TRINITY: A Fast Compressed Multi-attribute Data Store
논문 정보
- 제목: TRINITY: A Fast Compressed Multi-attribute Data Store
- 저자: Ziming Mao (UC Berkeley), Kiran Srinivasan (NetApp), Anurag Khandelwal (Yale)
- 학회/저널: Nineteenth European Conference on Computer Systems (EuroSys '24)
- 발행일: 2024-04-22
- DOI: 10.1145/3627703.3650072
- 주요 연구 내용: 본 논문은 다중 속성 레코드에 대해 빠른 쿼리와 높은 저장 효율성을 동시에 달성하는 인메모리 데이터 스토어 TRINITY를 제안함. 이를 위해 새로운 동적 압축 데이터 구조인 MDTRIE를 설계했으며, 이는 일반화된 모튼 코드(Generalized Morton Code)와 자기-인덱싱(self-indexed) 트라이 구조를 결합하여 압축된 데이터 표현 위에서 직접 다중 속성 쿼리를 수행함.
- 주요 결과 및 결론: 실제 워크로드 평가 결과, TRINITY는 기존 최신 시스템 대비 7.2-59.6배 빠른 다중 속성 검색 성능을 보임. 저장 공간은 OLAP 컬럼 스토어와 유사하며 NoSQL 및 OLTP 데이터베이스보다 4.8-15.1배 적게 사용함. 또한, 포인트 쿼리 처리량은 NoSQL 스토어와 비슷하고 OLTP 및 OLAP 시스템보다 1.7-52.5배 높임.
- 기여점: 본 논문은 효율적인 다중 속성 범위 검색과 포인트 쿼리를 모두 지원하는 동적, 압축, 자기-인덱싱 다차원 데이터 구조 MDTRIE를 설계함. 또한, MDTRIE를 활용하여 대규모 다중 속성 데이터셋을 저장하고 쿼리하는 분산 데이터 스토어 TRINITY를 구현하고, 실제 워크로드를 통해 그 성능을 입증함.
요약
초록
기계 생성 데이터의 확산으로 여러 속성을 동시에 분석하는 실시간 도구들이 등장했다. 데이터 양이 방대하기 때문에 효율적인 분석을 위해서는 저장 효율성과 성능이 뛰어난 데이터 표현 방식이 필요하다. 본 논문은 대용량 다중 속성 레코드에 대해 쿼리 및 저장 효율성을 동시에 지원하는 시스템인 TRINITY를 제안한다. TRINITY는 새로운 동적 압축 다차원 데이터 구조인 MDTRIE를 통해 이를 달성한다. MDTRIE는 일반화된 모튼 코드, 다중 속성 쿼리 알고리즘, 그리고 자기-인덱싱 트라이 구조의 조합을 사용한다. 실제 사용 사례에 대한 평가 결과, TRINITY는 기존 시스템보다 훨씬 빠른 다중 속성 검색, 낮은 저장 공간, 그리고 높은 포인트 쿼리 처리량을 보여주었다.
서론
사물 인터넷(IoT) 장치나 모니터링 시스템 등에서 생성되는 기계 생성 데이터는 속성이 풍부하고 그 양이 폭발적으로 증가하고 있다. 이러한 데이터를 실시간으로 분석하고 시각화하기 위해서는 대용량 데이터를 빠르고 효율적으로 처리할 수 있는 데이터 스토어가 필수적이다. 기존 시스템들은 빠른 다중 속성 쿼리를 지원하기 위해 큰 저장 공간을 차지하는 추가 인덱스를 사용하거나, 저장 공간을 줄이는 대신 포인트 쿼리나 다중 속성 쿼리 성능을 희생하는 등 한계가 있었다. TRINITY는 이러한 문제를 해결하기 위해 압축된 데이터 표현 위에서 직접 다양한 쿼리를 효율적으로 수행하는 새로운 접근법을 제안한다.
