Application of Reinforcement Learning to Dyeing Processes for Residual Dye Reduction
논문 정보
- 제목: Application of Reinforcement Learning to Dyeing Processes for Residual Dye Reduction
- 저자: Whan Lee, Seyed Mohammad Mehdi Sajadieh, Hye Kyung Choi, Jisoo Park, Sang Do Noh (Sungkyunkwan University)
- 학회/저널: International Journal of Precision Engineering and Manufacturing-Green Technology
- 발행일: 2024-04-16
- DOI: 10.1007/s40684-024-00627-7
- 주요 연구 내용: 실제 생산 시설에서 수집한 데이터를 활용하여 잔류 염료 배출을 예측하는 Gradient Boosting(GB) 모델과, 잔류 염료를 최소화하기 위한 공정 변수를 추천하는 Q-learning 기반의 강화학습 모델(DPRM)을 개발함.
- 주요 결과 및 결론: 개발된 예측 모델은 값 0.96의 높은 예측 성능을 보였으며, 공정 변수 추천을 통해 평균 66.58%의 잔류 염료 감소를 달성함. 실제 현장 실험을 통해 두 가지 처방에서 각각 42.92%와 76.33%의 잔류 염료 감소 효과를 검증함.
- 기여점: 고가의 추가 장비나 화학물질 없이, 데이터 기반의 강화학습 접근법을 통해 염색 공정의 잔류 염료 발생을 효과적으로 예측하고 줄이는 혁신적인 방법을 제안하여 친환경 공정 운영에 기여함.
요약
초록
제조업에서 지속가능성은 중요한 주제이며, 특히 섬유 염색 및 가공 산업은 막대한 물 소비와 폐수 발생으로 인해 많은 주목을 받고 있다. 본 연구에서는 강화학습 기반 모델을 도입하여 섬유 염색 산업의 폐기물 배출을 예측하고, 이를 최소화하기 위한 염색 공정 변수를 추천한다. 실제 생산 시설 데이터를 기반으로 Gradient Boosting(GB) 폐기물 예측 모델과 Q-learning 기반의 공정 변수 추천 모델을 개발했다. 추천 모델은 값 0.96의 높은 예측 성능을 보였으며, 공정 구성 추천을 통해 평균 66.58%의 잔류 염료 감소를 달성했다. 이러한 결과는 현장 정보 수집과 실험을 통해 검증되었다.
서론
염색 산업은 2030년까지 약 1.2조 세제곱미터의 물을 소비할 것으로 예상되며, 이는 전 세계 폐수의 최대 20%를 차지할 수 있다. 이 폐수에는 잔류 염료, 화학 물질 등이 포함되어 심각한 수질 오염을 유발한다. 기존의 잔류 염료 제거 기술들은 높은 비용과 관리의 어려움 등 한계가 있다. 염색 공정 변수를 최적화하는 것은 추가 장비 없이 비용 및 시간 효율적으로 잔류 염료를 줄일 수 있는 방법이지만, 공정 표준화 수준이 낮고 변수 간 관계가 복잡하여 최적화가 어렵다. 본 연구는 이러한 문제를 해결하기 위해 강화학습(RL)을 이용한 공정 최적화 모델을 제안하여 친환경 염색 공정을 구현하고자 한다.
배경
본 연구는 강화학습(RL), 특히 Q-learning(QL)과 예측 모델로 Gradient Boosting(GB)을 활용한다.
- Q-learning: 상태 전이 확률을 직접 고려하지 않고 최적의 행동을 결정하는 강화학습 알고리즘. 특정 상태에서 특정 행동을 했을 때 얻을 가치를 예측하는 Q 함수를 학습하며, 업데이트 수식은 다음과 같다.
- Gradient Boosting: 여러 개의 약한 학습기(주로 트리 모델)를 통합하여 강력한 예측 모델을 만드는 앙상블 기법. 이전 모델의 오차를 보완하는 방식으로 순차적으로 모델을 추가하여 예측 성능을 향상시킨다.
