Attention Is All You Need
논문 정보
- 제목: Attention Is All You Need
- 저자: Ashish Vaswani (Google Brain), Noam Shazeer (Google Brain), Niki Parmar (Google Research), Jakob Uszkoreit (Google Research), Llion Jones (Google Research), Aidan N. Gomez (University of Toronto), Łukasz Kaiser (Google Brain), Illia Polosukhin
- 학회/저널: 31st Conference on Neural Information Processing Systems (NIPS 2017)
- 발행일: 2017-12-06
- DOI: 10.48550/arXiv.1706.03762
- 주요 연구 내용: 이 연구는 순환(recurrence) 및 합성곱(convolution)을 완전히 배제하고 오직 어텐션(attention) 메커니즘에만 의존하는 새로운 시퀀스 변환 모델인 '트랜스포머'를 제안함. 트랜스포머는 인코더-디코더 구조를 따르며, 각 부분은 여러 개의 동일한 레이어를 쌓아 구성되고, 각 레이어는 멀티-헤드 셀프-어텐션과 위치별 피드포워드 네트워크라는 두 개의 핵심적인 하위 레이어로 이루어짐.
- 주요 결과 및 결론: 트랜스포머는 기계 번역 작업에서 기존의 최고 성능 모델들을 능가하는 결과를 보임. WMT 2014 영어-독일어 번역 태스크에서 28.4 BLEU 점수를 기록하여 기존 최고 기록을 2 BLEU 이상 경신하며, 영어-프랑스어 번역 태스크에서는 41.8 BLEU 점수로 새로운 단일 모델 최고 기록을 세움. 이러한 성과를 기존 모델들보다 훨씬 적은 훈련 시간으로 달성하여 병렬화의 이점을 입증함.
- 기여점: 본 논문은 어텐션 메커니즘만으로도 시퀀스 변환 작업에서 최첨단 성능을 달성할 수 있음을 보여줌. 순차적 계산에 의존하는 RNN을 병렬 계산이 가능한 셀프-어텐션으로 대체함으로써 훈련 속도를 크게 향상시키고, 더 우수한 번역 품질을 달성하는 새로운 패러다임을 제시함.
요약
초록
기존의 지배적인 시퀀스 변환 모델들은 인코더와 디코더를 포함하는 복잡한 순환 신경망(RNN)이나 합성곱 신경망(CNN)에 기반한다. 최고 성능의 모델들은 인코더와 디코더를 어텐션 메커니즘으로 연결한다. 본 논문에서는 순환과 합성곱을 완전히 배제하고 오직 어텐션 메커니즘에만 기반한 새로운 간단한 네트워크 아키텍처인 '트랜스포머'를 제안한다. 두 가지 기계 번역 작업에 대한 실험 결과, 이 모델들은 품질이 우수하면서도 병렬화 수준이 높아 훈련에 필요한 시간이 훨씬 적게 걸린다는 것을 보여준다. WMT 2014 영어-독일어 번역 태스크에서 28.4 BLEU를 달성하여 기존 최고 기록을 2 BLEU 이상 개선했으며, 영어-프랑스어 태스크에서는 8개의 GPU로 3.5일간 훈련하여 41.8이라는 새로운 단일 모델 최고 BLEU 점수를 기록했다. 이는 기존 최고 모델들의 훈련 비용의 일부에 불과하다. 또한 트랜스포머가 영어 구문 분석과 같은 다른 태스크에도 성공적으로 적용되어 일반화 성능이 뛰어남을 보인다.
서론
RNN, 특히 LSTM과 GRU는 시퀀스 모델링 및 기계 번역과 같은 변환 문제에서 최고의 접근 방식으로 자리 잡았다. 그러나 RNN은 이전의 은닉 상태 를 기반으로 현재 상태 를 계산하는 순차적인 특성을 가지므로, 훈련 예제 내에서의 병렬화를 불가능하게 만든다. 이러한 순차적 계산의 제약은 긴 시퀀스에서 큰 단점이 된다. 어텐션 메커니즘은 입출력 시퀀스 내 거리와 상관없이 의존성을 모델링할 수 있게 해주지만, 대부분의 경우 RNN과 함께 사용되었다. 이 연구는 순환 신경망을 완전히 제거하고, 대신 입력과 출력 간의 전역적인 의존성을 포착하기 위해 전적으로 어텐션 메커니즘에만 의존하는 트랜스포머 모델을 제안한다.
