Identifying Bug Inducing Commits by Combining Fault Localisation and Code Change Histories
논문 정보
- 제목: Identifying Bug Inducing Commits by Combining Fault Localisation and Code Change Histories
- 저자: Gabin An (KAIST), Jinsu Choi (KAIST), Jingun Hong (SAP Labs Korea), Naryeong Kim (KAIST), Shin Yoo (KAIST)
- 학회/저널: arXiv (Extended version of ICSE 2023 paper)
- 발행일: 2025-02-19 (v2)
- DOI: 10.1109/ICSE48619.2023.00059 (Original ICSE 2023 paper)
- 주요 연구 내용: 코드 요소의 결함 의심 점수(Fault Localisation)와 코드 변경 이력(Version Control)을 결합하여 버그 유발 커밋(BIC)의 가능성을 정량화하는 'FONTE' 기법 제안. FONTE는 3단계(필터링, 의미 보존 커밋 제거, 점수화)를 통해 BIC 탐색 공간을 줄이고 순위를 매김.
- 주요 결과 및 결론: 206개 실제 BIC 대상 평가 결과, FONTE는 기존 IR 기반 BIC 식별 기법 대비 최대 45.8% 높은 MRR을 달성. 또한 FONTE 점수를 활용한 '가중 이진 탐색(Weighted Bisection)'은 표준 이진 탐색 대비 탐색 반복 횟수를 98%의 사례에서 감소시킴.
- 기여점: 버그 리포트나 버그 수정 커밋(BFC) 없이, 테스트 실패 정보(커버리지)와 커밋 이력만으로 BIC를 식별하는 효율적이고 유연한 비지도 방식 제안. 대규모 산업 프로젝트(SAP HANA)의 배치 테스팅 실패 시나리오에 적용하여 실용성 입증.
요약
초록
버그 유발 커밋(BIC)은 코드베이스에 버그를 도입하는 코드 변경이다. 프로그램 실패가 관찰되었을 때 관련 BIC를 식별하면 버그 해결 프로세스에 큰 도움이 된다. 하지만 기존 BIC 식별 기법은 한계가 있다. 이진 탐색(Bisection)은 계산 비용이 높고, 다른 기법들은 버그 리포트나 버그 수정 같은 사후 정보에 의존한다. 본 논문은 'FONTE'라는 기법을 제안한다. 핵심 아이디어는, 버그를 포함할 가능성이 높은(의심스러운) 코드 요소를 '최근에' 수정한 커밋일수록 BIC일 확률이 높다는 것이다. FONTE는 결함 위치 파악(FL) 기법을 통한 '실패-코드' 관계와 버전 관리 시스템의 '코드-커밋' 관계를 활용한다. 206개의 실제 BIC를 사용한 평가에서 FONTE는 기존 SOTA 기법보다 최대 45.8% 높은 MRR을 달성했다. 또한 FONTE의 순위 점수를 활용한 '가중 이진 탐색(Weighted Bisection)'과 대규모 산업 프로젝트(SAP HANA) 적용 사례를 보고하며, 87%의 실패 사례에서 실제 BIC를 상위 5위 내에 랭크시켰다.
서론
CI/CD 환경에서는 다수의 커밋이 지속적으로 통합된다. 이때 프로그램 실패(테스트 실패 또는 필드 실패)가 발생하면 버그 해결 프로세스가 시작된다. 이 과정에서 실패의 원인이 되는 버그 유발 커밋(BIC)을 아는 것은 매우 유용하다. BIC 정보는 버그 담당자 할당을 효율화하고 (버그 도입 개발자가 78%를 수정함), 자동/수동 디버깅 활동을 지원하며, 배치 테스팅(Batch Testing) 시나리오에서 테스트 비용을 절감시킨다. 기존 기법인 이진 탐색(Bisection)은 빌드/테스트 비용이 크고, 정보 검색(IR) 기반 기법은 버그 리포트의 품질에 의존하며 복잡한 실패 동작을 포착하기 어렵다. 본 연구는 디버깅 단계에서 사용 가능하며 효율적이고 유연한 비지도 BIC 식별 접근법인 FONTE를 제안한다.
배경
본 연구의 목표는 테스트 실패 관찰 직후, 디버깅 시작 시점에 가용한 정보(주로 실패한 테스트 케이스)만을 사용해 BIC를 정확히 식별하는 것이다. 이전 연구에서 실패한 테스트의 커버리지(Failure Coverage)만으로도 BIC 탐색 공간을 평균 12.4%로 줄일 수 있음을 보였다. FONTE는 이 탐색 공간 축소를 기반으로, '실패-코드' 관계(FL 기법)와 '코드-커밋' 관계(변경 이력)를 결합하여 '실패-커밋' 관계를 도출한다.
