Exploring the Competency of ChatGPT in Solving Competitive Programming Challenges
논문 정보
- 제목: Exploring the Competency of ChatGPT in Solving Competitive Programming Challenges
- 저자: Md. Eusha Kadir, Tasnim Rahman, Sourav Barman, Md. Al-Amin (Institute of Information Technology, Noakhali Science and Technology University, Noakhali, Bangladesh)
- 학회/저널: International Journal of Advanced Trends in Computer Science and Engineering
- 발행일: 2024-02-06
- DOI: 10.30534/ijatcse/2024/031312024
- 주요 연구 내용: 본 연구는 300개의 경쟁적 프로그래밍 문제를 'Easy', 'Medium', 'Hard' 세 가지 난이도로 나누어 ChatGPT의 문제 해결 능력을 평가함. LeetCode 플랫폼의 문제들을 활용했으며, 프롬프트 엔지니어링을 적용하여 생성된 코드의 정확성을 온라인 저지 시스템을 통해 측정함.
- 주요 결과 및 결론: ChatGPT는 전체 문제에 대해 66.00%의 정답률(acceptance rate)을 기록하여, 평균적인 인간 사용자의 52.95%를 상회하는 성능을 보임. 난이도별 정답률은 Easy 89.00%, Medium 68.00%, Hard 41.00%로, 문제의 복잡도가 증가할수록 성능이 저하되는 경향을 보임.
- 기여점: ChatGPT의 경쟁적 프로그래밍 문제 해결 능력을 인간과 비교하여 체계적으로 평가한 초기 연구 중 하나임. 효과적인 코드 생성을 위한 프롬프트 엔지니어링의 중요성을 입증하고, 복잡한 문제 해결에서 나타나는 AI의 한계점을 명확히 제시함.
요약
초록
ChatGPT는 다양한 분야에서 주목받는 AI 기반 언어 처리 도구로, 딥러닝 기술을 사용하여 인간과 유사한 응답을 생성한다. 이 연구는 ChatGPT가 경쟁적 프로그래밍 문제를 해결하는 데 있어 얼마나 성숙했는지를 평가하는 것을 목표로 한다. Easy, Medium, Hard 난이도로 구성된 300개의 문제를 사용하여 ChatGPT의 성능을 측정한 결과, 각각 89.00%, 68.00%, 41.00%의 정답률을 기록했다. 전체적으로 ChatGPT는 66.00%의 정답률을 달성하여 평균적인 인간 참가자의 52.95%보다 우수한 결과를 보였다. 이는 ChatGPT가 평균적인 인간보다 경쟁적 프로그래밍 작업에서 더 나은 성능을 보임을 시사한다.
서론
인공지능(AI) 기술, 특히 ChatGPT와 같은 대규모 언어 모델(LLM)은 코드 생성, 버그 수정 등 소프트웨어 엔지니어링 분야에서 잠재력을 보여주고 있다. 경쟁적 프로그래밍은 단순한 코딩 능력을 넘어 비판적 사고와 알고리즘 설계 능력을 요구하는 복합적인 작업이다. 본 연구는 이러한 경쟁적 프로그래밍 문제 해결 능력을 척도로 삼아 ChatGPT의 실질적인 성능 수준을 체계적으로 평가하고자 한다.
배경
 ChatGPT는 OpenAI가 개발한 대규모 언어 모델(LLM) 기반 챗봇으로, 트랜스포머(Transformer) 아키텍처를 기반으로 한다. 2018년 GPT 모델의 등장 이후, GPT-2, GPT-3를 거쳐 인간의 피드백을 통한 강화학습(RLHF) 기법이 적용된 InstructGPT와 ChatGPT로 발전해왔다. 이러한 발전 과정을 통해 모델은 인간의 선호도에 맞는, 보다 정교하고 맥락에 맞는 응답을 생성할 수 있게 되었다. 논문의 Figure 1은 이러한 진화 과정을 시각적으로 보여준다.
