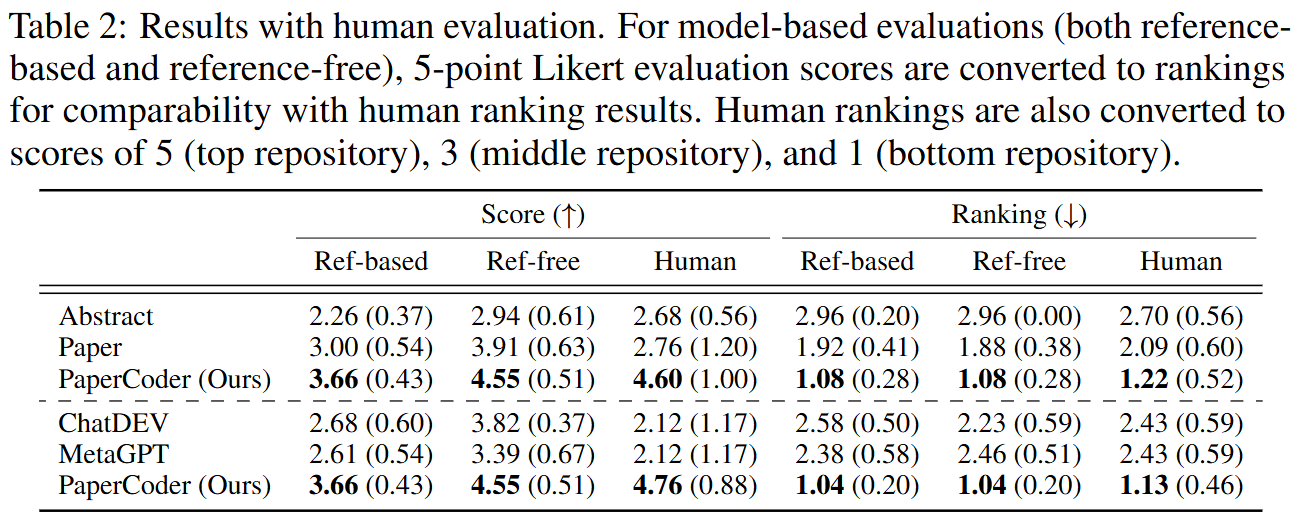
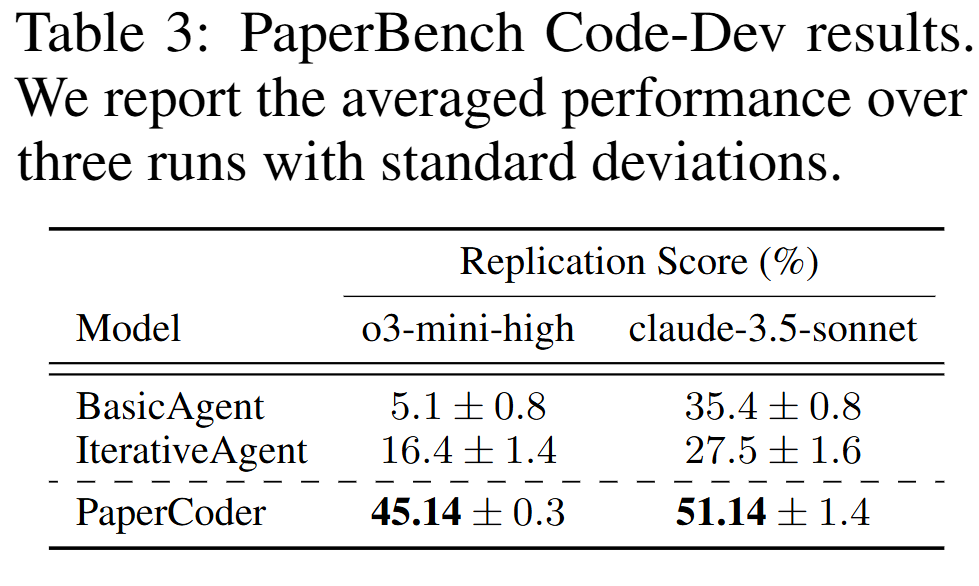



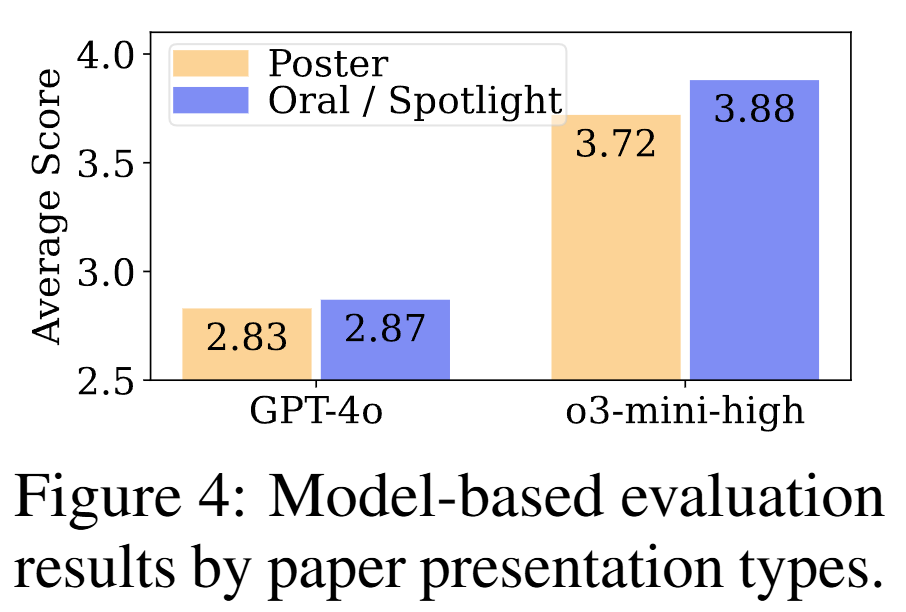
실험 결과
- 데이터셋: 자체 구축한
Paper2CodeBench(ICLR, ICML, NeurIPS 2024 논문 90개) 및 공개 벤치마크PaperBench Code-Dev. - 평가 방식: 1) Reference-Based: 저자 공식 코드를 정답으로 사용. 2) Reference-Free: 공식 코드 없이 논문만으로 평가. (두 방식 모두 LLM-as-judge 활용) 3) Human Evaluation: 원본 논문 저자가 직접 생성된 리포지토리들을 순위 매김.
- 핵심 성능 (Table 1, 3): PaperCoder는 Paper2CodeBench에서 ChatDev, MetaGPT 등 모든 베이스라인의 성능을 압도했다. PaperBench에서도 03-mini-high 모델 기준 45.14%의 복제 점수를 달성, 베이스라인(Iterative Agent, 16.4%) 대비 월등한 성능을 보였다.
