Mastering the game of Go with deep neural networks and tree search
논문 정보
- 제목: Mastering the game of Go with deep neural networks and tree search
- 저자: David Silver 외 (Google DeepMind)
- 학회/저널: Nature
- 발행일: 2016-01-28
- DOI: 10.1038/nature16961
- 주요 연구 내용: 바둑판의 국면을 평가하는 가치망(value network)과 다음 수를 선택하는 정책망(policy network)이라는 두 개의 심층 신경망을 몬테카를로 트리 탐색(MCTS)과 결합한 새로운 접근법을 제안함. 신경망은 인간 전문가의 기보를 이용한 지도 학습과 알파고 자체 대국을 통한 강화 학습의 조합으로 훈련됨.
- 주요 결과 및 결론: 개발된 프로그램 알파고(AlphaGo)는 다른 주요 바둑 프로그램들을 상대로 99.8%의 압도적인 승률을 기록했으며, 당시 유럽 챔피언이었던 판후이 프로 2단을 5대 0으로 이김. 이는 컴퓨터 프로그램이 정식 크기의 바둑판에서 인간 프로 기사를 상대로 거둔 최초의 승리임.
- 기여점: 인간 전문가의 기보를 활용한 지도 학습과 자체 대국 기반의 강화 학습을 결합한 혁신적인 신경망 훈련 파이프라인을 구축함. 심층 신경망을 통해 바둑의 복잡한 국면 평가와 수 선택 문제를 해결하고, 이를 효율적으로 몬테카를로 트리 탐색과 통합하여 인간 최고 수준의 기력을 달성함.
요약
초록
바둑은 거대한 탐색 공간과 국면 평가의 어려움 때문에 오랫동안 인공지능에게 가장 도전적인 고전 게임으로 여겨져 왔다. 이 논문에서는 바둑판의 국면을 평가하기 위한 가치망과 수를 선택하기 위한 정책망을 사용하는 새로운 컴퓨터 바둑 접근법을 소개한다. 이 심층 신경망들은 인간 전문가의 기보를 통한 지도 학습과 자체 대국을 통한 강화 학습의 새로운 조합으로 훈련되었다. 탐색 없이도 이 신경망은 수천 번의 무작위 시뮬레이션을 수행하는 최첨단 몬테카를로 트리 탐색 프로그램 수준의 기력을 보여준다. 또한, 몬테카를로 시뮬레이션과 가치망, 정책망을 결합한 새로운 탐색 알고리즘을 도입했다. 이 탐색 알고리즘을 사용한 알파고 프로그램은 다른 바둑 프로그램을 상대로 99.8%의 승률을 달성했으며, 유럽 바둑 챔피언을 5대 0으로 꺾었다. 이는 컴퓨터 프로그램이 정식 바둑 경기에서 인간 프로 기사를 이긴 최초의 사례로, 이전에는 적어도 10년은 더 걸릴 것으로 예상되었던 업적이다.
서론
바둑과 같은 게임은 경우의 수가 너무 많아() 모든 경우를 탐색하는 것은 불가능하다. 기존 AI는 탐색의 깊이(depth)를 줄이기 위해 국면 평가를, 탐색의 너비(breadth)를 줄이기 위해 유망한 수들을 샘플링하는 정책을 사용해왔다. 몬테카를로 트리 탐색(MCTS)은 이런 원칙을 적용해 강한 아마추어 수준에 도달했지만, 얕은 정책이나 선형적인 가치 함수에 의존하는 한계가 있었다. 본 연구에서는 심층 합성곱 신경망(Deep Convolutional Neural Networks)을 사용하여 바둑판을 하나의 이미지처럼 처리하고, 이를 통해 국면 평가(가치망)와 수 선택(정책망)의 정확도를 획기적으로 높여 탐색의 효율성을 극대화하고자 했다.
