데이터 불균형과 측정 오차를 고려한 생분해성 섬유 인장 강신도 예측 모델 개발
논문 정보
- 제목: The Development of Biodegradable Fiber Tensile Tenacity and Elongation Prediction Model Considering Data Imbalance and Measurement Error
- 저자: 박세찬, 김덕엽, 서강복, 이우진 (경북대학교 컴퓨터학부)
- 학회/저널: KIPS Transactions on Software and Data Engineering (정보처리학회논문지/소프트웨어 및 데이터 공학)
- 발행일: 2022-12-01
- DOI: 10.3745/KTSDE.2022.11.12.489
- 주요 연구 내용: 섬유 방사 공정 데이터의 특성(적은 양, 불균형, 샘플 간 오차)을 고려하여, 동일 방사 조건 클러스터 내 평균과의 거리를 기준으로 이상치를 처리하는 기법을 제안함. 또한, 여러 공정 변수와 예측 물성 간 상관계수 및 데이터 불균형 정도를 종합적으로 고려한 복합 데이터 증강 기법을 제안함.
- 주요 결과 및 결론: 제안한 이상치 처리 및 데이터 증강 기법을 적용했을 때, 기존 기법들(박스 플롯, CBLOF, ROS, SMOTE)보다 데이터 손실이 적고 불균형을 효과적으로 완화함. MLP 모델 기준, 인장 강도 예측에서 평균절대오차(MAE)는 약 27% 감소하고 조정된 결정계수()는 0.5 미만에서 약 0.8 수준으로 크게 개선됨.
- 기여점: 데이터 수집이 어려운 섬유 산업에서 발생하는 데이터 부족, 불균형, 측정 오차 문제를 해결하기 위한 맞춤형 데이터 전처리 기법을 제안함. 이를 통해 AI 예측 모델의 성능과 신뢰도를 향상시켜 공정 비용 절감 및 품질 최적화에 기여할 수 있는 실용적 방안을 제시.
요약
초록
노동 집약적인 섬유 산업에서 인공지능을 통해 공정 비용을 줄이고 품질을 최적화하려는 시도가 있으나, 데이터 수집 비용이 크고 체계가 부족하여 데이터의 양이 적고 불균형 문제가 발생한다. 또한, 동일 조건에서 수집된 샘플 간에도 측정 환경 차이로 오차가 존재한다. 이러한 데이터 특성을 고려하지 않으면 과적합 및 성능 저하가 발생할 수 있다. 본 논문은 방사 공정 데이터 특성을 고려한 이상치 처리 기법과 데이터 증강 기법을 제안하고, 기존 기법들과의 비교를 통해 제안 기법의 우수성을 입증한다.
서론
인공지능 모델의 성능은 데이터의 양과 질에 크게 좌우된다. 그러나 섬유 방사 분야는 데이터 수집 비용이 높아 충분한 양의 데이터 확보가 어렵고, 특정 목적에 따라 일부 변수만 변경하여 데이터를 수집하므로 데이터 불균형이 발생한다. 또한 동일 조건 샘플 간 측정 오차도 존재한다. 이러한 문제들을 해결하지 않고 모델을 학습하면 과적합 및 성능 저하가 발생하기 쉽다. 본 연구에서는 방사 공정 데이터의 특성을 고려한 맞춤형 이상치 처리 및 데이터 증강 기법을 제안하여 이 문제를 해결하고자 한다.
배경
기존 섬유 산업 연구는 주로 통계적 분석이나 수학적 모델링에 의존했으나, 이는 복잡한 비선형 관계를 분석하는 데 한계가 있었다. 인공지능을 적용한 소수의 연구는 데이터 부족으로 모델의 신뢰도가 낮았다. 일반적인 이상치 처리 기법은 데이터가 불균형할 경우 정상적인 소수 데이터를 이상치로 오탐지할 수 있다. 또한, 회귀 문제에서의 데이터 증강은 분류 문제와 달리 연속적인 변수의 구간별 불균형을 다루어야 하고, 특정 변수를 증강할 때 다른 변수의 불균형이 심화될 수 있는 문제를 고려해야 한다.
