Flow2Code: Evaluating Large Language Models for Flowchart-based Code Generation Capability
논문 정보
- 제목: Flow2Code: Evaluating Large Language Models for Flowchart-based Code Generation Capability
- 저자: Mengliang He (East China Normal University), Jiayi Zeng (East China Normal University), Yankai Jiang (Shanghai AI Lab), Wei Zhang (East China Normal University), Zeming Liu (Beihang University), Xiaoming Shi (East China Normal University), Aimin Zhou (East China Normal University)
- 학회/저널: arXiv (v1)
- 발행일: 2025-06-02
- DOI: (arXiv:2506.02073)
- 주요 연구 내용: 기존 LLM 코드 생성 벤치마크가 순서도(flowchart)를 간과하고 있다는 문제를 지적. 15개 프로그래밍 언어, 3가지 순서도 유형(코드, UML, 의사코드)에 걸친 총 16,866개의 순서도를 포함하는 'Flow2Code'라는 새로운 벤치마크 데이터셋을 구축.
- 주요 결과 및 결론: 13개의 최신 멀티모달 LLM(MLLM)을 평가한 결과, 현재 모델들이 순서도를 완벽하게 코드로 변환하지 못하며, 특히 의사코드(pseudocode) 순서도에서 성능 저하가 큼을 발견. 또한, 지도 미세조정(Supervised Fine-Tuning)이 모델 성능 향상에 크게 기여함을 확인함.
- 기여점: 순서도 기반 코드 생성이라는 새로운 연구 방향을 제시. 해당 작업을 위한 포괄적인 벤치마크(Flow2Code)를 공개하고, 현재 MLLM의 한계를 명확히 식별하며, 성능 향상을 위한 미세조정의 효과를 입증함.

요약
초록
대형 언어 모델(LLM)이 코드 생성에서 유망한 성능을 보이고 있지만, 기존 벤치마크들은 순서도 기반 코드 생성을 다루지 않았다. 이 연구는 순서도 기반 코드 생성 평가를 위한 새로운 벤치마크인 Flow2Code를 제시한다. 이 데이터셋은 15개의 프로그래밍 언어에 걸쳐 5,622개의 코드 세그먼트와 16,866개의 순서도(코드, UML, 의사코드 유형)로 구성된다. 13개의 멀티모달 LLM을 대상으로 한 광범위한 실험 결과, 현재 LLM들은 순서도를 기반으로 코드를 완벽하게 생성하지 못하며, 지도 미세조정(SFT) 기법이 모델 성능에 크게 기여함을 보여준다.
서론
LLM의 코드 생성 능력 평가를 위한 기존 벤치마크는 주로 텍스트 설명(HumanEval 등)이나 문제 이미지(MMCode 등)에 기반한다. 하지만 프로그램 로직(결정, 루프 등)을 시각화하는 데 더 효과적이고 직관적인 순서도 기반 평가는 누락되어 있었다. 순서도는 코드, UML, 의사코드의 세 가지 주요 유형으로 나뉘며, 이러한 이점에도 불구하고 순서도를 코드로 변환하는 전용 벤치마크가 없는 실정이다. 본 연구는 이 공백을 메우기 위해 15개 언어와 3가지 순서도 유형을 포함하는 포괄적인 벤치마크 Flow2Code를 제안한다.