모델 아키텍처 / 방법론
FONTE는 3단계 프로세스를 통해 BIC를 식별한다. (논문의 Figure 2 참조)
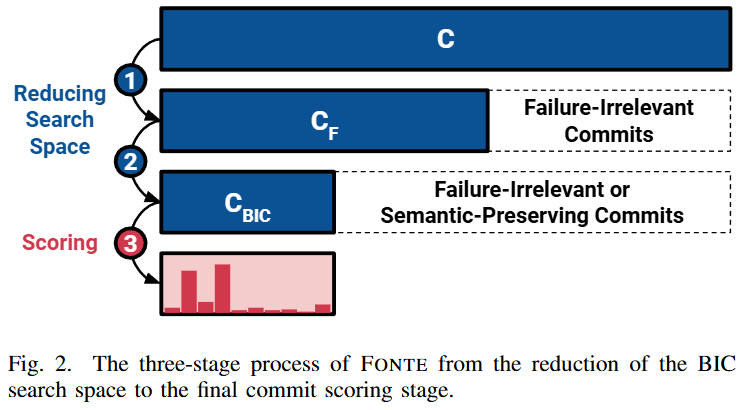
-
1단계: 실패-무관 커밋 필터링 (Filtering Out Failure-Irrelevant Commits)
- 실패한 테스트 케이스()가 커버하는 코드 요소 집합()을 식별한다.
- 에 속한 코드 요소의 변경 이력(Evolve 관계)에 포함되는 커밋 집합()을 식별한다.
- 에 속하지 않는 커밋은 실패와 무관하므로 탐색 공간에서 제외한다.
-
2단계: 의미 보존 커밋 필터링 (Filtering Out Semantic-Preserving Commits)
- 내에서 주석 변경, 코드 포맷팅 등 기능적 동작을 변경하지 않는 '의미 보존(semantic-preserving)' 커밋을 식별한다.
- 파일 레벨 AST(Abstract Syntax Tree) 비교를 사용해 커밋 전후의 AST가 동일한지 확인하여 이를 필터링한다.
- 최종 BIC 후보 집합 를 도출한다.

-
3단계: 커밋 점수화 (Scoring Commits)
- 핵심 직관: 실패에 더 의심스러운 코드 요소를 수정/생성한 커밋이 BIC일 가능성이 높다.
- 코드 요소의 의심 점수()는 SBFL(예: Ochiai)이나 IRFL(예: Blues) 같은 기존 FL 기법으로 계산한다.
- 순위 기반 투표력 (Rank-based Voting Power): 원시 FL 점수 대신 순위를 사용해 투표력을 계산. 이는 점수 편차보다 상대적 순위가 더 유용하다는 관찰에 기반한다. (여기서 는 점수 사용 여부, 는 순위 동점 처리 방식(max/dense) 하이퍼파라미터)
- 깊이 기반 감쇠 (Depth-based Decay): 오래된 커밋은 이미 발견/수정되었을 가능성이 높다는 가정하에, 코드 요소 에 대해 더 최신 커밋()이 존재하면(), 해당 커밋 의 투표 영향력을 감소시킨다.
- 최종 커밋 점수: (논문의 Figure 4에 예시)
(는 감쇠 인자(decay factor))

-
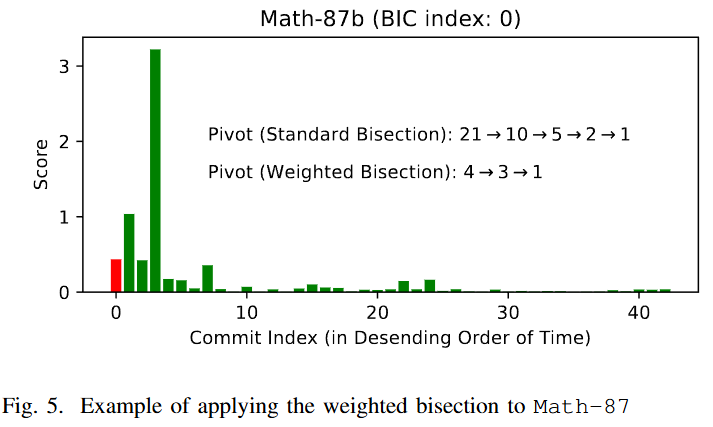
가중 이진 탐색 (Weighted Bisection)
- 표준 이진 탐색은 커밋 목록의 중간 지점을 피벗(pivot)으로 선택한다.