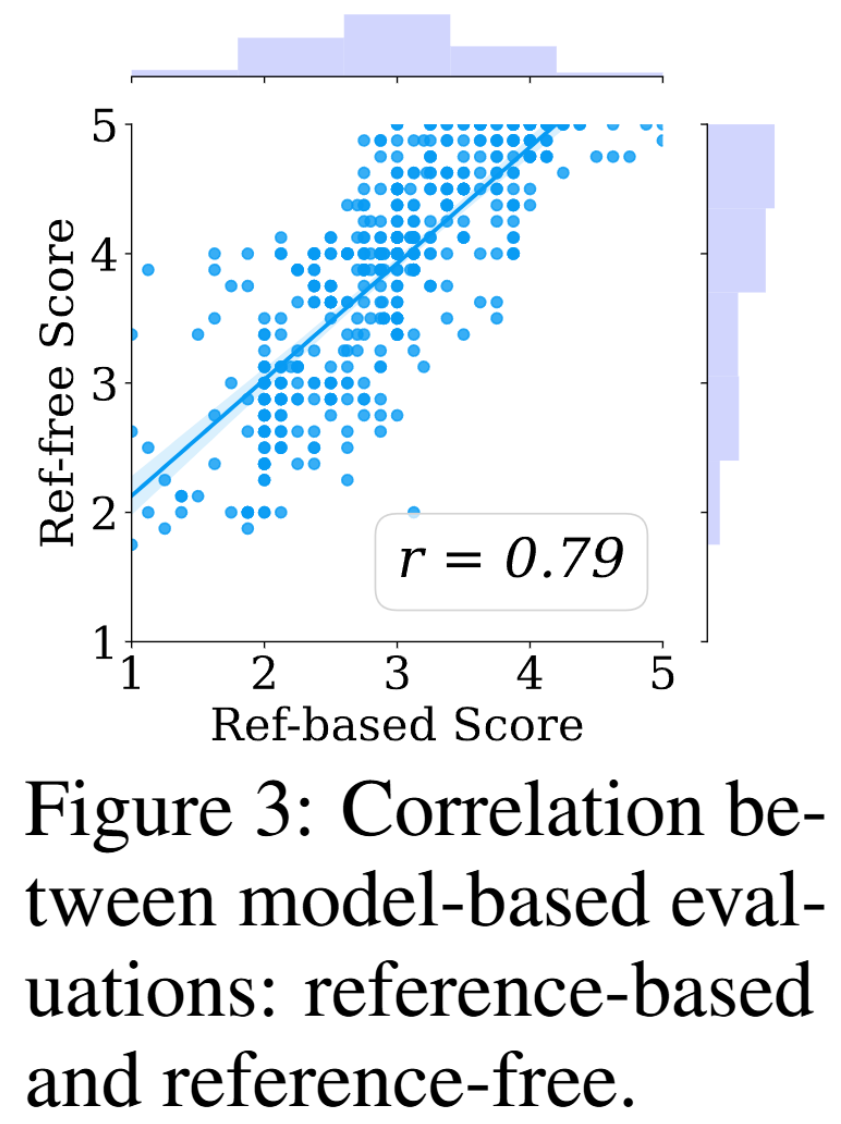
- 평가 신뢰성 (Figure 3, Table 5): Reference-Free 평가 점수와 Reference-Based 평가 점수 간에 강한 양의 상관관계(Pearson )가 나타나, 정답 코드가 없을 때도 LLM-as-judge가 신뢰할 수 있는 프록시 평가자 역할을 함을 입증했다. 또한 모델 기반 평가와 인적 평가 간의 상관관계(e.g., )도 높게 나타났다.
- 인적 평가 (Table 2): PaperCoder가 생성한 리포지토리는 원본 저자들에 의해 88%의 비율로 "최고"로 선택되었으며, 92%의 평가자가 "재현에 도움이 된다"고 응답했다.
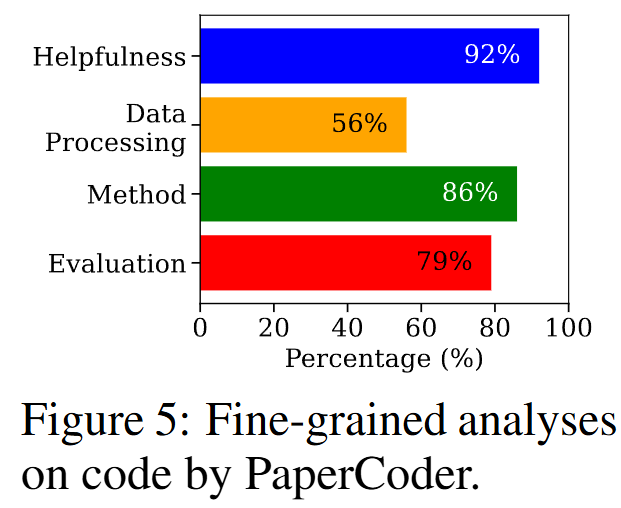
- 컴포넌트별 구현율 (Figure 5): 인적 평가를 통해 생성된 코드의 컴포넌트별 구현율을 분석한 결과, **Method (80%)**와 **Evaluation (79%)**은 구현율이 높았으나, **Data Processing (56%)**이 가장 낮았다. 이는 대부분의 논문이 데이터 전처리, 로딩 절차 등은 상세히 기술하지 않기 때문이다.
- 실행 가능성 분석 (Section 4.3): 생성된 리포지토리는 '거의 실행 가능(near-executable)'한 상태였다. 5개 리포지토리를 수동 디버깅한 결과, **평균 0.81%**의 코드 라인만 수정하면 성공적으로 실행되었다. 수정 내용은 주로 오래된 API 업데이트, 데이터 타입 캐스팅 등 경미한 오류였다 (논문의 Figure 7, 8에 수정 예시가 있음).
결론
본 연구는 ML 논문에서 코드 리포지토리를 자동으로 생성하는 3단계(계획-분석-코딩) 멀티 에이전트 프레임워크 'PaperCoder'를 제안했다. PaperCoder는 Paper2CodeBench와 PaperBench 두 벤치마크에서 기존 접근 방식들을 압도했으며, 특히 생성된 코드는 평균 0.81%의 라인만 수정하면 실행 가능한 높은 실용성을 보였다. 이는 ML 연구의 재현성을 보조하고 과학적 진보를 가속화하는 중요한 단계이다.