- 잔류 염료 측정: 잔류 염료의 양과 색상 강도를 나타내는 K/S 값은 Kubelka-Munk 방정식을 통해 계산된다. 여기서 는 특정 파장()에서의 반사율을 의미한다.
모델 아키텍처 / 방법론
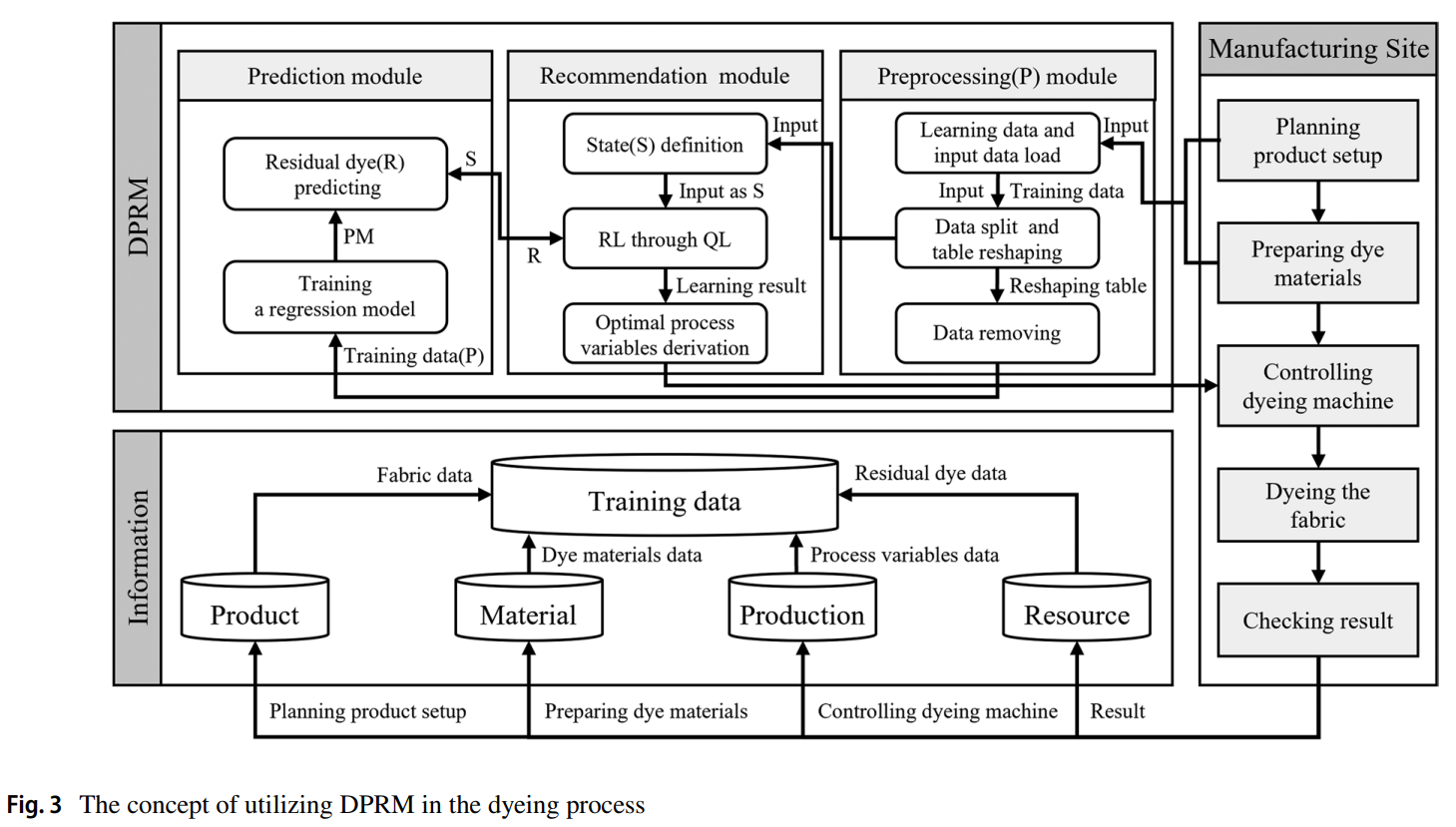 본 연구에서 제안하는 **염색 공정 추천 모델(Dyeing Process Recommendation Model, DPRM)**은 친환경 공정 운영을 위해 잔류 염료를 최소화하는 것을 목표로 한다. 논문의 Figure 3에서 제시된 모델 구조는 세 가지 핵심 모듈로 구성된다.
