OPENFACE 3.0: A Lightweight Multitask System for Comprehensive Facial Behavior Analysis
논문 정보
- 제목: OPENFACE 3.0: A Lightweight Multitask System for Comprehensive Facial Behavior Analysis
- 저자: Jiewen Hu (Carnegie Mellon University), Leena Mathur (Carnegie Mellon University), Paul Pu Liang (Massachusetts Institute of Technology), Louis-Philippe Morency (Carnegie Mellon University)
- 학회/저널: arXiv (v1)
- 발행일: 2025-06-03
- DOI: N/A (arXiv submission)
- 주요 연구 내용: 본 논문은 네 가지 핵심 안면 분석 작업(랜드마크 감지, 표정 단위(AU) 감지, 시선 추정, 감정 인식)을 동시에 수행하는 경량화된 통합 모델 OpenFace 3.0을 제안함. 다중 작업 학습(Multi-Task Learning, MTL) 아키텍처를 사용하여 파라미터를 공유함으로써 효율성을 극대화함.
- 주요 결과 및 결론: OpenFace 3.0은 이전 버전(OpenFace 2.0) 및 타 툴킷 대비 예측 성능, 추론 속도, 메모리 효율성에서 상당한 개선을 보임. 특히 다중 작업 학습을 통해 정면이 아닌 각도의 얼굴(angled faces) 인식 성능이 SOTA 모델을 능가하는 강력한 일반화 성능을 입증함.
- 기여점: 단일 모델로 4가지 안면 분석 작업을 실시간으로 처리할 수 있는 고성능 오픈소스 툴킷을 제공. 또한, 서로 다른 작업(예: 시선 추정 데이터)의 특징 공유가 다른 작업(예: 감정 인식)의 성능, 특히 비정면 얼굴에서의 성능을 향상시킬 수 있음을 보임.
요약
초록
자동 안면 행동 분석 시스템에 대한 관심이 증가함에 따라, 본 논문은 OPENFACE 3.0을 소개한다. 이는 안면 랜드마크 감지, 안면 표정 단위(AU) 감지, 시선 추정, 안면 감정 인식이 가능한 오픈소스 툴킷이다. OPENFACE 3.0은 다양한 인구, 머리 자세, 조명 조건, 비디오 해상도 및 안면 분석 작업에 걸쳐 다중 작업 아키텍처로 훈련된 경량화된 통합 모델을 제공한다. 통합 모델과 훈련 패러다임을 통해 파라미터 공유의 이점을 활용하여, 유사한 툴킷 대비 예측 성능, 추론 속도, 메모리 효율성에서 개선을 보이며 SOTA 모델과 경쟁한다. OPENFACE 3.0은 한 줄의 코드로 설치 및 실행이 가능하며, 특수 하드웨어 없이 실시간으로 작동한다.
서론
얼굴 신호를 이해하는 것은 인간의 사회적 상호작용에 매우 중요하다. 미묘한 시선 변화나 머리 기울임도 사회적 의미 전달에 큰 영향을 미친다. 컴퓨터 비전 커뮤니티는 이러한 세밀한 안면 행동을 해석하여 인간 중심 AI 시스템을 설계하는 데 관심이 커지고 있다. OPENFACE 3.0은 이러한 핵심 안면 신호(랜드마크, AU, 시선, 감정)를 공동으로 수행하는 고성능 오픈소스 툴킷을 제공하며, 연구자와 개발자가 이를 쉽게 통합할 수 있도록 설계되었다. 이 툴킷은 이전 버전(OpenFace 2.0)보다 더 정확하고, 빠르며, 메모리 효율적이고, 특히 비정면 얼굴 분석에서 뛰어난 성능을 보인다.
배경
안면 행동 분석은 전통적으로 개별 작업(랜드마크 감지, AU 감지 등)에 특화된 모델로 각각 발전해왔다. 최근에는 대규모 데이터로 사전 훈련된 비전 트랜스포머(ViT)나 파운데이션 모델이 주목받고 있으며, 다중 작업 학습(MTL)이 강력한 특징 추출 능력으로 인해 안면 분석에 활용되고 있다. OpenFace 3.0은 이러한 MTL 접근 방식을 채택하여, 여러 안면 분석 작업을 위한 일반화된 얼굴 표현을 학습하고, 이를 통해 효율성과 성능을 동시에 달성한다.