배경
순차적 계산을 줄이려는 목표는 CNN을 기본 빌딩 블록으로 사용하는 Extended Neural GPU, ByteNet, ConvS2S와 같은 모델들의 기초가 되기도 했다. 하지만 이러한 모델들에서는 두 임의의 위치 간의 신호를 연결하는 데 필요한 연산 횟수가 거리에 따라 증가한다. 트랜스포머에서는 이 연산 횟수가 상수로 줄어든다. 또한, 단일 시퀀스 내의 다른 위치들을 연관시켜 시퀀스의 표현을 계산하는 어텐션 메커니즘인 셀프-어텐션(self-attention)은 다양한 NLP 태스크에서 성공적으로 사용된 바 있다. 하지만 트랜스포머는 시퀀스 정렬 RNN이나 합성곱을 사용하지 않고 오직 셀프-어텐션에만 의존하여 입출력 표현을 계산하는 최초의 변환 모델이다.
모델 아키텍처 / 방법론
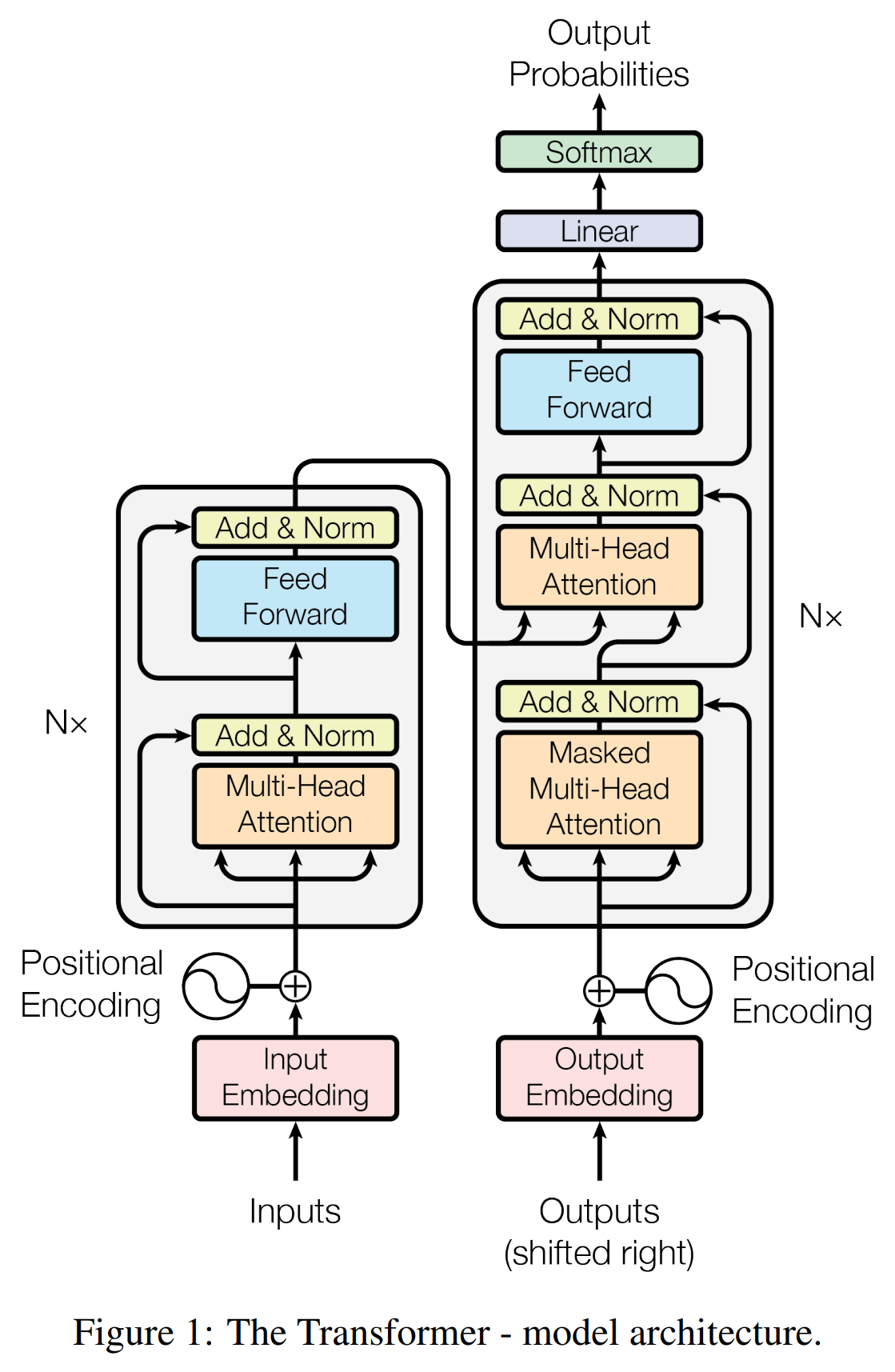 논문의 Figure 1은 트랜스포머의 전체적인 인코더-디코더 구조를 보여준다. 인코더(왼쪽)와 디코더(오른쪽)는 각각 N=6개의 동일한 레이어를 쌓은 형태이다.
논문의 Figure 1은 트랜스포머의 전체적인 인코더-디코더 구조를 보여준다. 인코더(왼쪽)와 디코더(오른쪽)는 각각 N=6개의 동일한 레이어를 쌓은 형태이다.