ChatGPT는 OpenAI가 개발한 대규모 언어 모델(LLM) 기반 챗봇으로, 트랜스포머(Transformer) 아키텍처를 기반으로 한다. 2018년 GPT 모델의 등장 이후, GPT-2, GPT-3를 거쳐 인간의 피드백을 통한 강화학습(RLHF) 기법이 적용된 InstructGPT와 ChatGPT로 발전해왔다. 이러한 발전 과정을 통해 모델은 인간의 선호도에 맞는, 보다 정교하고 맥락에 맞는 응답을 생성할 수 있게 되었다. 논문의 Figure 1은 이러한 진화 과정을 시각적으로 보여준다.
모델 아키텍처 / 방법론
- 핵심 구조/방법: LeetCode에서 수집한 프로그래밍 문제들을 ChatGPT에 입력하여 솔루션 코드를 생성하고, 이를 다시 LeetCode에 제출하여 채점 결과를 분석하는 방식으로 성능을 평가했다.
- 주요 구성 요소:
- 데이터셋: LeetCode 플랫폼에서 Array, Backtracking, Binary Search 등 10개 카테고리에 걸쳐 총 300개의 문제를 수집했다. 각 카테고리별로 Easy, Medium, Hard 난이도의 문제가 10개씩 포함되었다.
