XGBoost: A Scalable Tree Boosting System
논문 정보
- 제목: XGBoost: A Scalable Tree Boosting System
- 저자: Tianqi Chen (University of Washington), Carlos Guestrin (University of Washington)
- 학회/저널: KDD '16 (The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining)
- 발행일: 2016-08-13
- DOI: 10.1145/2939672.2939785
- 주요 연구 내용: 본 논문은 확장 가능한 엔드투엔드 트리 부스팅 시스템인 XGBoost를 제안함. 희소 데이터를 효율적으로 처리하기 위한 새로운 희소성 인지 알고리즘(sparsity-aware algorithm)과 근사 트리 학습을 위한 가중치 분위 스케치(weighted quantile sketch)를 도입함. 또한, 캐시 접근 패턴, 데이터 압축, 샤딩(sharding)과 같은 시스템 최적화를 통해 확장성을 극대화함.
- 주요 결과 및 결론: XGBoost는 단일 머신에서 기존 솔루션보다 10배 이상 빠른 성능을 보이며, 분산 및 메모리 제한 환경에서도 수십억 개의 대용량 데이터를 훨씬 적은 리소스로 처리할 수 있음. 이러한 알고리즘과 시스템 최적화의 결합을 통해 실제 대규모 문제를 해결하는 강력한 솔루션 제공.
- 기여점: 고도로 확장 가능한 엔드투엔드 트리 부스팅 시스템을 설계 및 구축함. 병렬 트리 학습을 위한 새로운 희소성 인지 알고리즘과 효율적인 제안 계산을 위한 이론적으로 정당화된 가중치 분위 스케치를 제안함. 또한, 메모리 외부(out-of-core) 트리 학습을 위한 효과적인 캐시 인식 블록 구조를 도입하여 시스템 효율성을 높임.
요약
초록
트리 부스팅은 매우 효과적이고 널리 사용되는 머신러닝 방법이다. 이 논문에서는 XGBoost라는 확장 가능한 엔드투엔드 트리 부스팅 시스템을 설명한다. 이 시스템은 많은 데이터 과학자들이 머신러닝 챌린지에서 최첨단 결과를 달성하기 위해 널리 사용하고 있다. 희소 데이터를 위한 새로운 희소성 인지 알고리즘과 근사 트리 학습을 위한 가중치 분위 스케치를 제안한다. 더 중요하게는, 캐시 접근 패턴, 데이터 압축 및 샤딩에 대한 통찰력을 제공하여 확장 가능한 트리 부스팅 시스템을 구축한다.이러한 통찰력들을 결합함으로써 XGBoost는 기존 시스템보다 훨씬 적은 리소스를 사용하여 수십억 개의 예제를 넘어 확장된다.
서론
트리 부스팅은 분류, 랭킹 등 다양한 문제에서 최첨단 성능을 보이는 강력한 머신러닝 기법이다. 하지만 대용량 데이터셋에 대한 확장성 확보는 중요한 과제다. 이 논문에서는 이러한 문제를 해결하기 위해 확장 가능한 트리 부스팅 시스템인 XGBoost를 제안한다. XGBoost는 Kaggle과 같은 데이터 분석 대회에서 수많은 우승 솔루션에 채택될 만큼 그 성능과 영향력이 입증되었다.이러한 성공의 핵심 요인은 모든 시나리오에서의 확장성이며, 이는 여러 중요한 시스템 및 알고리즘 최적화를 통해 달성되었다.
모델 아키텍처 / 방법론
-
핵심 구조/방법: XGBoost는 경사 부스팅(Gradient Boosting) 프레임워크를 기반으로 하며, 여러 개의 결정 트리를 앙상블하여 예측을 수행한다. 모델은 손실 함수와 정규화 항을 포함하는 목적 함수를 최소화하는 방식으로 학습된다. 특히, 모델의 복잡도를 제어하고 과적합을 방지하기 위해 정규화 항을 추가한 것이 특징이다.학습은 이전에 학습된 모델의 잔차를 예측하는 새로운 트리를 반복적으로 추가하는 가산적(additive) 방식으로 진행된다.
