논문 정보
- 제목: Robot Behavior-Tree-Based Task Generation with Large Language Models
- 저자: Yue Cao, C.S. George Lee (Purdue University)
- 학회/저널: arXiv (Preprint), AAAI-MAKE 2023 Proceedings
- 발행일: 2023-02-24
- DOI: -
- 주요 연구 내용: 사전 학습된 대규모 언어 모델(LLM)을 활용하여 로봇 작업을 위한 행동 트리(Behavior Tree)를 생성하는 방법을 제안한다. 3계층 구조 생성을 위한 'Phase-Step 프롬프트'와 지식 기반(Knowledge Base)에서 유사한 작업을 검색하여 프롬프트를 구성하는 자동화 파이프라인을 제시한다.
- 주요 결과 및 결론: 제안된 방법은 GPT-3 및 ChatGPT를 통해 다양한 도메인의 작업(예: 컴퓨터 조립)을 생성하는 데 성공했다. 특히 Phase-Step 프롬프트를 사용했을 때 단순 프롬프트 대비 행동 트리의 구조적 모듈성을 훨씬 잘 유지함을 확인했다.
- 기여점: LLM을 행동 트리 생성에 적용한 최초의 시도로, 고정된 기본 작업(primitive tasks) 집합에 얽매이지 않고 새로운 도메인의 로봇 작업을 생성할 수 있는 일반화된 방법을 제시했다.
행동 트리(Behavior Tree)는 모듈성과 재사용성 덕분에 로봇 작업 표현 방식으로 인기를 얻고 있다. 그러나 수동으로 행동 트리를 설계하는 것은 시간이 많이 소요되며, 기존의 자동 생성 방식은 고정된 기본 작업(primitive tasks)에 의존하여 새로운 도메인으로의 확장이 어렵다. 본 논문은 최신 대규모 언어 모델(LLM)을 활용한 새로운 행동 트리 기반 작업 생성 접근 방식을 제안한다. 계층적 구조 생성을 가능하게 하는 'Phase-Step 프롬프트'를 설계하고, 행동 트리 임베딩 기반 검색을 통합하여 적절한 프롬프트를 자동으로 설정한다. 이를 통해 사전 정의된 기본 작업 집합 없이도 추상적인 작업 설명만으로 행동 트리를 신속하게 생성할 수 있음을 보여준다.
행동 트리는 로봇 작업을 제어 흐름 노드(control-flow nodes)를 사용하여 조정하는 그래픽 표현 방식으로, 상태 머신(state machine) 등에 비해 모듈성과 가독성이 뛰어나다. 기존 연구들은 LTL 사양이나 PDDL 플래너를 통해 행동 트리를 생성하려 했으나, 이는 사전에 정의된 도메인 내의 작업 라이브러리에 의존한다는 한계가 있었다. 본 연구는 GPT-3와 같은 LLM의 강력한 일반화 능력을 활용하여 이러한 한계를 극복하고자 한다. 로봇 작업 생성 문제를 프롬프트 기반 학습 패러다임으로 재정의하고, 순차적 작업(sequential tasks) 생성을 넘어 모듈화된 행동 트리 구조를 생성하는 것을 목표로 한다.
행동 트리는 Directed Rooted Tree 형태로 정의되며, 실행을 담당하는 리프 노드(Action, Condition)와 제어 흐름을 담당하는 브랜치 노드(Sequence, Fallback 등)로 구성된다. LLM 분야에서는 소수 샷(few-shot) 학습 능력을 활용한 '프롬프트 기반 학습'이 대두되었다. 본 연구는 입력 텍스트를 템플릿화하여 LLM이 기존 지식을 바탕으로 원하는 구조의 출력을 생성하도록 유도한다.