- 응답 생성: 초기에는 문제 URL을 제공하거나 문제 설명을 그대로 복사하는 방식을 사용했으나, 온라인 저지 시스템의 형식(예: 특정 클래스 및 메소드 구조)을 맞추지 못해 컴파일 오류가 자주 발생했다. 이를 해결하기 위해 LeetCode가 요구하는 코드 구조를 프롬프트에 명시적으로 포함하는 프롬프트 엔지니어링 기법을 최종적으로 채택하여 응답의 정확성과 유효성을 크게 높였다.
- 평가: 생성된 코드는 LeetCode에 제출되어 'Accepted', 'Wrong Answer', 'Runtime Error', 'Time Limit Exceeded' 등의 상태로 평가되었다. 이 중 'Accepted' 비율을 핵심 성능 지표로 사용했다.
실험 결과
- 주요 데이터셋: LeetCode의 10개 알고리즘 카테고리에서 추출한 300개의 프로그래밍 문제.
- 핵심 성능 지표:
- 전체 성능: ChatGPT의 전체 정답률은 66.00%로, 평균적인 인간 사용자의 52.95%보다 약 13%p 높았다.
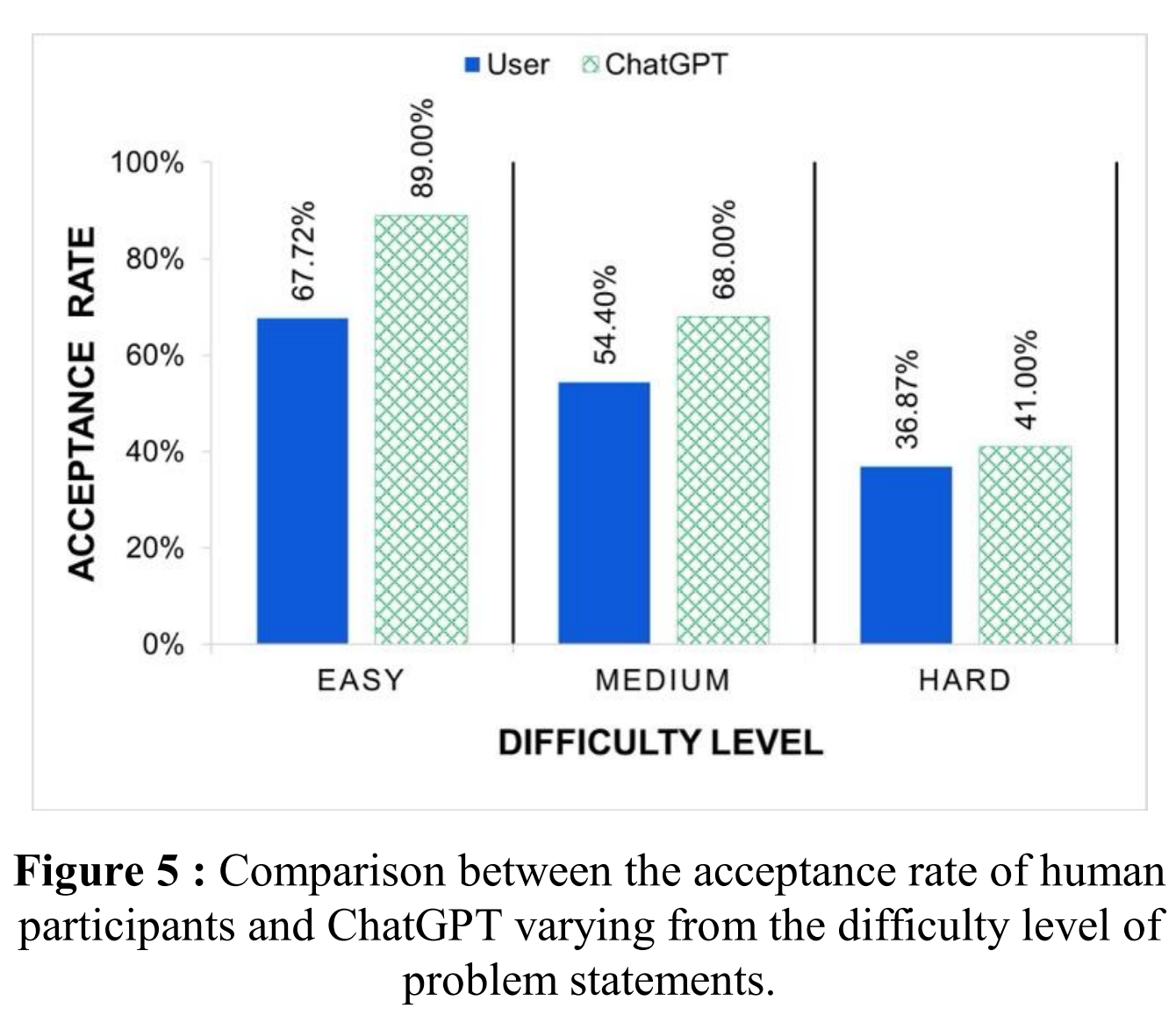
- 난이도별 성능: ChatGPT는 Easy 문제에서 89.00%의 높은 정답률을 보였으나, Medium(68.00%), Hard(41.00%)로 갈수록 성능이 크게 하락했다. 이는 인간 사용자의 성능 하락 추세와 유사하나, 모든 난이도에서 ChatGPT가 더 높은 정답률을 기록했다. 이 비교 결과는 논문의 Figure 5에 잘 나타나 있다.