배경
알파고 이전의 가장 강력한 바둑 프로그램들은 MCTS에 기반했다. MCTS는 시뮬레이션(롤아웃)을 통해 탐색 트리의 각 노드(상황)의 가치를 추정한다. 시뮬레이션을 많이 할수록 더 정확한 값을 얻을 수 있다. 기존 프로그램들은 인간 전문가의 수를 예측하도록 훈련된 정책을 사용하여 탐색의 범위를 유망한 수들로 좁히고 롤아웃의 질을 높이는 방식을 사용했지만, 전문 프로 기사 수준에는 도달하지 못했다. 이는 복잡한 바둑의 국면을 정확히 평가하는 데 한계가 있었기 때문이다.
모델 아키텍처 / 방법론
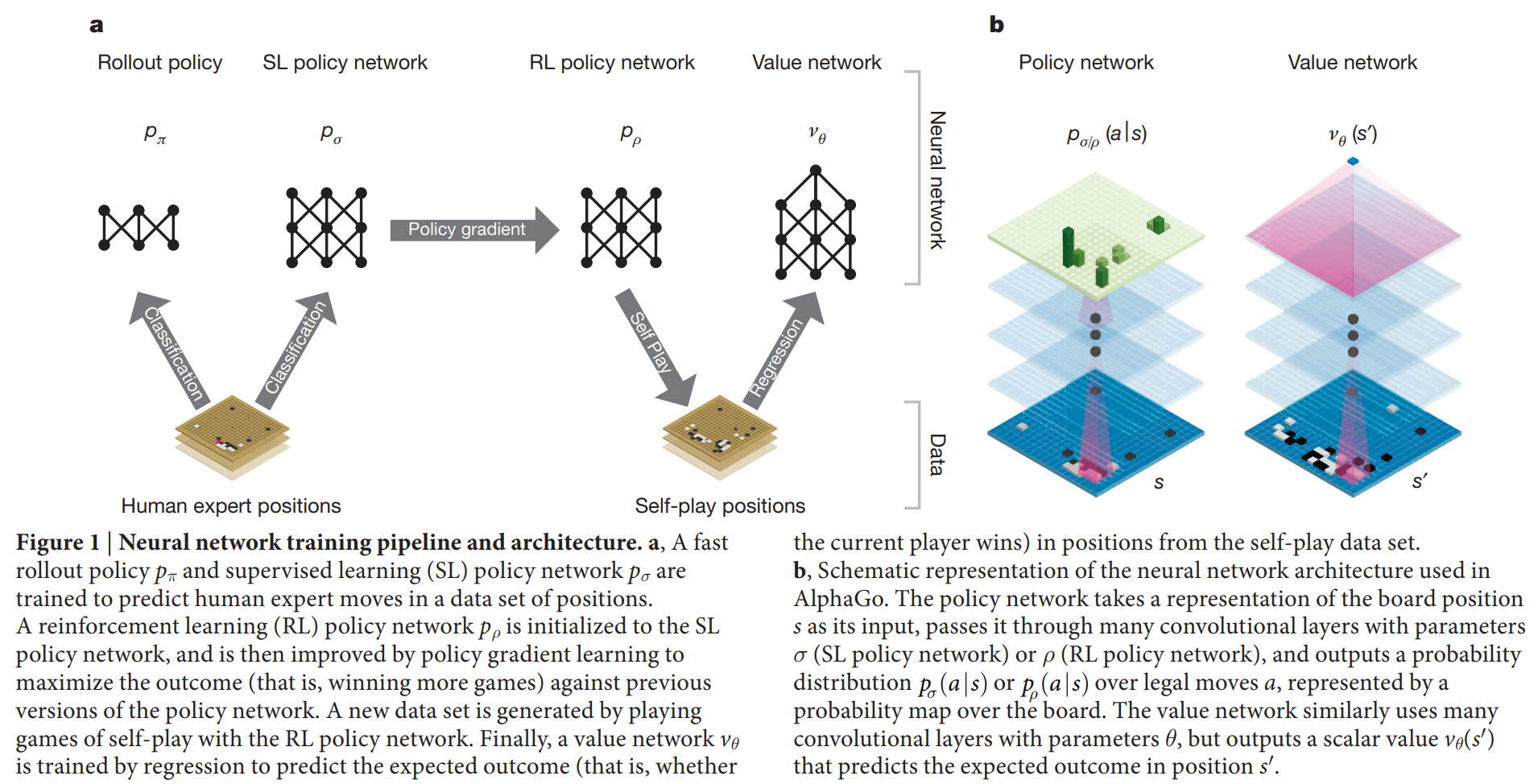 알파고의 핵심은 심층 신경망과 MCTS의 결합이며, 훈련 파이프라인은 논문의 Figure 1에 잘 나타나 있다.