배경
기존의 다중 속성 데이터 처리 방식은 크게 두 가지 문제점을 가진다. 첫째, 여러 속성에 대한 인덱스를 각각 생성하고 쿼리 시 결과를 조합하는 방식은 속성 수가 많아질수록 성능이 저하되고 저장 공간 오버헤드가 크다. 둘째, 데이터 압축에 초점을 맞춘 시스템들은 특정 유형의 쿼리(예: 포인트 쿼리)나 데이터 수정(update)을 효율적으로 지원하지 못하는 경우가 많다. TRINITY는 이러한 한계를 극복하기 위해 다중 속성을 하나의 값으로 인코딩하고, 이를 압축된 트라이 구조에 저장하며, 별도의 인덱스 없이 포인트 쿼리를 지원하는 자기-인덱싱 방식을 채택했다.
모델 아키텍처 / 방법론
-
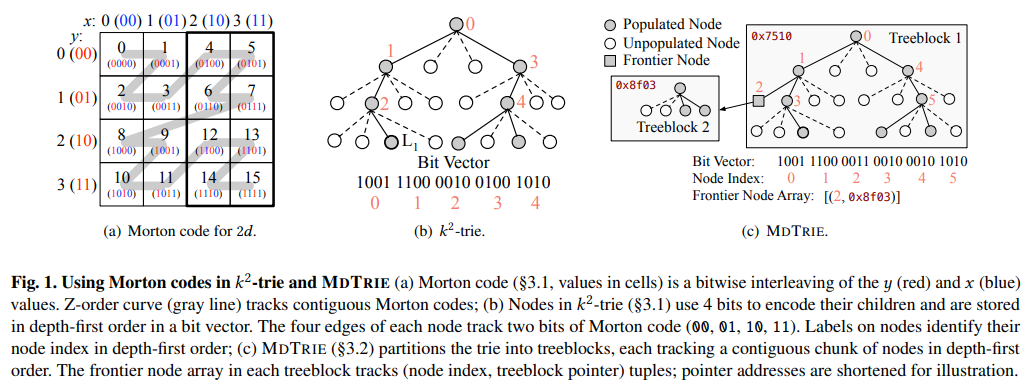
핵심 구조/방법: TRINITY의 핵심은 MDTRIE라는 새로운 데이터 구조다. MDTRIE는 다중 속성 데이터를 '일반화된 모튼 코드(Generalized Morton Code)'로 인코딩하여 단일 차원 값으로 변환하고, 이를 압축된 트라이(succinct trie)에 저장한다. 트라이는 논리적으로 '트리블록(treeblock)' 단위로 분할되어 관리되며, 이는 업데이트 비용을 줄여준다 (논문의 Figure 1(c) 참조).
-
주요 구성 요소:
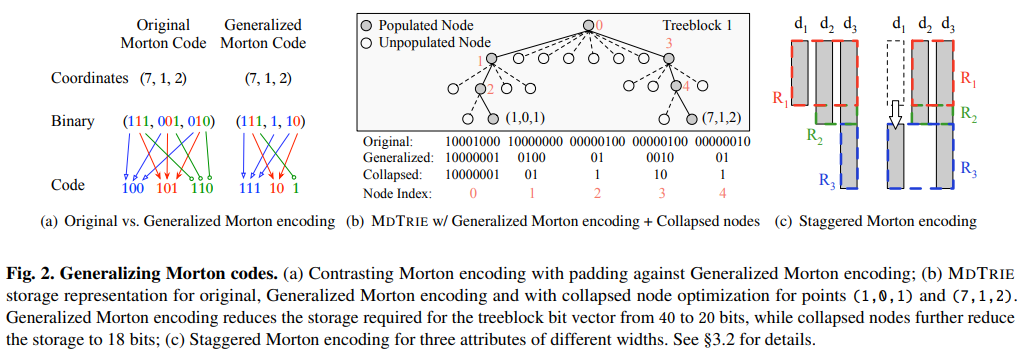
- 일반화된 모튼 인코딩 (Generalized Morton Encoding): 기존 모튼 코드는 모든 속성의 비트 폭이 동일해야 하지만, 이 방식은 서로 다른 비트 폭을 가진 속성들을 패딩 없이 효율적으로 인코딩한다. 비트가 소진된 차원은 건너뛰는 방식으로 공간 효율성을 크게 높인다 (논문의 Figure 2(a) 참조).
- 붕괴 노드 (Collapsed Nodes): 데이터가 희소할 경우, 트라이의 많은 노드가 단 하나의 자식만 갖게 된다. 이 최적화는 이러한 노드를 비트 대신 비트로 압축하여 표현함으로써 저장 공간을 절약한다.