- 전체 성능: ChatGPT의 전체 정답률은 66.00%로, 평균적인 인간 사용자의 52.95%보다 약 13%p 높았다.
- 비교 결과:
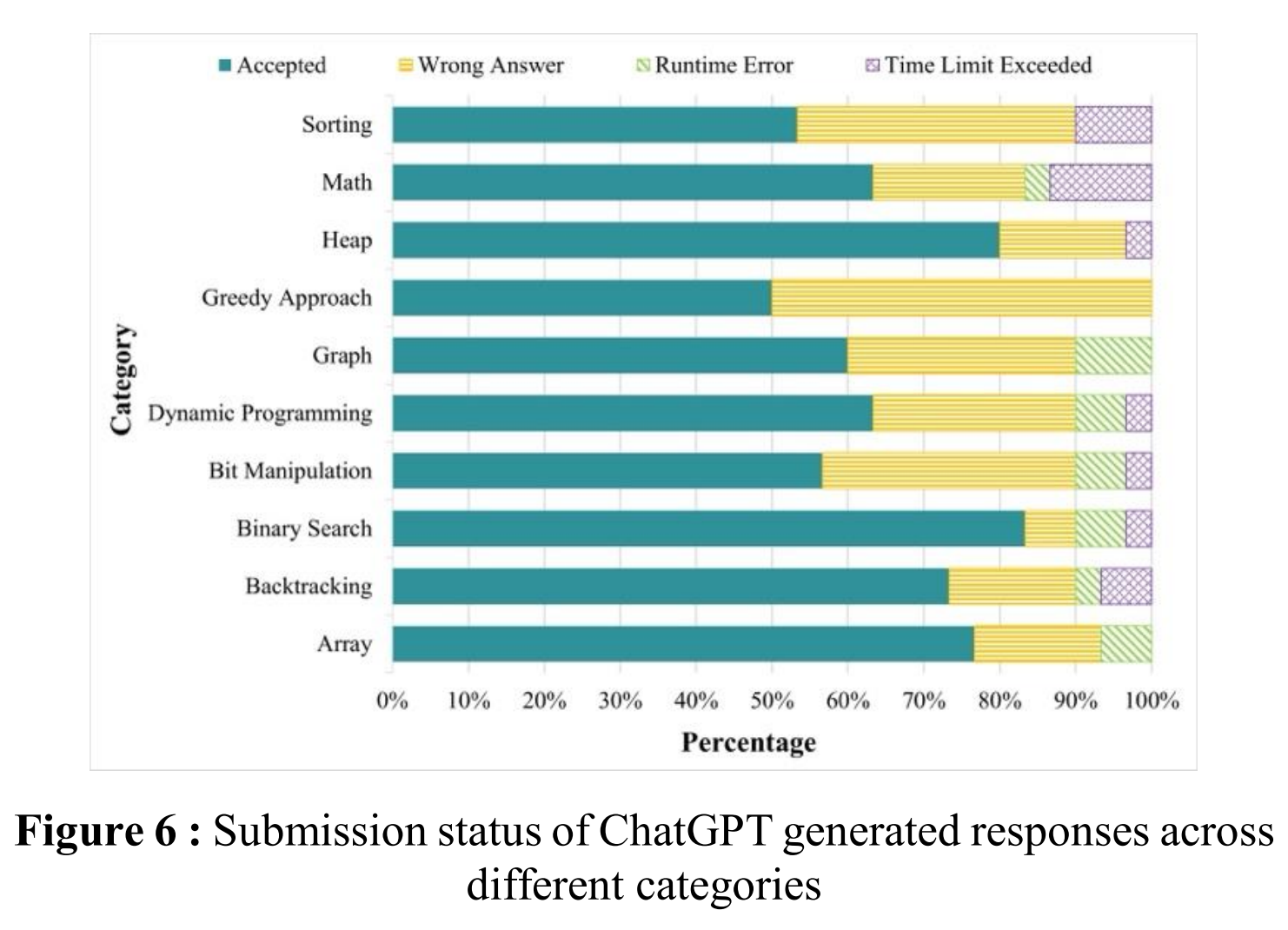
- 카테고리별 성능: ChatGPT는 'Binary Search' 카테고리에서 83.33%로 가장 높은 성능을 보였고, 'Greedy Approach' 카테고리에서는 50.00%로 가장 낮은 성능을 보였다. 논문의 Figure 6은 각 카테고리별 제출 결과(정답, 오답, 런타임 에러 등)의 분포를 보여준다.
- 'Greedy Approach'와 같이 국소 최적해가 전역 최적해로 이어지지 않는 복잡한 추론이 필요한 문제에서 특히 어려움을 겪는 것으로 분석되었다.
결론
본 연구는 ChatGPT가 경쟁적 프로그래밍 문제 해결에 있어 상당한 잠재력을 가지고 있으며, 특히 쉬운 및 중간 난이도 문제에서는 평균적인 인간을 능가하는 성능을 보임을 입증했다. 그러나 문제의 복잡성이 증가할수록 성능이 저하되는 현상은 복잡한 알고리즘이나 수학적 추론 능력에 한계가 있음을 시사한다. 또한, 정확하고 유효한 코드를 얻기 위해서는 명확한 지침을 제공하는 프롬프트 엔지니어링이 필수적임을 확인했다. 향후 연구로는 AI 시스템에 더 저항력 있는 프로그래밍 문제 유형을 개발하는 방향이 제안되었다.