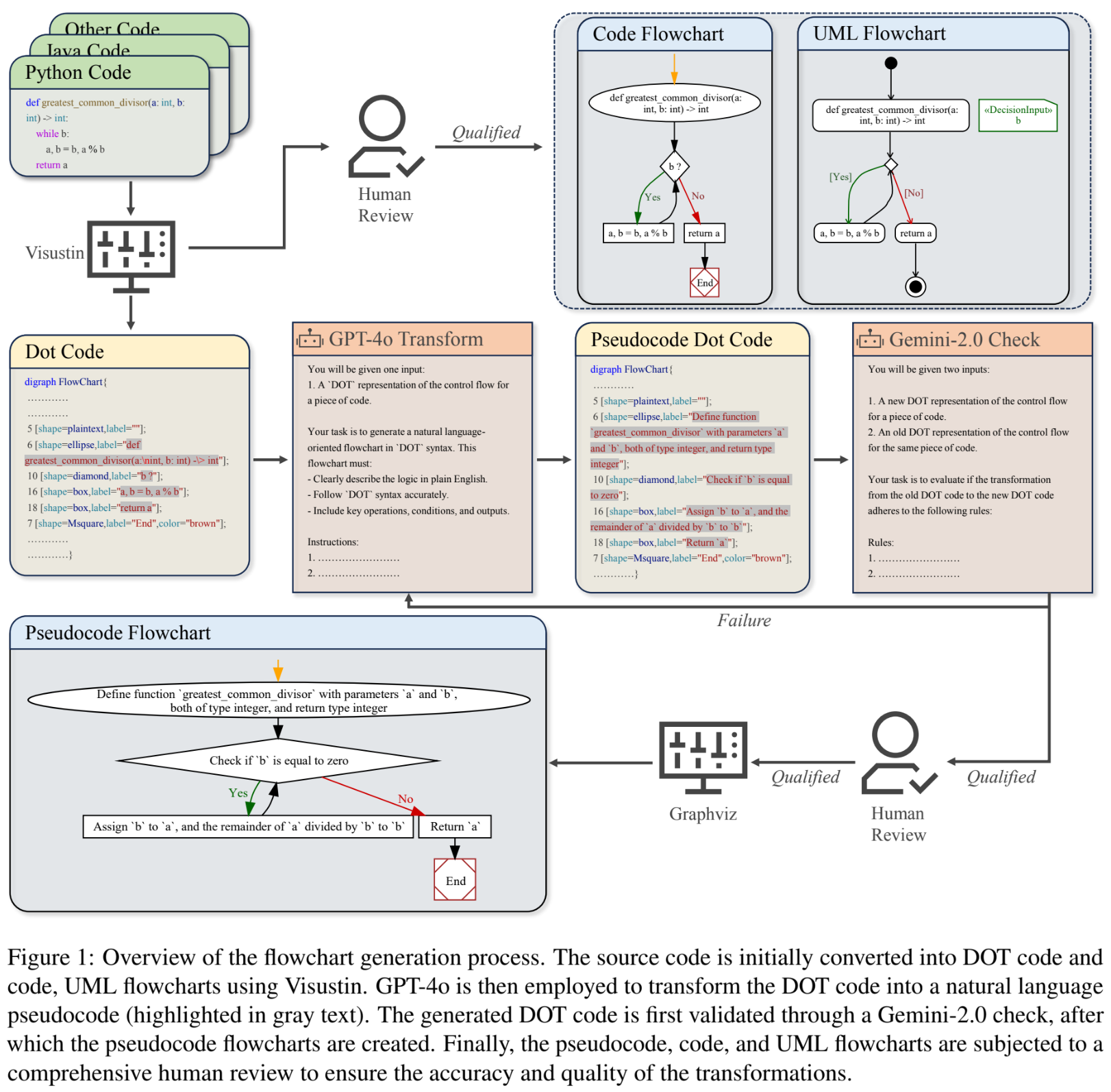
모델 아키텍처 / 방법론
이 연구의 핵심은 모델이 아닌 Flow2Code 벤치마크 구축 방법론에 있다. 데이터셋은 HumanEval-X, MBXP 등 4개의 기존 데이터셋에서 소스 코드를 수집하여 구축되었다.
논문의 Figure 1은 전체 순서도 생성 과정을 보여준다.
-
1. 코드 순서도 및 UML 순서도 생성:
- 원본 소스 코드를 Visustin 소프트웨어를 사용해 코드 순서도(Code Flowchart)와 UML 순서도(UML Flowchart)로 변환한다.