- 가중 이진 탐색(Algorithm 1)은 FONTE 점수를 가중치로 사용하여, 남은 '점수의 합'이 절반이 되는 지점을 피벗으로 선택한다. (논문의 Figure 5 참조)
실험 결과
- 주요 데이터셋: Defects4J v2.0.0의 16개 Java 프로젝트에서 수집한 206개의 실제 BIC (기존 67개 + 수동 큐레이션 139개).
- RQ1-1 (탐색 공간 축소): 1, 2단계를 통해 전체 커밋 히스토리의 약 11% 수준으로 탐색 공간이 축소됨. 코드 이력 추적 도구(git log, CodeShovel, CodeTracker) 중
git log가 100%의 유효성(BIC 포함)과 가장 빠른 속도(평균 27.3초)를 보임. - RQ1-2 (랭킹 성능): FONTE는 랜덤 베이스라인(MRR 0.150) 대비 월등히 높은 성능을 보임.
- FONTE (SBFL, Ochiai 사용): MRR 0.481, Acc@1 32.0%, Acc@5 70.4% 달성.
- FONTE (IRFL, Blues 사용): MRR 0.453, Acc@1 30.6%, Acc@5 65.0% 달성.
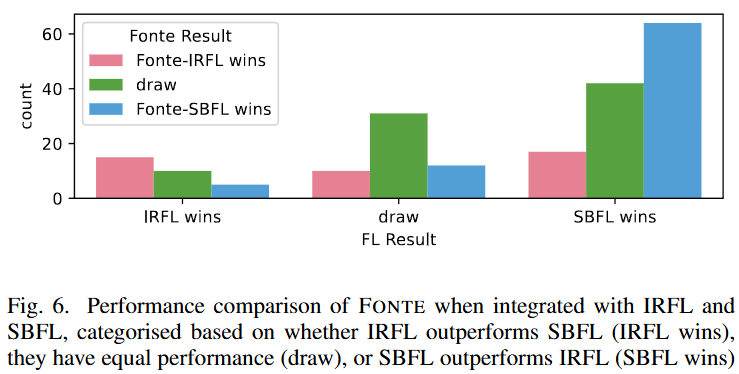
- SBFL의 FL 정확도가 IRFL보다 높아, FONTE의 최종 BIC 랭킹 성능도 더 높게 나타남 (논문의 Figure 6 참조).
- RQ1-3 (Ablation Study): '순위 기반 투표력'과 '깊이 기반 감쇠' 두 기능 모두 성능에 중요하게 기여함. 둘 다 제거 시 MRR이 최대 16.6% 하락.
- RQ2 (비교 결과): FONTE는 Max Aggregation, Bug2Commit, FBL-BERT 등 기존 SOTA IR 기반 기법들보다 모든 지표에서 뛰어난 성능을 보임. FONTE (SBFL)은 최고 성능의 베이스라인(Bug2Commit) 대비 45.8% 더 높은 MRR을 기록.
- RQ3 (가중 이진 탐색): FONTE 점수를 사용한 가중 이진 탐색은 전체 커밋 이력 대상 표준 이진 탐색 대비 98%의 사례(202/206)에서 탐색 반복 횟수를 줄였고, 평균 6.26회 절감함. 축소된 대상 비교 시에도 64.6% 사례에서 반복 횟수를 줄임. (논문의 Figure 7, 8 참조)
- 산업 적용 (SAP HANA): 10M+ 라인의 C/C++ 코드베이스인 SAP HANA의 배치 테스팅 실패 23건에 적용. 평균 18.48개의 커밋 배치에서 FONTE는 87%의 BIC를 Top 5 내, 100%를 Top 10 내에 랭크시킴 (MRR 0.600). 가중 이진 탐색 적용 시 필요한 반복 횟수의 32%를 절감할 것으로 예상됨.
결론
본 논문은 테스트 실패 시점(버그 리포트 불필요)에 사용 가능한 BIC 식별 기법 FONTE를 제안했다. FONTE는 실패 커버리지와 구문 분석(AST)을 통해 BIC 탐색 공간을 효과적으로 축소하고, 코드 레벨 FL 점수와 변경 이력을 결합하여 남은 커밋의 순위를 매긴다. Defects4J 버그 평가 결과, FONTE는 기존 기법들을 크게 능가하는 0.481의 MRR을 달성했다. 또한, FONTE 점수를 활용한 가중 이진 탐색은 표준 이진 탐색 대비 탐색 비용을 98%의 사례에서 절감했다. SAP HANA 사례 연구를 통해 대규모 산업 소프트웨어의 배치 테스팅 CI 시나리오에서도 BIC 식별 비용을 성공적으로 줄일 수 있음을 보였다.