모델 아키텍처 / 방법론
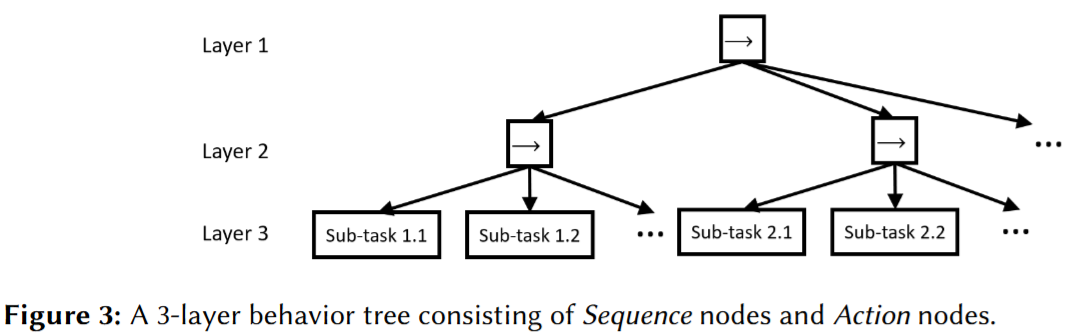 1. Phase-Step 프롬프트 (Phase-Step Prompt)
3계층 행동 트리(Root → Phase → Step)를 생성하기 위한 프롬프트 설계다. Figure 3에서 보여지는 구조를 텍스트 형태로 변환하여 입력한다. 'Source Task'에 예시 작업 절차를 Phase와 Step으로 구분하여 제공하고, 'Target Task'에 원하는 작업 설명을 입력하여 LLM이 동일한 구조로 출력을 생성하도록 유도한다.
1. Phase-Step 프롬프트 (Phase-Step Prompt)
3계층 행동 트리(Root → Phase → Step)를 생성하기 위한 프롬프트 설계다. Figure 3에서 보여지는 구조를 텍스트 형태로 변환하여 입력한다. 'Source Task'에 예시 작업 절차를 Phase와 Step으로 구분하여 제공하고, 'Target Task'에 원하는 작업 설명을 입력하여 LLM이 동일한 구조로 출력을 생성하도록 유도한다.
2. 행동 트리 구성 (Behavior-Tree Construction)
생성된 3계층 구조의 하위 작업(sub-task)들이 로봇이 수행 가능한 기본 동작(primitive)인지 확인하고 확장하는 과정이다.
- 동사 유사도 측정: 로봇의 기본 동사 목록 L과 하위 작업의 동사 v 간의 유사도를 측정한다. 이를 위해 언어 임베딩 모델 Enc1()을 사용하여 다음과 같은 각도-코사인 유사도(angular-cosine similarity)를 계산한다.
Sim(v,Li)=1−π2arccos(∥Enc1(v)∥∥Enc1(Li)∥Enc1(v)⋅Enc1(Li))
유사도가 임계값 미만일 경우, 해당 하위 작업을 다시 LLM에 입력하여 더 세분화된 트리로 확장(Decomposition)한다.
- 예외 처리: "안정성을 위해(for stability)"와 같은 추가 사양이 있는 경우, Fallback 노드와 Condition 노드를 삽입하여 구조를 보강한다.
 3. 자동 소스 작업 선택 (Automatic Source-Task Selection)
프롬프트에 사용할 가장 적절한 'Source Task'를 지식 기반(Knowledge Base)에서 자동으로 검색한다.
3. 자동 소스 작업 선택 (Automatic Source-Task Selection)
프롬프트에 사용할 가장 적절한 'Source Task'를 지식 기반(Knowledge Base)에서 자동으로 검색한다.
- 행동 트리 임베딩: 타겟 작업 설명(vtarget)과 지식 기반 내의 행동 트리들(ui) 간의 유사도를 계산하여 가장 유사한 트리를 템플릿으로 선택한다.
Sim(target,BTi)=∥vtarget∥∥ui∥vtarget⋅ui
- 전체 파이프라인은 논문의 Figure 4에 도식화되어 있으며, 타겟 설명 → 유사 소스 검색 → 프롬프트 구성 → LLM 생성 → 행동 트리 완성의 흐름을 따른다.
실험 결과
1. 실험 설정
GPT-3 (text-davinci-003)와 ChatGPT를 사용하여 실험을 진행했다. 자동차 휠 조립 작업을 소스 작업으로 사용하여 "데스크탑 조립"이라는 타겟 작업을 생성하는 과정을 시연했다.