-
주요 구성 요소:
- 정규화된 학습 목적 함수: 손실 함수 과 정규화 항 로 구성되며, 는 트리의 리프 개수 T와 리프 가중치 w의 L2 노름으로 모델의 복잡도를 제어한다.
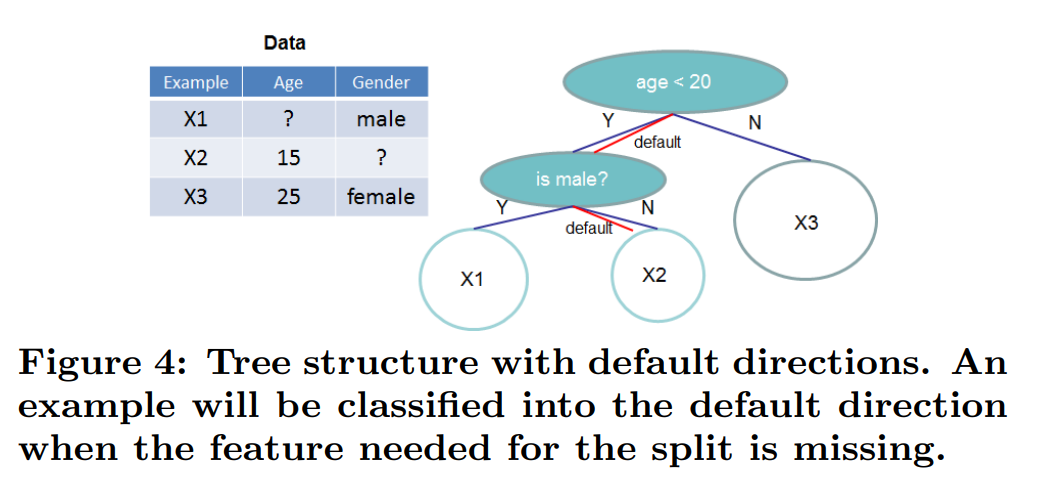
- 희소성 인지 분할 탐색 (Sparsity-aware Split Finding): 실제 데이터의 희소성(결측치, 0 값, 원-핫 인코딩 등)을 효율적으로 처리한다. 각 노드에 기본 방향(default direction)을 추가하여 결측치를 가진 인스턴스를 어느 쪽으로 보낼지 데이터로부터 학습한다. 이 방법은 연산 복잡도를 전체 데이터가 아닌 non-missing 엔트리 수에 비례하도록 만들어 속도를 크게 향상시킨다.논문의 Figure 4는 이 구조를 보여준다.
- 가중치 분위 스케치 (Weighted Quantile Sketch): 대용량 데이터셋에서 근사 분할(approximate split)을 찾을 때, 후보 분할점을 효율적으로 제안하기 위한 방법이다.손실 함수의 2차 미분값()을 각 데이터 포인트의 가중치로 취급하여, 가중치가 적용된 데이터 분포에서 분위수를 근사적으로 계산하는 새로운 알고리즘을 제안한다.