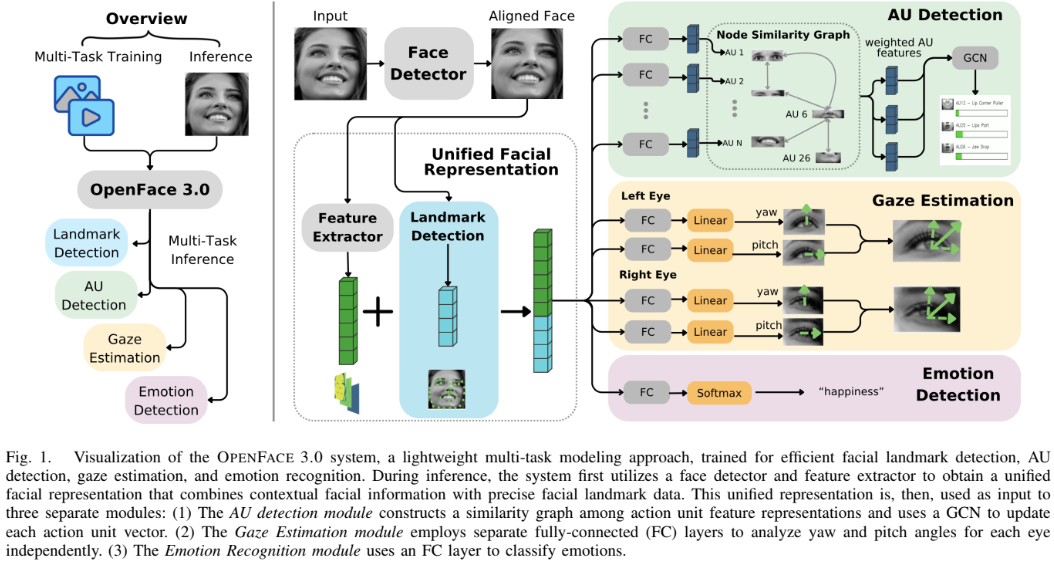
모델 아키텍처 / 방법론
OPENFACE 3.0 시스템의 아키텍처는 논문의 Figure 1에 시각화되어 있다.
-
핵심 구조/방법:
- 얼굴 감지 및 정렬: 먼저 RetinaFace MobileNet-0.25를 사용하여 실시간으로 얼굴 영역을 감지하고 정렬한다.
- 통합 안면 표현 (Unified Facial Representation):
- 랜드마크 감지: 정렬된 얼굴 이미지를 입력받아 4개의 스택형 Hourglass(HG) 네트워크를 통과시켜 랜드마크 좌표(히트맵)를 추출한다.
- 문맥 특징 추출: VGGFace2 데이터셋으로 사전 훈련된 EfficientNet 백본을 사용하여 문맥적 얼굴 특징(contextual features)을 추출한다.
- 결합: 추출된 랜드마크 좌표와 문맥 특징을 연결(concatenate)하여 '통합 안면 표현'을 생성한다.
- 다운스트림 작업 (Downstream Tasks): 이 통합 표현을 입력받아 3개의 병렬 모듈에서 작업을 수행한다.
- AU 감지: 각 AU 특징 벡터 간의 코사인 유사도에 기반한 동적 그래프를 구성하고, GCN(Graph Convolutional Network)을 사용하여 AU 간의 관계를 모델링한다.
- 시선 추정: 왼쪽 눈과 오른쪽 눈의 yaw(좌우), pitch(상하) 각도를 예측하기 위해 4개의 독립적인 FC 레이어를 사용한다.
- 감정 인식: 8가지 감정(행복, 슬픔 등)을 분류하기 위해 FC 레이어와 Softmax를 사용한다.
-
3단계 다중 작업 훈련:
- 1단계: 랜드마크 감지 모듈을 독립적으로 훈련시킨 후, 파라미터를 고정(freeze)한다.
- 2단계: 백본을 고정한 채, 작업별 분류기(classifier)만 훈련시켜 특징을 안정화한다.
- 3단계: 백본과 분류기 모두 미세 조정(fine-tuning)하여 전체 모델의 상호작용을 최적화한다.
-
수식 (손실 함수 가중치): 서로 다른 스케일을 가진 여러 작업의 손실을 효과적으로 균형 맞추기 위해, Homoscedastic Uncertainty(동질 분산 불확실성) 기반 가중치 방법을 사용한다. 각 작업의 불확실성을 학습 가능한 파라미터()로 모델링한다.
실험 결과
실험은 AMD Ryzen Threadripper CPU와 NVIDIA GeForce GTX 1080 Ti GPU 환경에서 수행되었다.