본 연구에서 제안하는 **염색 공정 추천 모델(Dyeing Process Recommendation Model, DPRM)**은 친환경 공정 운영을 위해 잔류 염료를 최소화하는 것을 목표로 한다. 논문의 Figure 3에서 제시된 모델 구조는 세 가지 핵심 모듈로 구성된다.
-
핵심 구조/방법:
- 전처리 모듈(Preprocessing Module): 공장 운영 중 수집된 원시 데이터를 데이터 분할, 테이블 재구성, 이상치 및 중복 데이터 제거 등의 과정을 거쳐 모델 학습에 적합한 형태로 변환한다.
- 예측 모듈(Prediction Module, PM): 전처리된 데이터를 기반으로 Gradient Boosting(GB) 알고리즘을 사용하여 특정 공정 변수 설정에 따른 잔류 염료(K/S 값)를 예측한다.
- 추천 모듈(Recommendation Module, RM): Q-learning 알고리즘을 사용하여 예측 모듈(PM)이 예측한 잔류 염료 값을 보상(Reward)으로 활용하여, 잔류 염료를 최소화하는 최적의 염색 공정 변수 조합을 도출한다.
-
주요 구성 요소 (MDP 정의):
- State(상태): 염료 혼합 변수와 조정 가능한 염색 공정 변수들의 집합.
- Action(행동): 설정된 범위 내에서 특정 공정 변수 값을 무작위로 변경하는 것.