- 시스템 최적화:
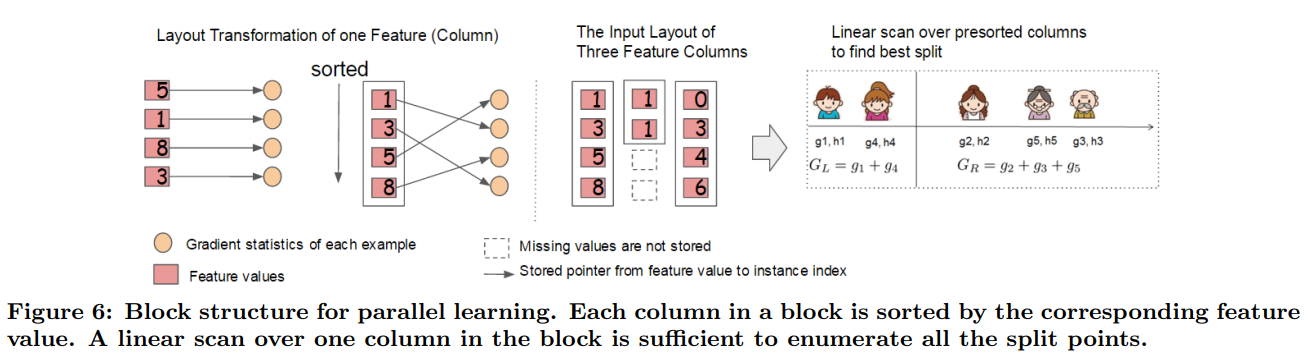
- 병렬 학습을 위한 컬럼 블록 (Column Block): 데이터를 메모리 내 '블록' 단위로 저장하며, 각 블록 내 데이터는 피처 값에 따라 정렬된 압축된 컬럼 형식(CSC)으로 저장된다. 이 구조는 한 번만 계산하면 반복적으로 재사용할 수 있어 정렬 비용을 크게 줄이고 병렬 처리를 용이하게 한다.논문의 Figure 6에서 이 구조를 시각적으로 설명한다.
- 캐시 인식 접근 (Cache-aware Access): 분할 탐색 시 발생하는 불연속적인 메모리 접근으로 인한 캐시 미스(cache miss) 문제를 해결하기 위해, 각 스레드에 내부 버퍼를 두고 데이터를 미리 가져오는(prefetching) 캐시 인식 알고리즘을 사용한다.
- Out-of-core 계산: 주 메모리에 담을 수 없는 대용량 데이터를 처리하기 위해 블록 압축과 블록 샤딩(여러 디스크에 데이터 분산) 기술을 사용한다.이를 통해 디스크 I/O 비용을 최소화하고 계산과 동시에 데이터를 로드하여 효율성을 극대화한다.
-
수식:
- 목적 함수: , 여기서
- 최적 리프 가중치:
- 구조 점수 (품질 평가): (Figure 2 참고)
- 분할 후 손실 감소량 (Gain):
실험 결과
- 주요 데이터셋: Allstate 보험 청구, Higgs Boson, Yahoo!LTRC, Criteo 클릭 로그 등 네 가지 대용량 데이터셋을 사용했다.
- 핵심 성능 지표:
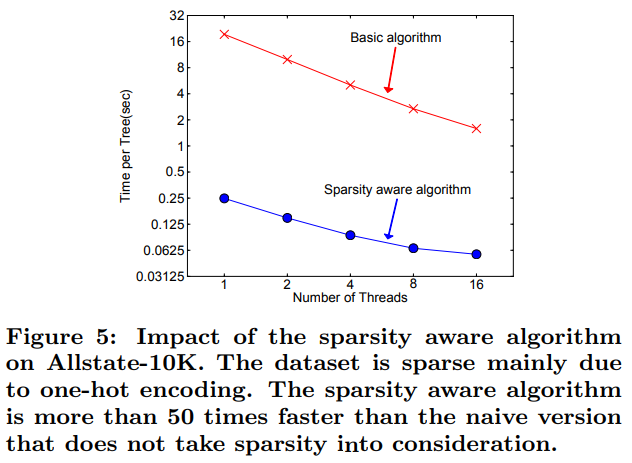
- 희소성 인지 알고리즘은 Allstate 데이터셋에서 순진한(naive) 구현보다 50배 이상 빠른 성능을 보였다(논문의 Figure 5).