-
핵심 구조/방법: 트랜스포머는 대부분의 경쟁력 있는 신경망 시퀀스 변환 모델들과 마찬가지로 인코더-디코더 구조를 따른다. 인코더는 입력 시퀀스를 연속적인 표현의 시퀀스로 매핑하고, 디코더는 이 표현을 바탕으로 출력 시퀀스를 생성한다. 모델의 핵심은 순환 레이어를 멀티-헤드 셀프-어텐션 레이어로 대체한 것이다.
-
주요 구성 요소:
- 인코더: 각 레이어는 두 개의 하위 레이어, 즉 멀티-헤드 셀프-어텐션 메커니즘과 위치별 완전 연결 피드포워드 네트워크로 구성된다. 각 하위 레이어 주위에는 잔차 연결(residual connection)과 계층 정규화(layer normalization)가 적용된다: .
- 디코더: 인코더의 두 하위 레이어에 더해, 인코더 스택의 출력에 대해 멀티-헤드 어텐션을 수행하는 세 번째 하위 레이어를 삽입한다. 또한, 디코더의 셀프-어텐션 하위 레이어는 후속 위치에 주의를 기울이는 것을 방지하기 위해 마스킹(masking) 처리를 하여 자기회귀(auto-regressive) 속성을 보존한다.