- 엇갈린 인코딩 (Staggered Encoding): 모든 속성의 비트 인터리빙을 동시에 시작하는 대신, 일부 속성의 시작 시점을 늦추어 트라이의 각 레벨에서 활성화되는 차원 수를 균형 있게 조절한다. 이를 통해 전체적인 저장 공간을 줄일 수 있다(논문의 Figure 2(c) 참조).
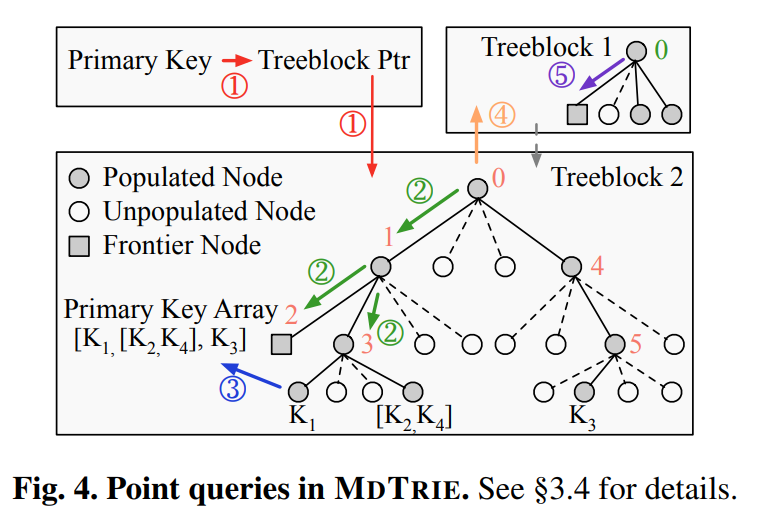
- 자기-인덱싱 (Self-indexing): 별도의 인덱스 구조 없이 MDTRIE 자체에 기본 키(primary key) 정보를 내장한다. 기본 키로부터 해당 데이터가 저장된 리프 노드가 속한 트리블록을 찾고, 리프 노드에서 루트까지 역으로 순회하며 전체 데이터를 재구성하여 포인트 쿼리를 수행한다 (논문의 Figure 4 참조).
-
알고리즘: 다차원 범위 검색 알고리즘은 MDTRIE를 순회하며 검색 범위에 해당하지 않거나 데이터 포인트가 없는 하위 트리를 조기에 제거(pruning)한다. 각 노드에서 비트 연산을 통해 유효한 자식 노드만 탐색하므로 매우 효율적으로 동작한다. Algorithm 1 Multi-demensional Range Search(Pseudo Code)