- Reward(보상): 예측된 잔류 염료(R)를 기반으로
1 - R로 정의. 보상을 최대화하는 것이 목표.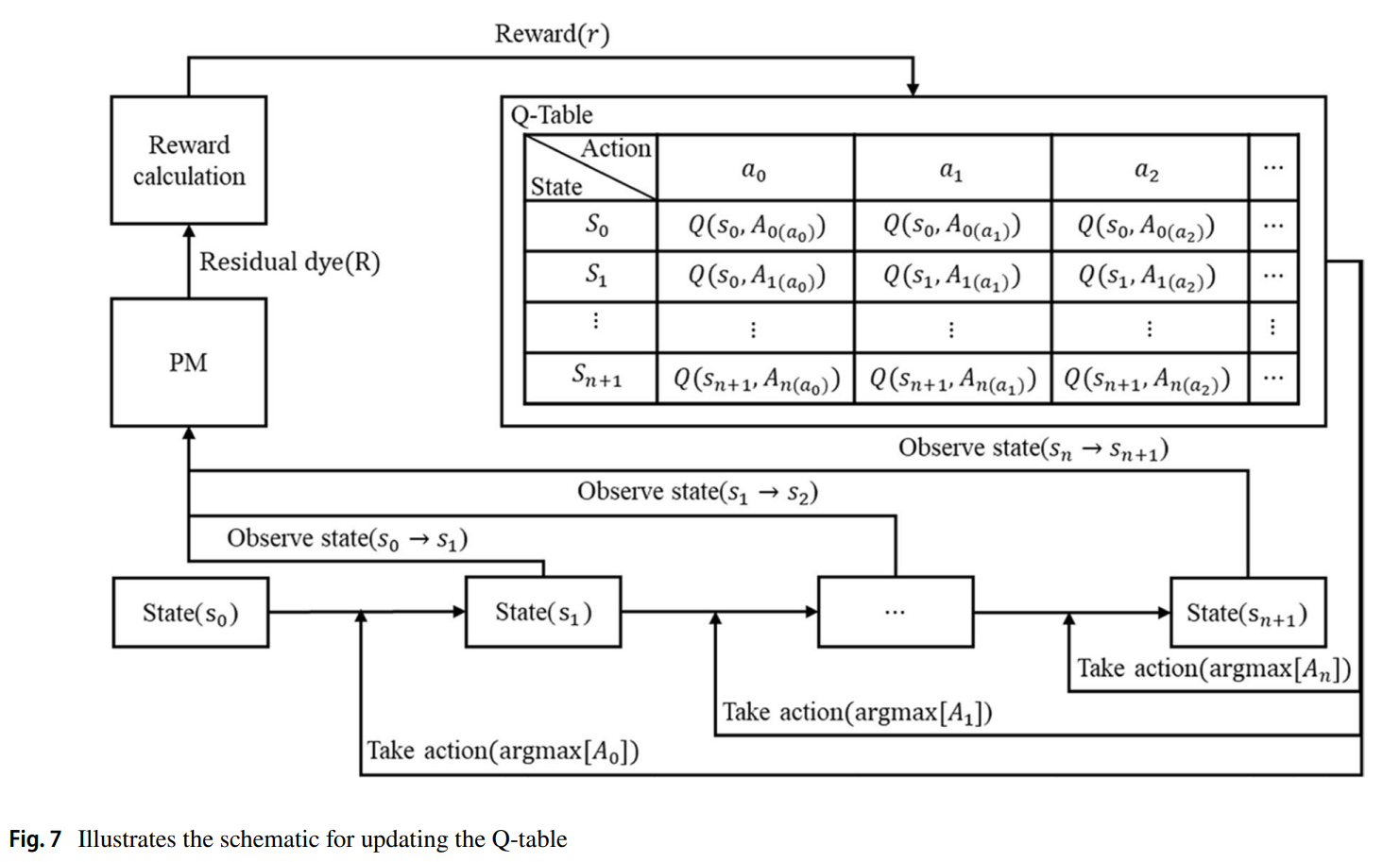
-
알고리즘: 추천 모듈(RM)은 탐험(Exploration)과 활용(Exploitation)의 균형을 맞추기 위해 엡실론-그리디(ε-greedy) 정책을 사용하여 행동을 선택한다. 여러 에피소드에 걸쳐 상태-행동 쌍에 대한 Q-값을 Q-Table에 저장하고 업데이트하며 최적의 정책을 학습한다. 이 과정은 논문의 Figure 7에 도식화되어 있다.
실험 결과
- 주요 데이터셋: 실제 염색 공장에서 3,170건의 데이터를 수집했으며, 전처리 후 1,324개의 학습 데이터셋을 구축했다. 학습 데이터와 테스트 데이터는 8:2 비율로 분할했다.
- 핵심 성능 지표:
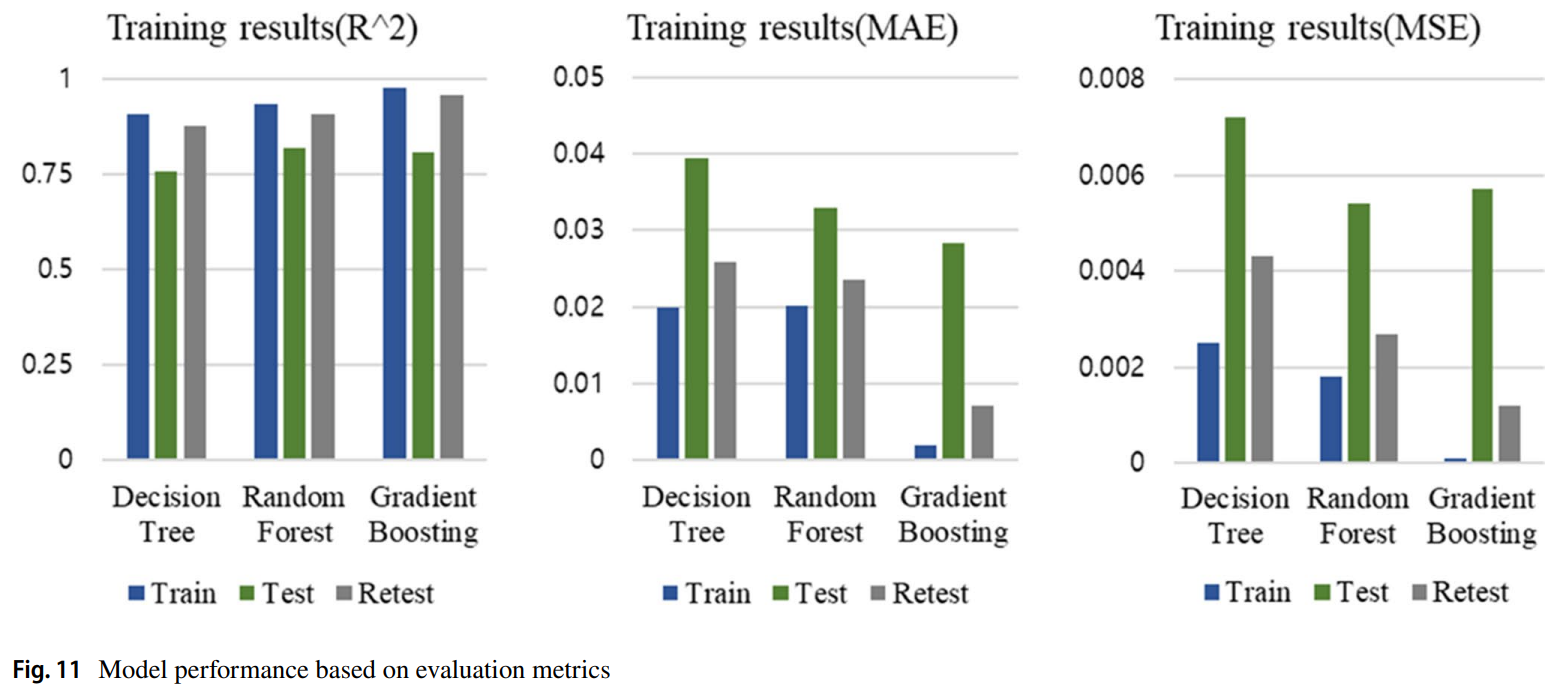
- 예측 모델(PM): 과적합 문제 해결 후 추가 실험을 통해 재평가한 결과, Gradient Boosting 모델은 테스트 데이터에 대해 , , ****의 우수한 성능을 보였다. 이는 논문의 Table 8과 Figure 11에서 다른 모델(Decision Tree, Random Forest)과의 비교를 통해 확인할 수 있다.
