생분해성 섬유 방사 공정 데이터 특성을 고려한 물성 예측 모델 개발
논문 정보
- 제목: 생분해성 섬유 방사 공정 데이터 특성을 고려한 물성 예측 모델 개발 (The Development of Property Prediction Model in Consideration of Biodegradable Fiber Spinning Process Data Characteristics)
- 저자: 박세찬, 김덕엽, 서강복, 이우진 (경북대학교 컴퓨터학부)
- 학회/저널: ASK 2022 학술발표대회 논문집
- 발행일: 2022-01-01
- DOI: 제공되지 않음
- 주요 연구 내용: 섬유 방사 공정 데이터는 양이 적고 분포가 불균형하며, 동일 조건 샘플 간에도 오차가 존재하는 특성이 있음. 본 논문은 이러한 특성을 반영하여, 물성 단위와 허용오차를 고려한 이상치 처리 기법과 데이터 불균형 정도 및 물성과의 상관성을 고려한 오버샘플링 기법을 제안함.
- 주요 결과 및 결론: 제안된 데이터 전처리 기법들을 MLP 모델에 적용한 결과, 조정된 결정계수는 0.479에서 0.789로 크게 향상되었고, 평균절대오차는 0.165에서 0.120으로 약 27% 감소함. 이를 통해 모델의 데이터 적합도와 예측 정확성이 크게 개선되었음을 확인함.
- 기여점: 데이터 확보가 어려운 섬유 방사 공정의 현실적인 문제를 해결하기 위해 도메인 지식(공정관리한계 허용오차)을 활용한 데이터 처리 기법을 제안함. 데이터 불균형과 상관성을 동시에 고려한 오버샘플링을 통해 물성 예측 모델의 성능을 실질적으로 개선하여 AI 기술의 현장 적용 가능성을 높임.
요약
초록
섬유 산업에서 AI를 활용하여 공정 시간과 비용을 절감하려는 시도가 있으나, 섬유 방사 공정은 데이터 수집 비용이 크고 데이터 양이 적으며 불균형 문제가 심각하다. 또한 동일 조건에서 수집된 샘플 간에도 오차가 존재하여 AI 모델 적용 시 과적합 및 성능 저하를 유발할 수 있다. 본 연구에서는 이러한 데이터 특성을 해결하기 위해 물성 단위 및 허용오차를 고려한 이상치 처리 기법과 데이터 불균형 정도 및 상관성을 고려한 오버샘플링 기법을 제안하고, 이를 통해 물성 예측 오차와 모델 적합도가 개선됨을 보인다.
서론
섬유 산업은 제품 품질 향상 및 공정 최적화를 위해 AI 도입을 시도하고 있으나, 데이터 확보의 어려움이 큰 장벽이다. 방사 공정 데이터는 수집 비용이 높아 데이터 양이 절대적으로 부족하고, 특정 목적에 따라 데이터를 수집하므로 변수 분포가 불균형하다. 더불어 측정 환경의 차이로 인해 샘플 간 오차도 발생한다. 이러한 데이터 문제를 해결하기 위해, 본 논문에서는 데이터 특성을 고려한 이상치 처리 및 오버샘플링 기법을 제안하여 물성 예측 모델의 성능을 개선하고자 한다.
배경
기존 섬유 산업 연구는 주로 통계적 분석이나 수학적 모델링에 의존했으나, 이는 복잡한 비선형 관계를 설명하기 어려웠다. AI를 적용한 초기 연구도 매우 적은 데이터로 인해 모델의 신뢰도가 낮았다. 일반적인 이상치 탐지 기법은 데이터가 불균형할 경우 소수 구간 데이터를 이상치로 오판할 수 있으며, 기존 오버샘플링 기법들은 대부분 분류 문제를 대상으로 하므로 연속적인 변수를 다루는 회귀 문제에 직접 적용하기 어렵다.
모델 아키텍처 / 방법론
- 데이터: 총 816개의 생분해성 섬유 방사 공정 데이터를 사용한다. 55개의 공정 변수 중 인장강도에 영향을 미치는 6개의 주요 공정 변수를 선택하여 분석에 활용한다.