알파고의 핵심은 심층 신경망과 MCTS의 결합이며, 훈련 파이프라인은 논문의 Figure 1에 잘 나타나 있다.
-
핵심 구조/방법: 알파고의 훈련 및 실행은 4단계의 파이프라인으로 구성된다.
- 지도 학습(SL) 정책망(): 인간 전문가들의 기보 데이터(KGS 6~9단) 3,000만 개를 학습하여 다음 수를 예측하도록 훈련된다. 이 신경망은 57.0%의 정확도로 전문가의 수를 예측했다.
- 강화 학습(RL) 정책망(): SL 정책망을 초기 가중치로 사용하여, 정책망의 이전 버전들과 자체 대국을 진행하며 승리라는 목표를 달성하도록 정책 경사(policy gradient) 방법으로 미세 조정된다. 이 과정을 통해 예측 정확도보다는 실제 승률을 높이는 방향으로 최적화된다.
- 가치망(): 강화 학습으로 고도화된 RL 정책망이 스스로와 대국한 기보를 데이터로, 특정 국면에서 최종 승리 확률을 예측하도록 훈련된다. 이는 MCTS에서 국면 평가의 정확도를 높이는 핵심 요소이다.
- MCTS 통합: 훈련된 정책망과 가치망을 MCTS 알고리즘에 통합한다. 정책망은 탐색할 후보 수를 줄여주고(너비 축소), 가치망은 긴 시뮬레이션(롤아웃) 없이도 국면의 가치를 빠르고 정확하게 평가해준다(깊이 축소).
-
주요 구성 요소:
- 정책망 (Policy Network): 13개 층의 CNN 구조로, 크기의 바둑판 상태를 입력받아 각 착수 지점에 대한 확률 분포를 출력한다.
- 가치망 (Value Network): 정책망과 유사한 CNN 구조이지만, 최종적으로 현재 국면의 승리 확률을 나타내는 하나의 스칼라 값(-1~1)을 출력한다.
- 빠른 롤아웃 정책 (): MCTS 시뮬레이션 단계에서 매우 빠른 속도로 게임을 끝까지 진행시키기 위해 사용되는 가볍고 간단한 선형 정책이다.
-
수식: MCTS 탐색 과정에서 각 수는 다음 식을 최대화하는 방향으로 선택된다.
여기서 는 행동 가치(평균 승률)이고, 는 탐색을 장려하는 보너스 항으로 이다. 는 정책망이 예측한 사전 확률, 은 방문 횟수다.
탐색 트리의 끝(leaf node)에 도달했을 때의 국면 평가는 가치망의 예측()과 빠른 롤아웃의 결과()를 혼합하여 사용한다.