-
주요 데이터셋: _ 랜드마크 감지: 300W, WFLW _ AU 감지: DISFA, BP4D _ 시선 추정: MPII Gaze, Gaze360 _ 감정 인식: AffectNet

-
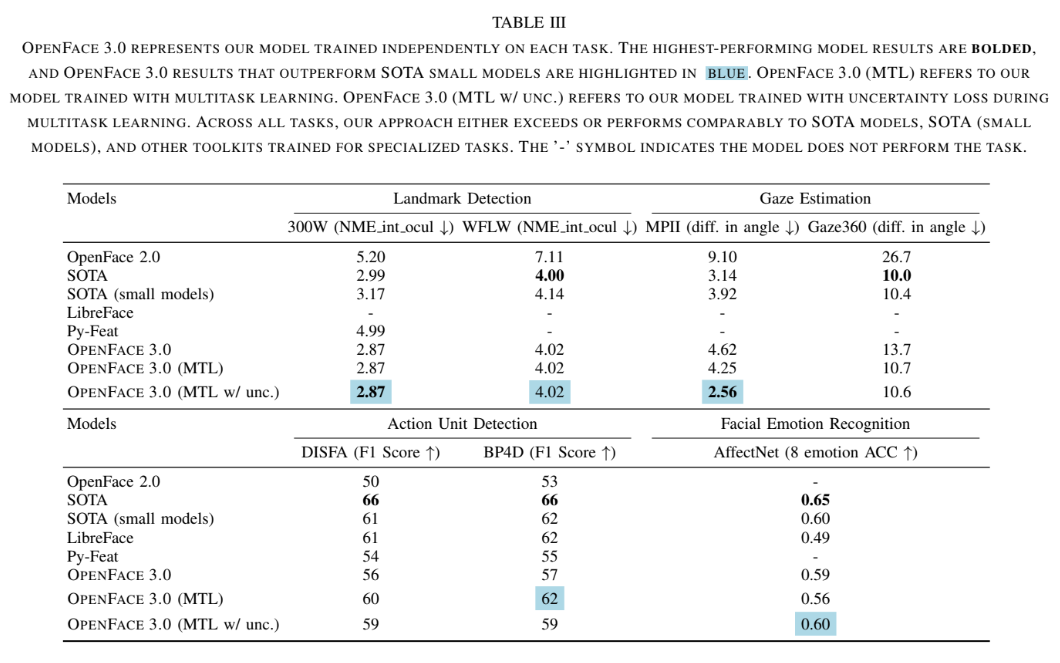
핵심 성능 지표 (Table III 참고):
- 랜드마크 감지 (NME↓): 300W 데이터셋에서 2.87 NME을 달성하여 SOTA small 모델(3.17) 및 OpenFace 2.0(5.20)보다 우수했다.
- AU 감지 (F1↑): DISFA(59%) 및 BP4D(59%)에서 SOTA small 모델(각각 61%, 62%)과 유사한 성능을 보였다.
- 시선 추정 (Angle Error↓): MPII Gaze에서 2.56°의 오차로 SOTA(3.14) 및 OpenFace 2.0(9.1)을 능가했다. Gaze360에서도 SOTA(10.0)와 비슷한 10.6°를 기록했다.
- 감정 인식 (ACC↑): AffectNet에서 0.60의 정확도를 달성하여 SOTA small 모델(0.60)과 동일했다.
-
비교 결과:
- 효율성 (Table IV): OPENFACE 3.0은 29.4M의 파라미터를 가져 OpenFace 2.0(44.8M)보다 적다. CPU-only 처리 시간도 38ms로 OpenFace 2.0(75ms)보다 훨씬 빠르다.
- 비정면 얼굴 분석 (Table V): MTL의 핵심 이점을 보여준다. 감정 인식 SOTA 모델들은 얼굴 각도가 커질수록(>45°) 성능이 급격히 저하(57.41%)되지만, OPENFACE 3.0은 시선 추정 데이터(비정면 얼굴이 많음)로부터 학습한 공유 특징 덕분에 'Hard' 각도에서도 58.64%의 안정적인 성능을 유지하며 SOTA 모델을 능가했다.
결론
본 논문은 4가지 주요 안면 행동 분석 작업을 하나의 경량화된 다중 작업 시스템으로 통합한 OPENFACE 3.0을 제안했다. 이 시스템은 SOTA 모델들과 비슷하거나 더 나은 성능을 보이면서도 추론 속도와 메모리 효율성에서 큰 이점을 가진다. 특히, 다중 작업 학습을 통해 비정면 얼굴과 같은 'in-the-wild' 환경에서의 강인함(robustness)을 확보했다. OPENFACE 3.0은 사용하기 쉬운 Python API와 함께 오픈소스로 제공되어, 멀티모달 상호작용, 로보틱스, 감성 컴퓨팅 등 다양한 분야의 연구를 촉진할 것이다.