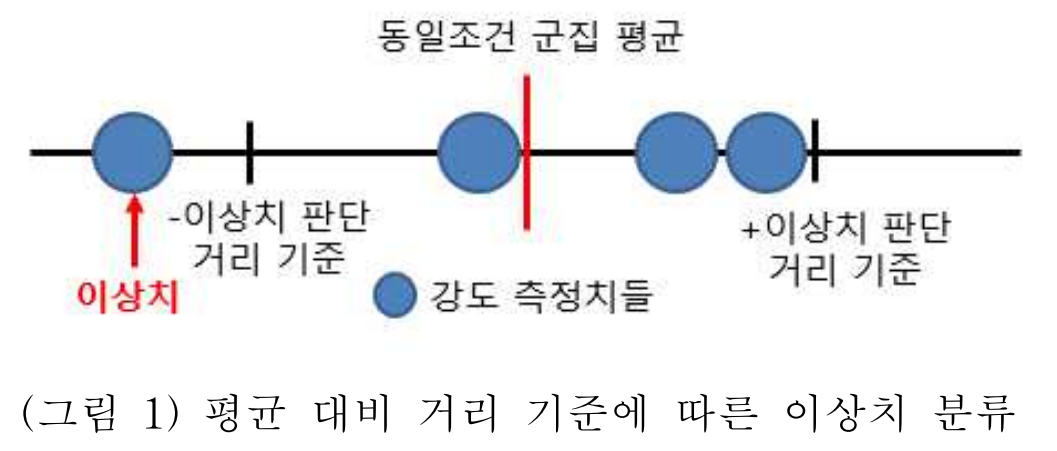
- 이상치 처리: 일반적인 이상치 탐지 기법의 한계를 극복하기 위해, 동일한 방사 조건으로 데이터를 군집화하고 각 군집 내에서 평균값과의 거리를 기준으로 이상치를 판별한다. 논문의 Figure 1에서 이 과정을 시각적으로 설명한다. 산업 현장의 공정관리한계 허용오차(0.3)를 참고하여, 실험을 통해 이상치 판단 거리 기준을 0.4로 설정하고 총 20개의 이상치를 제거함.
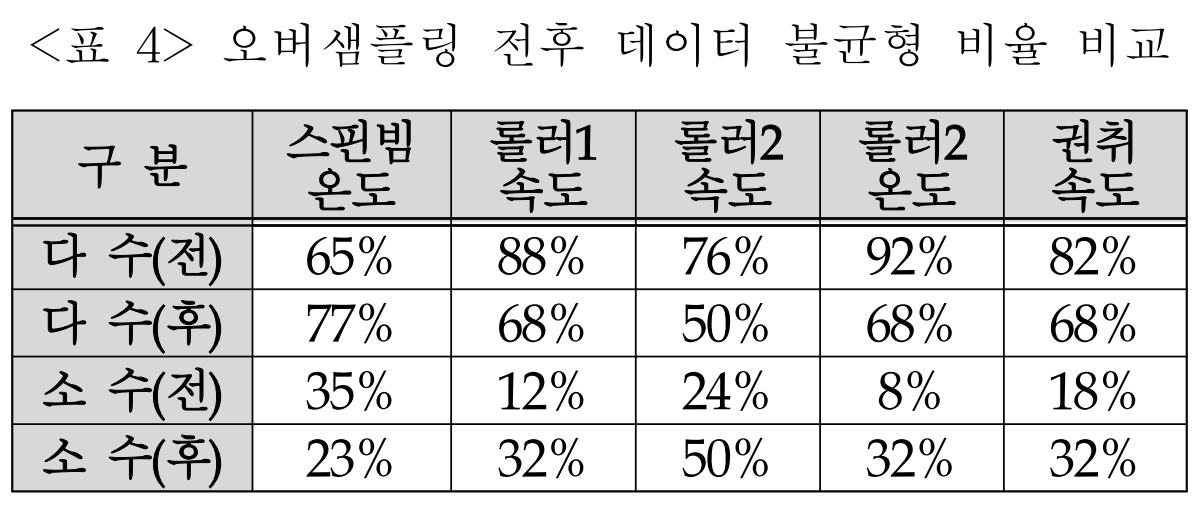
- 오버샘플링: 데이터 불균형 문제와 데이터 양 부족 문제를 해결하기 위해, 각 변수의 불균형 정도와 예측 목표인 '강도'와의 상관계수를 함께 고려하여 오버샘플링을 수행한다. 예를 들어, 상관계수가 크고 불균형이 심한 '롤러1 속도'와 '롤러2 온도'는 소수 구간 데이터를 3배 증강하고, 상대적으로 영향이 적은 변수는 2배 증강하는 차등적 방식을 적용한다. 이 과정을 통해 데이터는 1193개로 증가하였고, 주요 변수들의 데이터 불균형이 완화되었다(Table 4 참조).