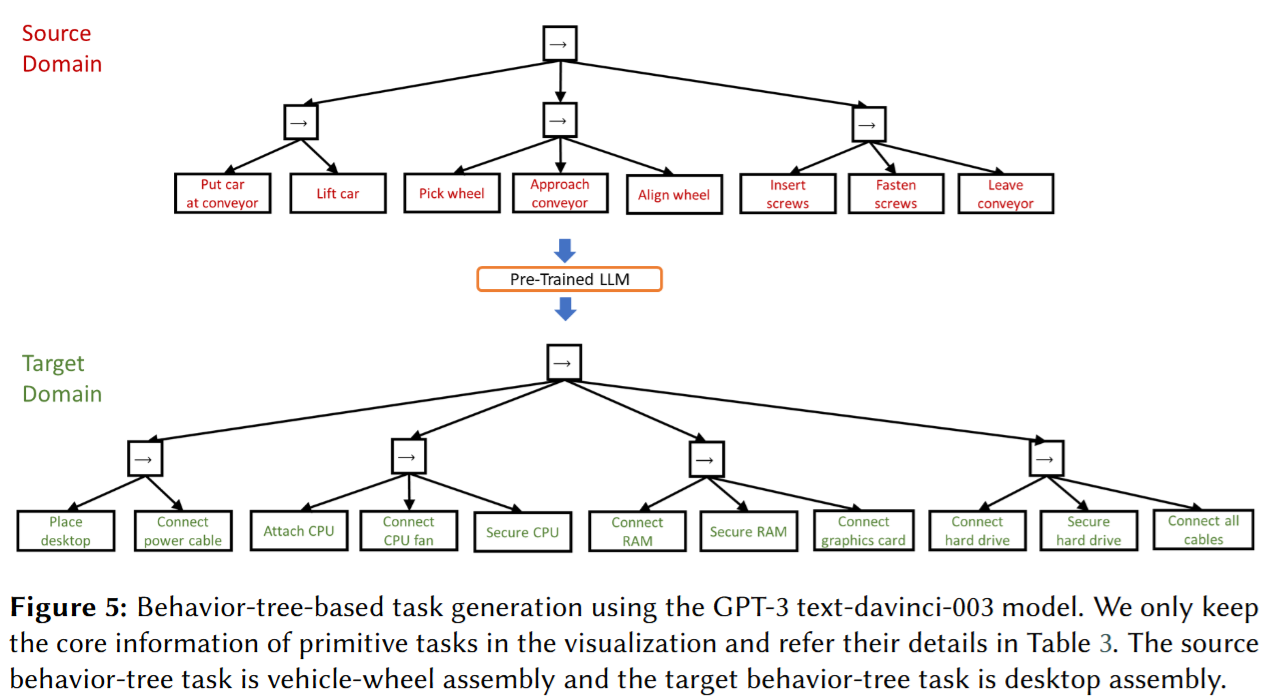 2. 전체 프로세스 시연
2. 전체 프로세스 시연
- Table 3와 Figure 5에 따르면, GPT-3는 4개 페이즈 11개 스텝의 구조적인 작업을 생성했으며, ChatGPT는 3개 페이즈 8개 스텝을 생성했다.
- 동사 유사도 검사 결과, ChatGPT가 생성한 "install" 동사는 로봇의 기본 동작이 아니라고 판단되어, 이를 다시 1개의 페이즈로 분해하는 과정(Table 4)을 거쳐 구체적인 동작(pick, place 등)으로 변환했다.
3. 절제 연구 (Ablation Study)
Phase-Step 프롬프트의 효과를 검증하기 위해 구조화되지 않은 일반 프롬프트(PS-none)와 비교했다.
- 구조 비율(Structure Ratio, R): 트리의 균형을 측정하기 위해 R=Nmin/Nmax (두 번째 레이어의 최소 자식 노드 수 / 최대 자식 노드 수)라는 지표를 정의했다.
- 결과: Table 6에 따르면, PS-none 프롬프트는 R 값이 0에 가까워 순차적(sequential) 작업에 가까웠으나, Phase-Step 프롬프트는 R 값이 0.6 이상으로 소스 작업의 트리 구조를 잘 보존했다.
4. 조립 작업 평가
부품 결합(part-mating) 작업의 수를 지표(Nmate)로 사용하여 평가했다. 더 상세한 소스 프롬프트(PS-desktop)를 사용했을 때 생성된 결과물에도 더 많은 결합 작업이 포함되어, 프롬프트의 상세도가 생성된 작업의 품질에 영향을 미침을 확인했다.
본 연구는 생성형 AI 기술을 로봇 공학의 행동 트리 설계에 접목하여, 엔드 유저의 작업 설계 부담을 줄이고 도메인 간 작업 전이를 가능하게 했다. 생성된 작업이 합리적이고 실행 가능해 보이지만, 복잡한 공장 환경이나 엄격한 안전 규정을 작업 생성 과정에 어떻게 통합할지는 향후 과제로 남아있다. 또한, LLM이 학습 데이터에 없는 매우 희귀한 작업(예: 빈스 롬바르디 트로피 제작)이나 특정 로봇 하드웨어(Atlas 로봇)의 세부 사항을 처리하는 데에는 한계가 있음을 확인했다.