- 5명의 컴퓨터 과학 석사 학위와 4년 이상 경력을 가진 평가자가 생성된 순서도의 논리적 정확성, 완전성, 의미적 정확성을 검증한다. (Krippendorff's Alpha 달성)
-
2. 의사코드 순서도(Pseudocode Flowchart) 생성:
- DOT 코드 생성: Visustin을 사용해 코드의 제어 흐름을 Graphviz의 DOT 파일 형식으로 변환한다.
- GPT-40 변환: DOT 파일 내의 각 노드 레이블(코드 조각)을 GPT-40을 사용하여 자연어(의사코드) 설명으로 변환한다. (예:
b?->check if 'b' is equal to zero) - Gemini-2.0 검증: GPT-40의 변환 결과를 검증하기 위해 Gemini-2.0을 사용하여 편향을 피하고 정확성을 교차 검증한다. 5회 시도 후에도 실패하면 데이터를 폐기한다.
- 인간 검증: 변환된 의사코드의 의미적 정확성, 명확성, 일관성을 인간 평가자가 다시 검증한다. (Krippendorff's Alpha 달성)
- 자동 순서도 변환: 최종 검증된 의사코드 DOT 파일을 Graphviz를 사용해 시각적인 순서도 이미지로 변환한다.
-
최종 데이터셋: 5,622개의 코드 세그먼트, 16,866개의 순서도(유형별 5,622개), 15개 프로그래밍 언어로 구성되며, 9:1 비율로 훈련/테스트 세트를 분할한다.


실험 결과
- 실험 설정: Claude-3.5-Sonnet, Gemini-2.0, GPT-40, Qwen2-VL 등 13개의 MLLM을 평가했다. 평가는 실행 기반(execution-based)으로 Pass@k (k=1, 3, 5) 지표를 사용했다.
- 주요 데이터셋: Flow2Code 벤치마크 (16,866개 순서도)
- 핵심 성능 지표 및 비교 결과:
- 모델 간 성능 격차: Gemini-2.0이 모든 작업에서 가장 우수한 성능을 보였으며, 차상위 모델인 GPT-40보다 평균 4.78% 높은 Pass@1 점수를 기록했다. LLaVA-7B 같은 소형 모델은 최고 성능 모델 대비 14.3~22.35% 수준의 성능에 그쳤다.
- 순서도 유형별 난이도: 코드 순서도가 가장 높은 평균 Pass@1을 기록했으며, UML 순서도가 그 다음, 의사코드 순서도가 가장 어려웠다 (코드 순서도 대비 평균 10.63% 성능 하락).
- 모델 규모 효과: 모델 크기 증가는 성능 향상으로 이어졌다. Qwen2-VL-72B는 7B 버전에 비해 코드 순서도 작업에서 103.8%의 성능 향상을 보였다.
- 미세조정(SFT) 효과: Qwen2-VL-7B 모델을 Flow2Code 훈련 데이터로 미세조정한(Qwen2-VL-7B-FT) 결과, 큰 폭의 성능 향상이 관찰되었다 (논문의 Figure 5 참조). 특히 C#, Java, JS, PHP 같은 객체지향 및 웹 언어에서 향상 폭이 컸다.
- 언어 민감성: PHP 언어 생성은 3개 모델이 만점을 받을 정도로 쉬웠으나, Fortran, HTML 등은 평균 Pass@1이 PHP 대비 57.2~65.63% 낮았다.
- 난이도별 성능: 논문의 Figure 4는 문제 난이도(Easy, Middle, Hard)와 Pass@1 성능이 명확한 반비례 관계를 보임을 보여준다.
결론
이 연구는 순서도 기반 코드 생성을 위한 최초의 포괄적인 벤치마크 Flow2Code를 제안했다. 15개 언어와 3가지 순서도 유형(코드, UML, 의사코드)을 포함하는 이 데이터셋을 통해 13개 MLLM을 평가한 결과, 현재 모델들(특히 소형 모델)은 순서도의 논리를 코드로 변환하는 데 여전히 한계가 있음을 확인했다. 또한, 의사코드 순서도 변환이 가장 어려운 작업임을 밝혔으며, 지도 미세조정(SFT)이 이러한 한계를 극복하는 데 효과적인 전략임을 입증했다.