실험 결과
-
주요 데이터셋 및 모델: 제안한 기법들의 성능을 검증하기 위해 (1)기본 데이터, (2)이상치 처리 데이터, (3)이상치 처리 후 오버샘플링 데이터를 각각 사용하여 MLP(Multi-Layer Perceptron) 모델을 학습함.
-
핵심 성능 지표: 모델 성능은 조정된 결정계수(), 평균절대오차(MAE), 평균제곱오차(MSE)로 평가함.
-
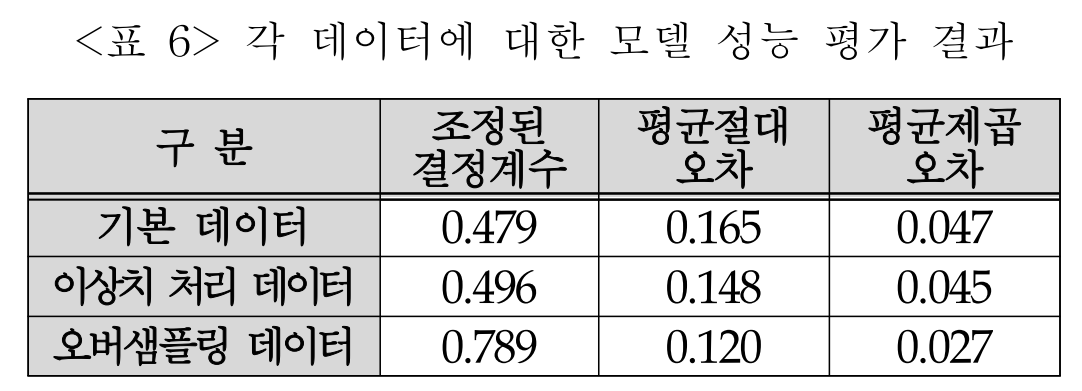
비교 결과: 실험 결과는 논문의 Table 6에 요약되어 있다.
- 조정된 결정계수: 기본 데이터에서 0.479였던 값이 오버샘플링 후 0.789로 크게 상승하여 모델이 데이터를 훨씬 잘 설명하게 된다.
- 예측 오차: 평균절대오차(MAE)는 0.165에서 0.120으로, 평균제곱오차(MSE)는 0.047에서 0.027로 감소하여 예측 정확성이 향상되었다.
- 분석: 이상치 처리만으로도 약간의 성능 향상이 있었지만, 오버샘플링을 적용했을 때 성능이 대폭 개선되어 데이터의 양과 분포가 모델 성능에 결정적인 영향을 미침을 확인하였다.
결론
본 연구는 섬유 방사 공정 데이터가 가지는 소량, 불균형, 샘플 간 오차라는 고유한 특성을 고려한 데이터 전처리 기법을 제안한다. 제안한 이상치 처리 및 오버샘플링 기법을 적용한 결과, 물성 예측 모델의 예측 오차는 약 27%(MAE 기준) 감소했고, 데이터 적합도를 나타내는 결정계수는 0.8에 가깝게 개선되었다. 이는 AI 모델 개발 시 데이터 특성에 맞는 적절한 전처리 기법을 적용하는 것이 모델 성능 개선에 매우 중요함을 시사한다.