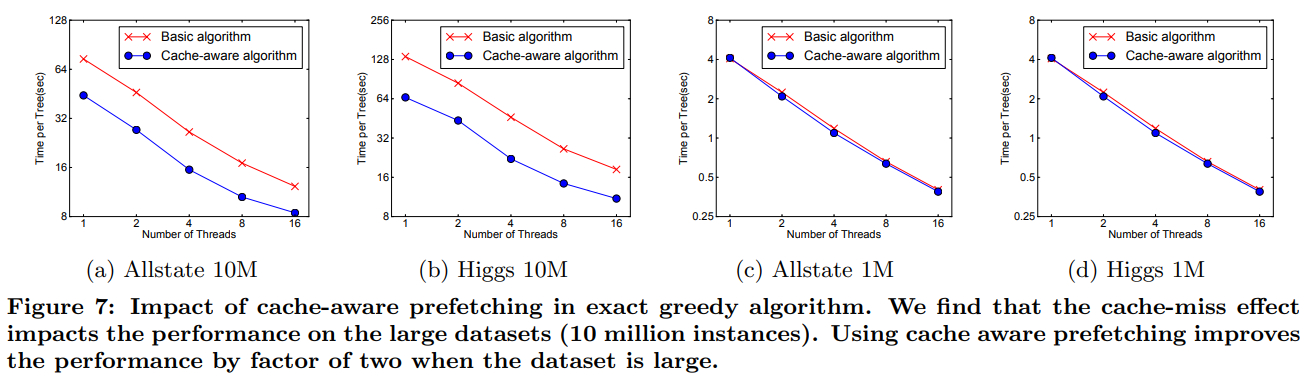
- 캐시 인식 알고리즘은 대용량 데이터셋(10M)에서 성능을 2배 향상시켰다(논문의 Figure 7).
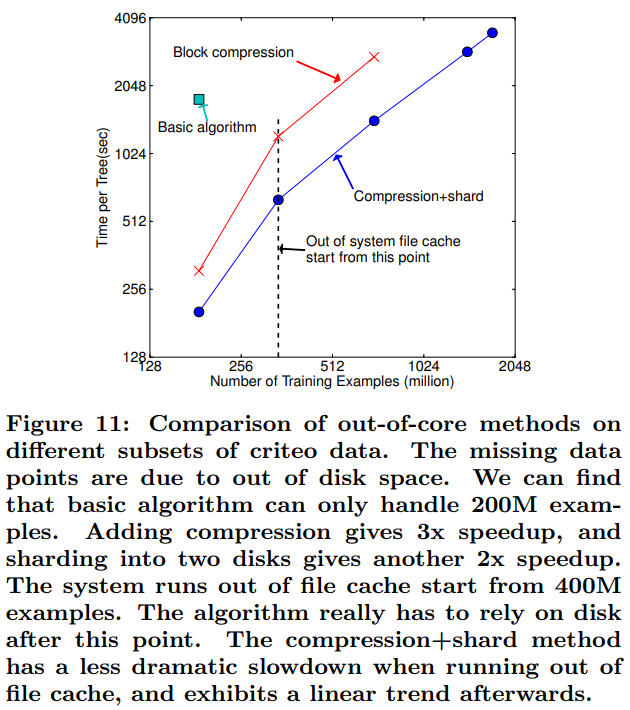
- Out-of-core 실험에서 블록 압축은 3배, 디스크 샤딩은 추가로 2배의 속도 향상을 가져와 단일 머신에서 17억 개의 데이터를 처리할 수 있었다(논문의 Figure 11).