모델 아키텍처 / 방법론
- 핵심 구조/방법:
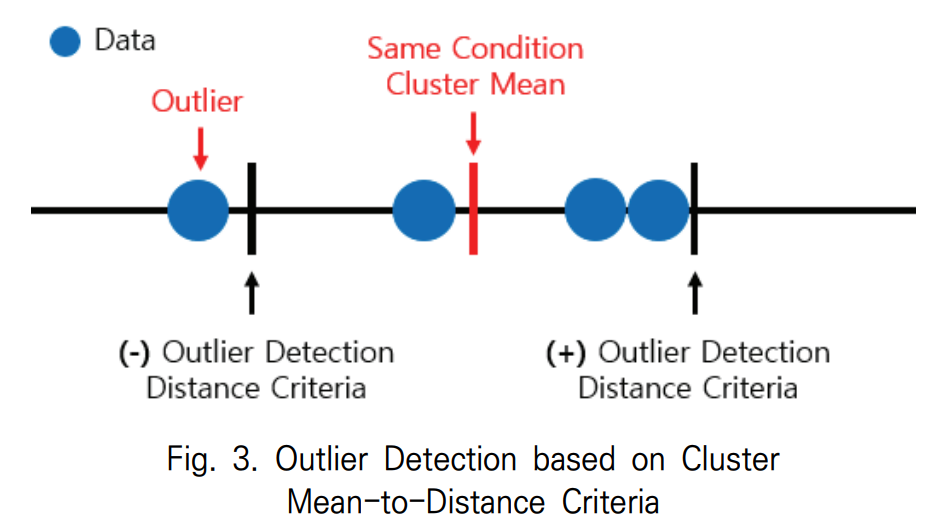
- 거리 기준 이상치 처리: 전체 데이터를 동일한 방사 조건을 기준으로 클러스터링한다. 각 클러스터 내에서 샘플들의 평균값을 계산하고, 이 평균값으로부터 사전에 정의된 '이상치 판단 거리 기준' 이상으로 벗어난 데이터를 이상치로 간주하여 제거한다. 이 방법은 논문의 Figure 3에서 시각적으로 설명된다.
- 복합 데이터 증강: 여러 변수에서 복합적으로 나타나는 데이터 불균형을 해결하기 위해, 각 주요 공정 변수가 예측 목표(인장 강도, 인장 신도)에 미치는 영향(상관계수)과 해당 변수의 데이터 불균형 정도를 모두 고려한다. 이를 바탕으로 데이터 증강의 우선순위와 증강 비율을 결정하여 소수 구간 데이터를 균형 있게 증강한다.
- 주요 구성 요소:
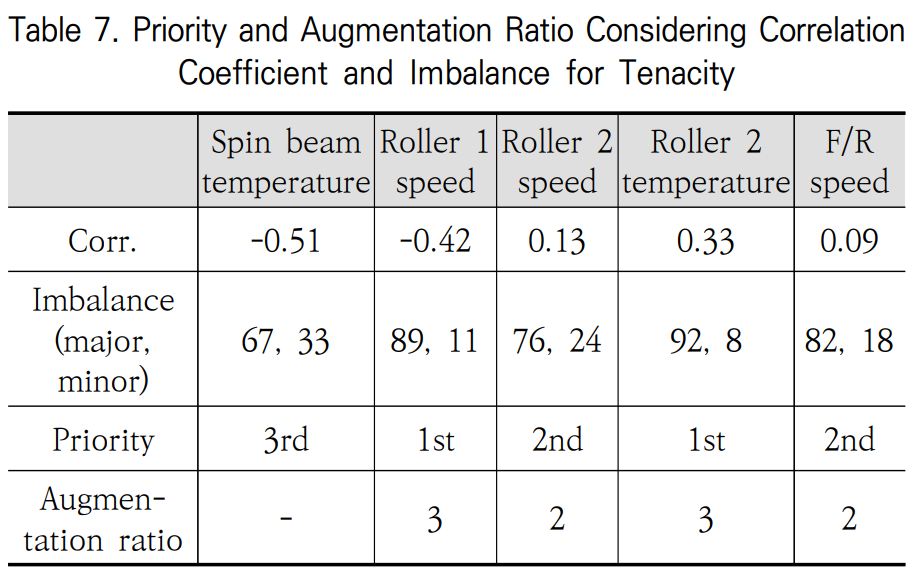
- 이상치 판단 거리 기준: 산업 현장의 공정관리한계 허용오차를 기반으로 실험을 통해 최적의 값을 설정했다. 인장 강도는
0.4, 인장 신도는4.5를 기준으로 사용했다. - 데이터 증강 우선순위: 상관계수와 불균형 정도를 종합적으로 고려하여 우선순위를 정한다. 예를 들어, 인장 강도 예측 시 롤러1 속도와 롤러2 온도가 1순위로, 스핀빔 온도가 3순위로 설정되었다 (논문의 Table 7 참조).
- 이상치 판단 거리 기준: 산업 현장의 공정관리한계 허용오차를 기반으로 실험을 통해 최적의 값을 설정했다. 인장 강도는
실험 결과
- 주요 데이터셋: 816개의 생분해성 섬유(PLA) 방사 공정 데이터를 사용했으며, 6개의 주요 공정 변수(스핀빔 온도, 롤러 속도 등)를 통해 인장 강도와 인장 신도를 예측했다.
- 핵심 성능 지표: 평균절대오차(MAE), 평균제곱오차(MSE), 조정된 결정계수(Adjusted ), 허용오차 내 예측치 비율을 사용했다.