procedure SEARCH-LEVEL(𝑆,𝑙,𝑖) ← Search at node index 𝑖 at level 𝑙 of MDTRIE for the search range 𝑆 = (𝑃𝑠,𝑃𝑒)
if level 𝑙 is at the leaf level then
Add 𝑖’s primary keys to search result
else
(𝑠,𝑒) ← Morton bits for the current level in (𝑃𝑠,𝑃𝑒)
childIdx ← 𝑠
while childIdx ≤ 𝑒 do
if childIdx is populated ∧ childIdx ∈ 𝑆 then
𝑆′ ← Search range for sub-tree at childIdx
SEARCH-LEVEL(𝑆′,𝑙+1,childIdx)
end if
childIdx ← next set child bit position at node 𝑖
end while
end if
end procedure
실험 결과
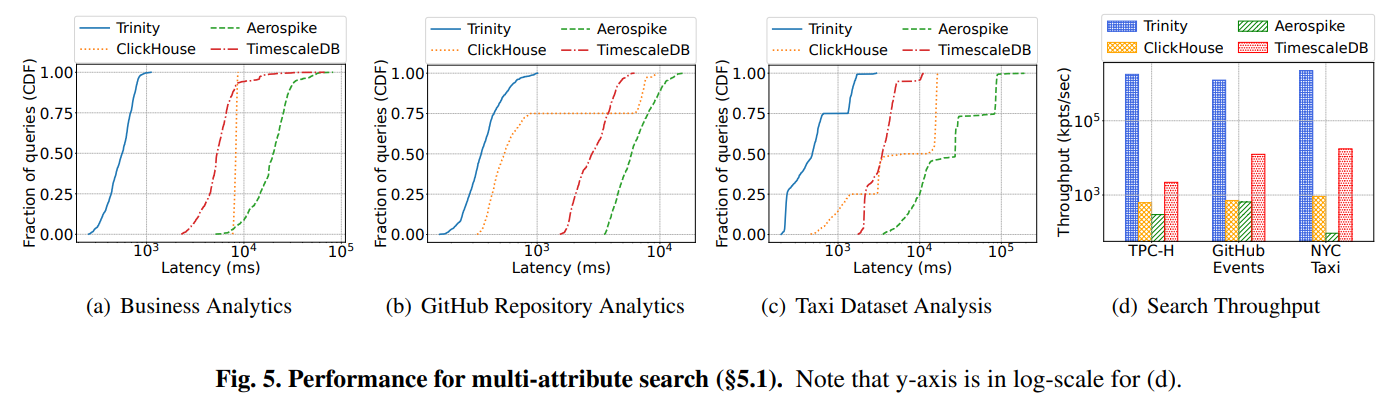
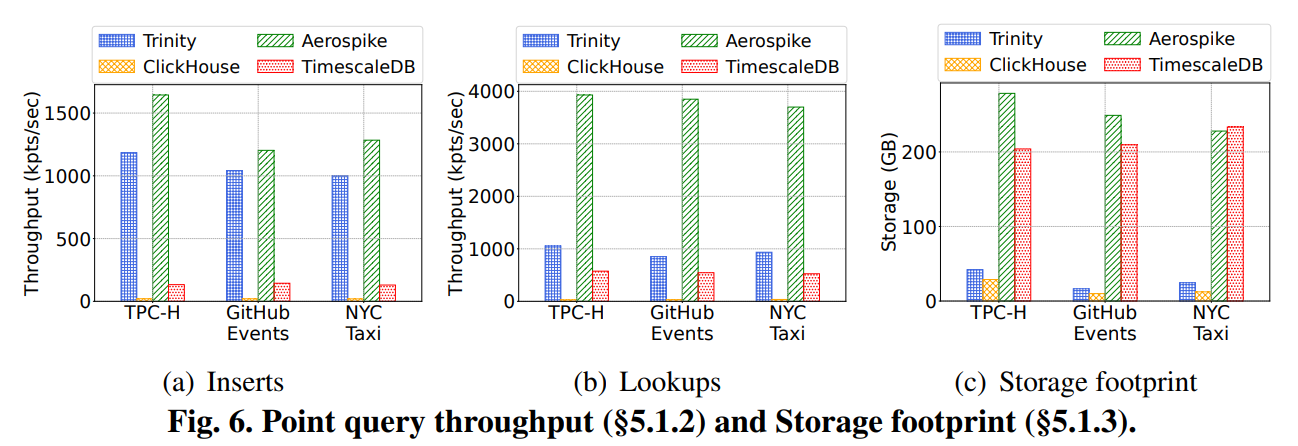
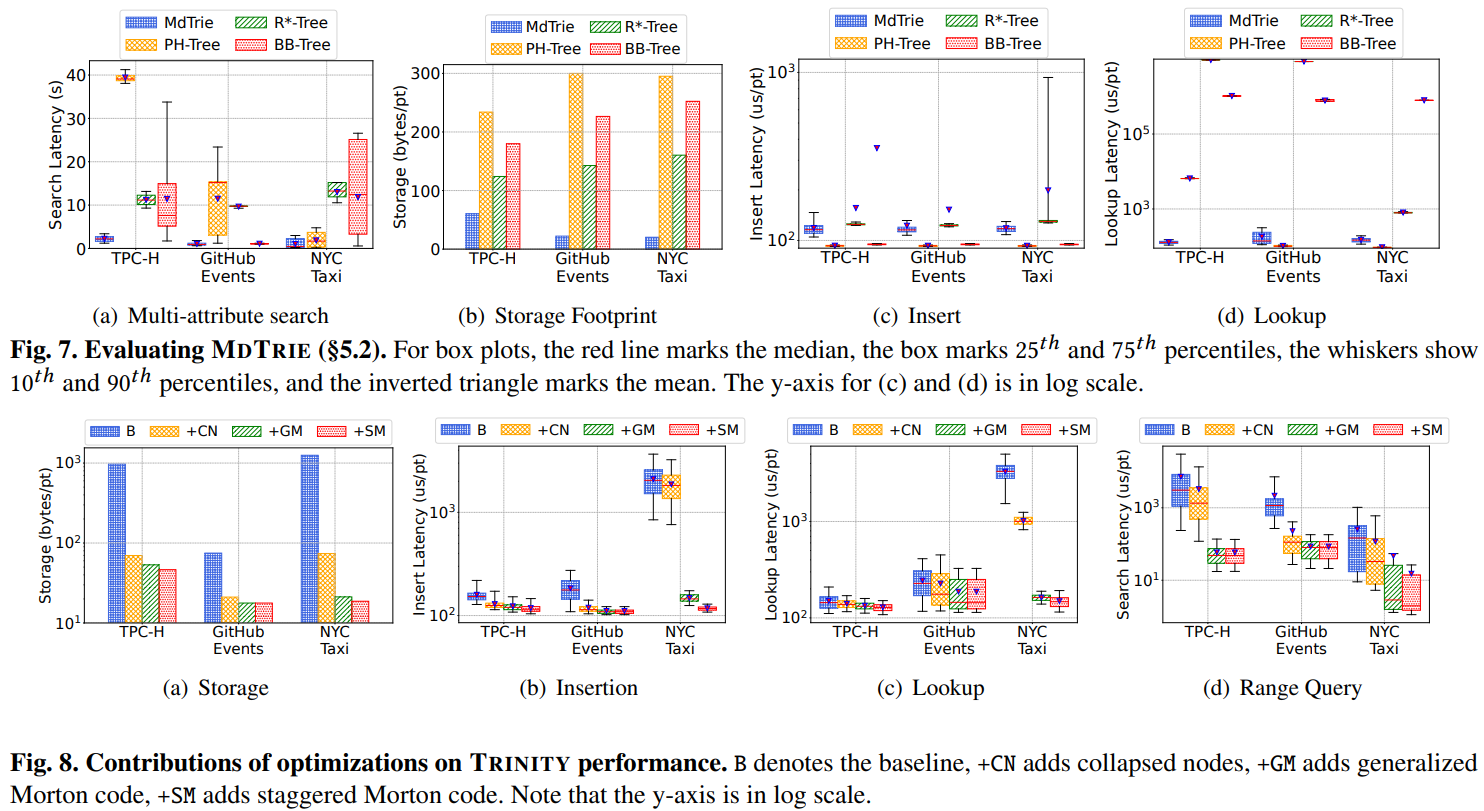
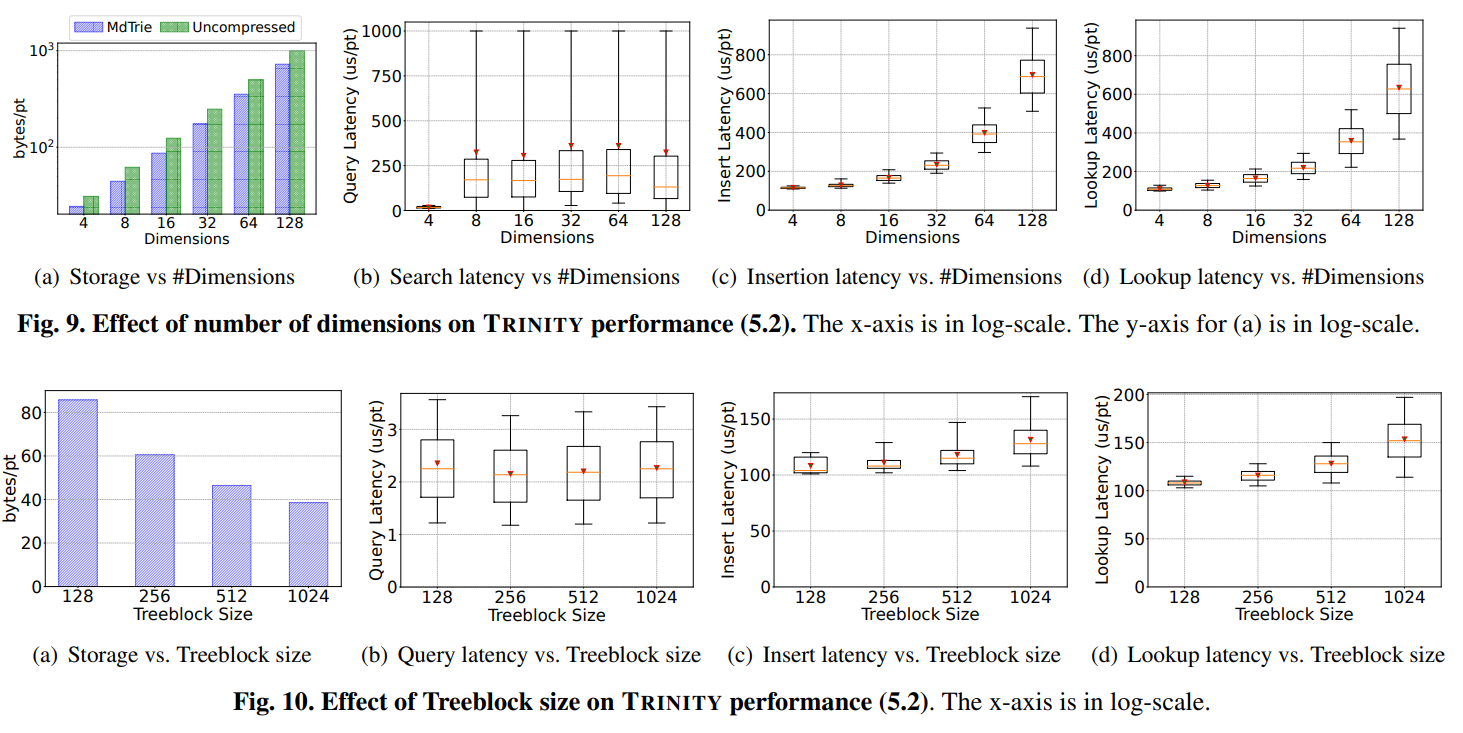
- 주요 데이터셋: TPC-H (비즈니스 분석), GitHub Events (저장소 분석), NYC Taxi (교통량 분석) 등 세 가지 실제 대용량 데이터셋을 사용하여 실험을 진행했다.
- 핵심 성능 지표:
- 다중 속성 검색: TRINITY는 Aerospike, TimescaleDB, ClickHouse와 같은 최신 시스템들과 비교했을 때, 모든 데이터셋에서 평균 7.2배에서 59.6배 낮은 지연 시간(latency)을 기록했다.
- 저장 공간: TRINITY의 저장 공간은 Aerospike보다 6.6-15.1배, TimescaleDB보다 4.8-12.7배 적었다. 압축된 컬럼 기반 스토어인 ClickHouse와는 비슷한 수준이었다.