- 추천 모델(RM): 124개의 염색 처방에 DPRM을 적용한 결과, 기존 공정 대비 **평균 66.58%**의 잔류 염료 감소가 예측되었다. 최대 감소율은 87.25%, 최소 감소율은 7.27%로 나타났다.
- 비교 결과 (실증): 124개 처방 중 2개를 무작위로 선택하여 실제 염색 실험을 진행했다.
- 처방 52번: 기존 0.6955(K/S) → 실제 결과 0.3970(K/S) (42.92% 감소)
- 처방 105번: 기존 0.2999(K/S) → 실제 결과 0.0710(K/S) (76.33% 감소) 이 결과는 DPRM의 예측 및 추천 성능의 실효성을 입증한다.
결론
본 연구는 GB 예측 모델과 Q-learning 추천 모델을 결합한 DPRM을 성공적으로 개발하여, 염색 공정에서 발생하는 잔류 염료를 최소화하는 효과적인 방법을 제시했다. 시뮬레이션과 실제 실험 모두에서 높은 예측 정확도와 상당한 잔류 염료 감소 효과를 확인했다. 그러나 124개 중 2개의 처방에 대해서만 실증을 진행하여 모델의 일반화에는 한계가 있으며, 추천된 공정 변수가 잔류 염료는 줄이는 반면 평균 21.64%의 에너지 사용량을 증가시키는 문제가 발견되었다. 향후 연구에서는 더 많은 데이터를 확보하여 예측 모델의 신뢰도를 높이고, 잔류 염료와 에너지 소비를 동시에 고려하는 다중 목표 최적화 모델을 개발하여 지속 가능한 염색 공정 운영을 실현해야 할 것이다.