- 비교 결과:
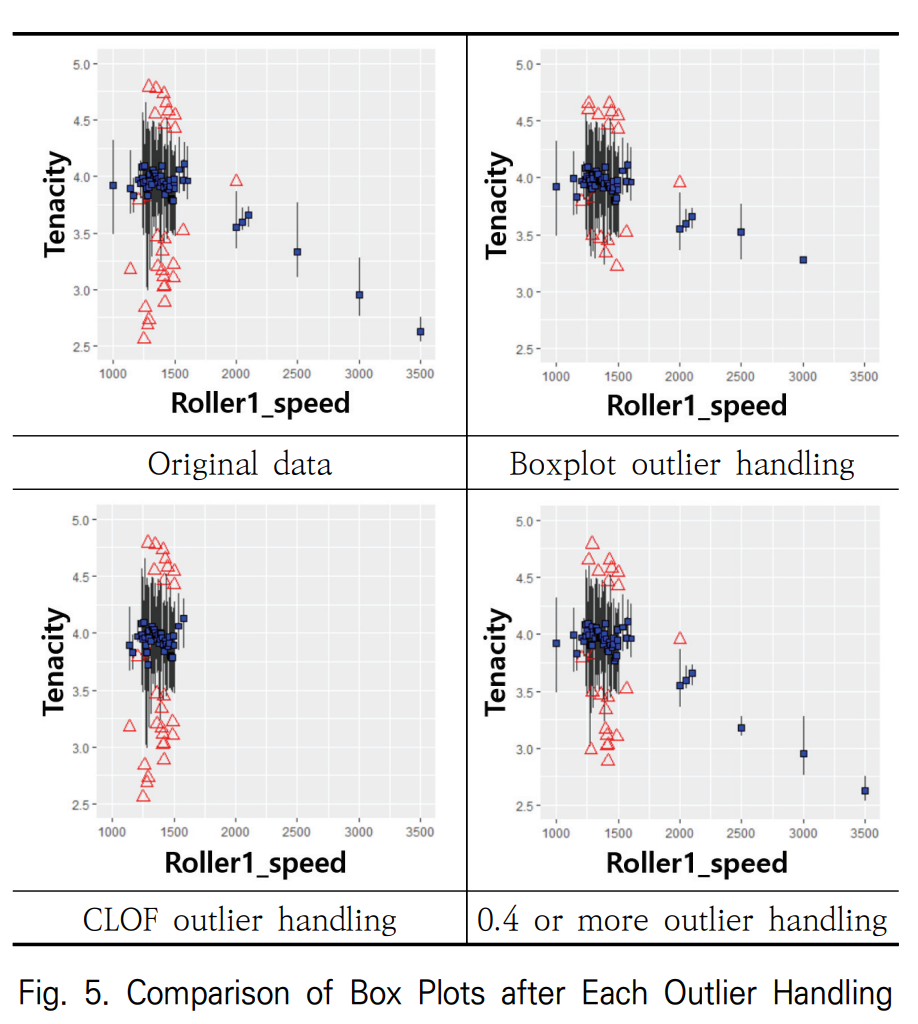
- 이상치 처리: 제안 기법은 박스 플롯이나 CBLOF 기법과 달리 정상적인 소수 구간 데이터를 보존하면서 이상치를 효과적으로 제거했다(논문의 Figure 5). 이를 통해 인장 강도 예측 MAE가 0.165에서 0.148로 개선되었다.
- 데이터 증강: 제안 기법은 ROS, SMOTE와 달리 다른 변수의 불균형을 악화시키지 않고, 소수 구간 내 데이터 불균형까지 완화했다 (롤러2 온도 소수 구간 내 데이터 비율이 7:1에서 3:2로 개선).
- 최종 모델 성능: 제안한 모든 전처리 기법을 적용한 결과, MLP 모델에서 인장 강도 예측 성능이 크게 향상되었다. MAE는 0.165에서 0.120으로 감소했고, 조정된 결정계수는 0.479에서 0.789로 개선되었다. 허용오차 내 예측 비율도 85.4%에서 92.4%로 증가했다.
결론
본 연구는 생분해성 섬유 방사 공정 데이터의 고질적인 문제인 데이터 부족, 불균형, 샘플 간 오차를 해결하기 위한 맞춤형 데이터 전처리 기법을 제안했다. 제안한 이상치 처리 및 복합 데이터 증강 기법은 기존 기법들보다 방사 공정 데이터에 더 적합하며, 인장 강신도 예측 모델의 성능을 유의미하게 개선함을 실험적으로 입증했다. 구체적으로 MLP 모델에서 MAE는 약 27% 감소했고, 결정계수는 0.8에 가까운 수준으로 향상되었다. 이는 데이터 특성을 고려한 적절한 전처리가 인공지능 모델의 성능 개선에 매우 중요하다는 것을 시사한다.