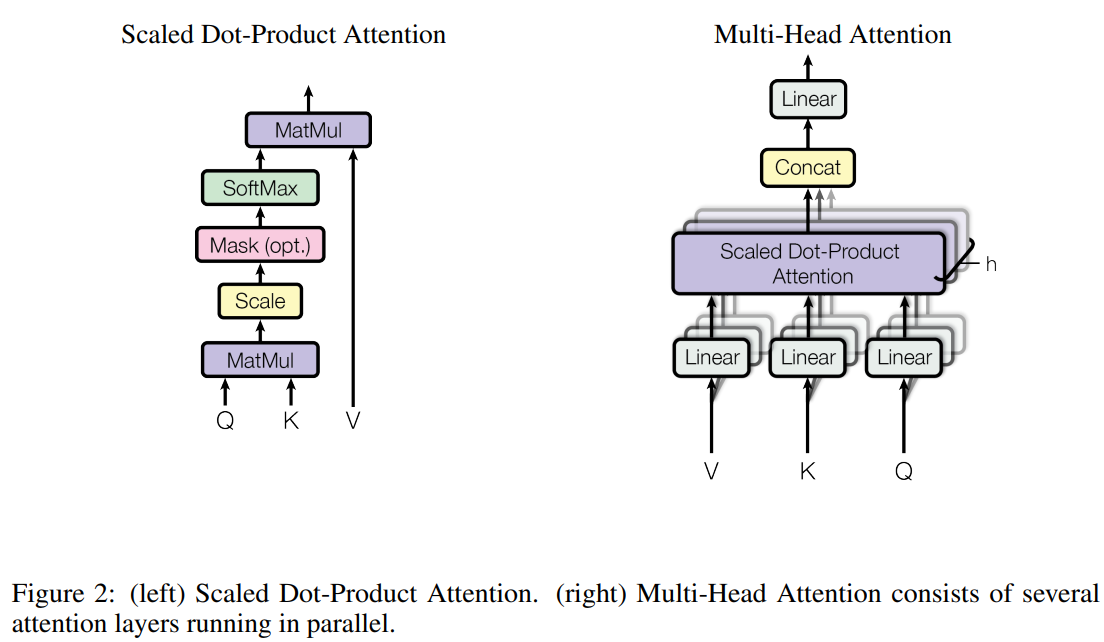
- 어텐션: Figure 2는 Scaled Dot-Product Attention과 이를 병렬적으로 여러 개 사용하는 Multi-Head Attention의 구조를 시각화하여 보여준다.
- Scaled Dot-Product Attention: 쿼리(Q), 키(K), 밸류(V)를 입력으로 받아 어텐션 가중치를 계산한다. 스케일링 요소 를 사용하여 안정적인 그래디언트를 확보한다.
- Multi-Head Attention: 단일 어텐션 함수를 수행하는 대신, Q, K, V를 h=8개의 다른 선형 투영(linear projection)을 통해 여러 번 병렬로 어텐션을 수행한다. 이를 통해 모델이 다른 위치의 다른 표현 부분 공간으로부터 정보를 동시에 주목할 수 있다.
- 위치별 피드포워드 네트워크: 각 위치에 개별적으로 동일하게 적용되는 완전 연결 피드포워드 네트워크이다. 두 개의 선형 변환과 그 사이에 ReLU 활성화 함수로 구성된다.
- 위치 인코딩: 모델에 순환이나 합성곱이 없기 때문에, 시퀀스의 순서 정보를 활용하기 위해 위치 인코딩을 입력 임베딩에 추가한다. 사인 및 코사인 함수를 사용하여 위치 정보를 주입한다.
실험 결과
- 주요 데이터셋: WMT 2014 영어-독일어(약 450만 문장 쌍) 및 WMT 2014 영어-프랑스어(3600만 문장 쌍) 데이터셋을 사용했다.