- 비교 결과:
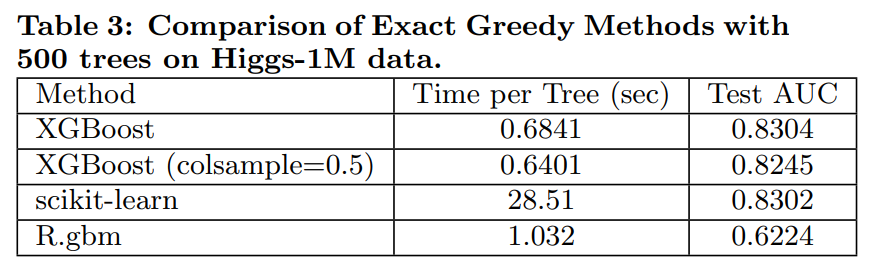
- 단일 머신 분류 문제(Higgs-1M)에서 XGBoost는 scikit-learn보다 10배 이상 빨랐으며 정확도는 유사했다 (Table 3).
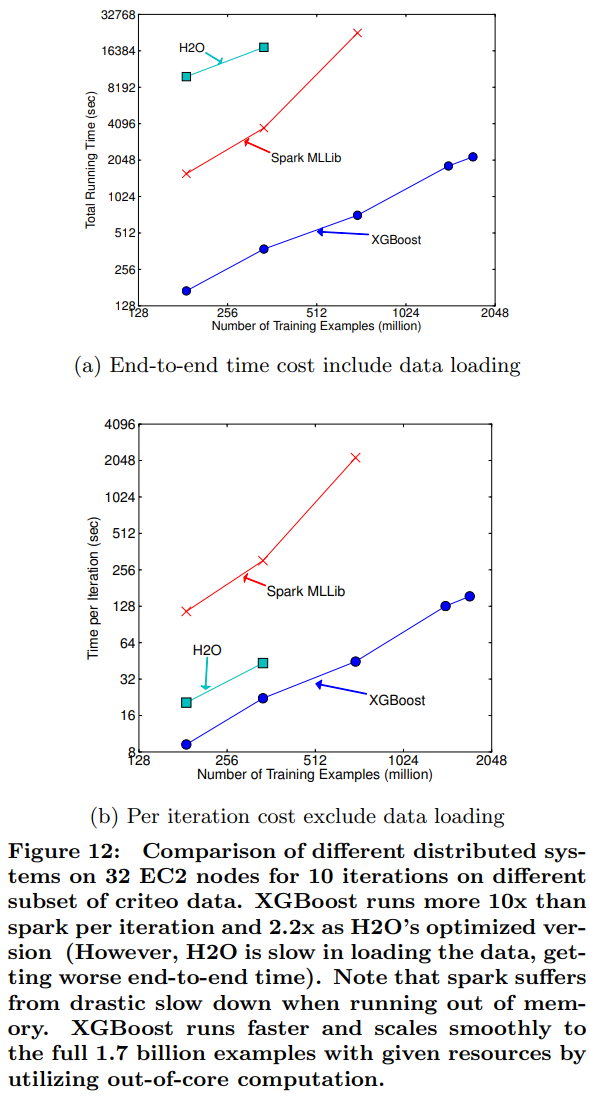
- 분산 환경(Criteo 데이터)에서 XGBoost는 Spark MLLib, H2O와 같은 인-메모리 프레임워크보다 더 빠르고, Out-of-core 기능을 활용하여 제한된 리소스에서도 17억 개의 전체 데이터를 원활하게 처리하며 뛰어난 확장성을 보였다(논문의 Figure 12).
결론
이 논문은 데이터 과학자들에게 널리 사용되며 많은 문제에서 최첨단 결과를 제공하는 확장 가능한 트리 부스팅 시스템인 XGBoost를 구축하면서 얻은 교훈을 설명했다. 희소 데이터 처리를 위한 새로운 희소성 인지 알고리즘과 근사 학습을 위한 이론적으로 정당화된 가중치 분위 스케치를 제안했다. 캐시 접근 패턴, 데이터 압축 및 샤딩과 같은 시스템 레벨의 최적화가 확장 가능한 엔드투엔드 시스템 구축에 필수적임을 보였다.이러한 통찰력들을 결합함으로써 XGBoost는 최소한의 리소스로 실제 대규모 문제를 해결할 수 있다.