- 포인트 쿼리: TRINITY는 NoSQL 스토어인 Aerospike와 유사한 수준의 높은 처리량을 보였으며, TimescaleDB나 ClickHouse보다는 월등히 뛰어난 성능을 보였다.
- 비교 결과: MDTRIE 자체의 성능을 R*-Tree, PH-Tree 등 다른 다차원 데이터 구조와 비교한 결과에서도 검색 지연 시간과 저장 공간 측면에서 모두 우수한 성능을 보였다. 특히 제안된 최적화 기법(붕괴 노드, 일반화된 모튼 인코딩 등)이 성능과 공간 효율성 향상에 크게 기여함을 확인했다. (실험 결과 그래프는 논문의 Figure 5 ~ 10참조)
결론
본 연구는 대규모 다중 속성 데이터를 효율적으로 저장하고 쿼리하기 위한 새로운 인메모리 데이터 스토어인 TRINITY를 제안했다. TRINITY의 핵심인 MDTRIE 데이터 구조는 일반화된 모튼 코드, 압축 트라이, 자기-인덱싱 기법을 결합하여 기존 시스템들의 한계점이었던 '빠른 다중 속성 검색'과 '낮은 저장 공간'이라는 두 가지 목표를 성공적으로 달성했다. 실험 결과를 통해 TRINITY가 다양한 실제 애플리케이션에서 높은 성능과 효율성을 제공할 수 있음을 입증했다.