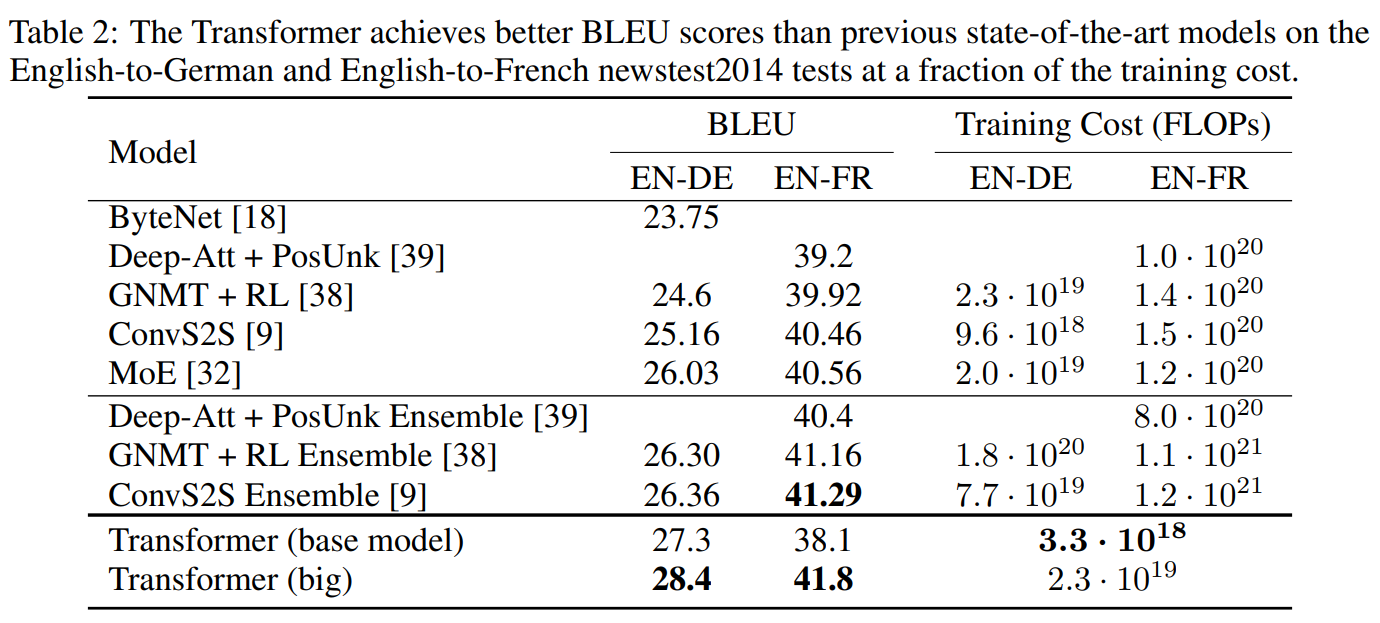
- 핵심 성능 지표: 기계 번역의 표준 평가 지표인 BLEU 점수를 사용했다. 논문의 Table 2에서 상세한 성능 비교를 확인할 수 있다.
- 비교 결과:
- 영어-독일어 번역: 'Transformer (big)' 모델은 28.4 BLEU 점수를 기록하여, 앙상블 모델을 포함한 이전의 모든 최고 성능 모델들을 2.0 BLEU 이상 능가하는 새로운 SOTA를 달성했다.
- 영어-프랑스어 번역: 'Transformer (big)' 모델은 41.8 BLEU 점수를 달성하여, 기존 SOTA 모델 훈련 비용의 1/4 미만으로 새로운 단일 모델 최고 기록을 세웠다.
- 이러한 결과는 8개의 P100 GPU에서 3.5일이라는 비교적 짧은 시간 안에 달성되어, 트랜스포머의 높은 병렬성과 훈련 효율성을 입증했다.
- 또한, 영어 구문 분석 태스크에서도 기존의 RNN 기반 모델들을 능가하는 좋은 성능을 보여 모델의 일반화 가능성을 확인했다.
결론
이 연구는 어텐션에만 전적으로 기반한 최초의 시퀀스 변환 모델인 트랜스포머를 제시했다. 트랜스포머는 인코더-디코더 아키텍처에서 가장 일반적으로 사용되는 순환 레이어를 멀티-헤드 셀프-어텐션으로 대체했다. 기계 번역 태스크에서 트랜스포머는 순환 또는 합성곱 계층에 기반한 아키텍처보다 훨씬 빠르게 훈련될 수 있으며, WMT 2014 영어-독일어 및 영어-프랑스어 번역 태스크 모두에서 새로운 최고 수준의 성능을 달성했다. 연구진은 어텐션 기반 모델의 미래에 대해 기대하며, 텍스트 이외의 이미지, 오디오, 비디오와 같은 다른 양식의 입출력을 포함하는 문제로 트랜스포머를 확장할 계획이다.