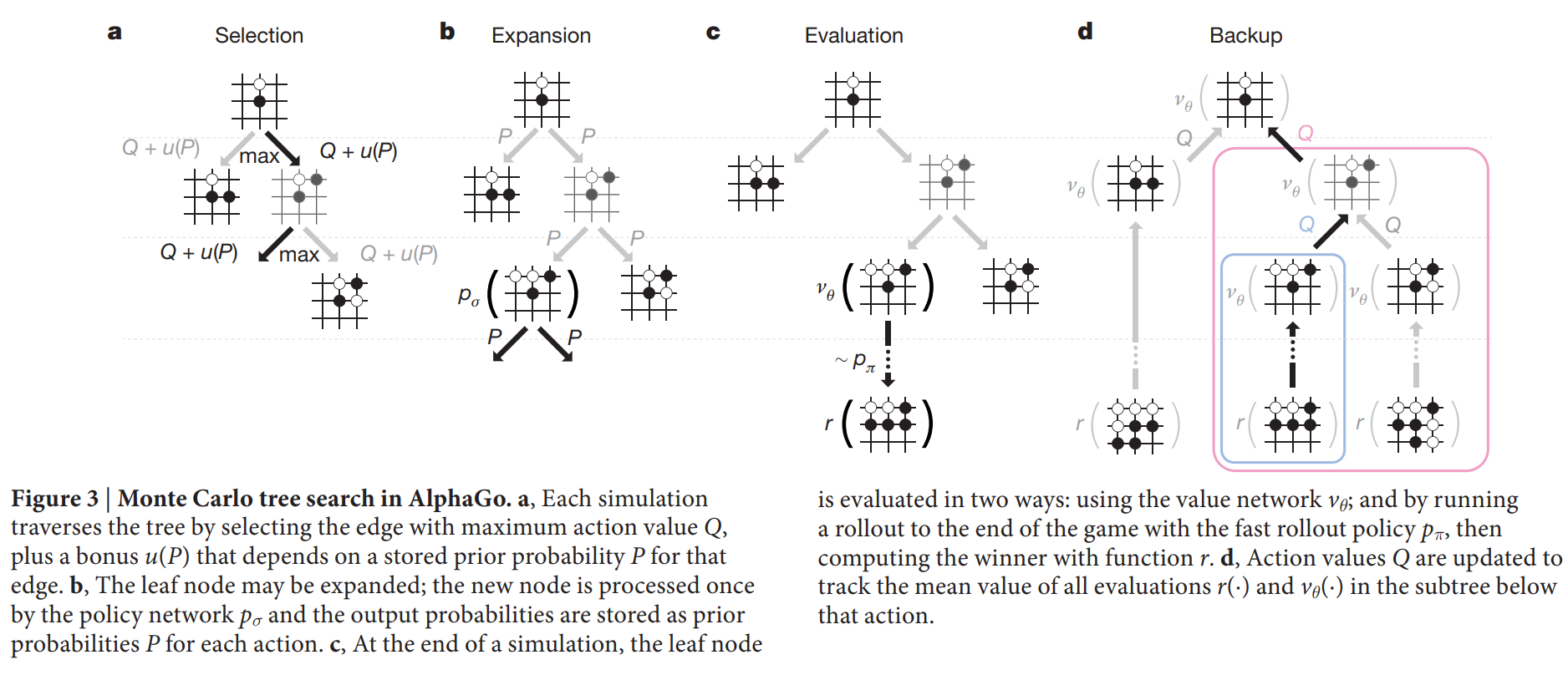
- 알고리즘: 알파고의 MCTS는 논문의 Figure 3에 묘사된 4가지 단계(선택, 확장, 평가, 역전파)를 반복한다.
- 선택(Selection): 현재 트리 내에서 위의 수식을 따라 가장 유망한 노드를 선택하며 내려간다.
- 확장(Expansion): 일정 횟수 이상 방문한 노드에 도달하면, 정책망을 이용해 다음 유망 수를 계산하고 트리를 확장한다.
- 평가(Evaluation): 새로 확장된 노드는 가치망을 통해 한 번 평가되고, 동시에 빠른 롤아웃 정책을 통해 게임 끝까지 시뮬레이션하여 승패 결과를 얻는다.
- 역전파(Backup): 평가 결과를 트리를 따라 루트 노드까지 전파하며 각 노드의 통계(방문 횟수, 승률)를 갱신한다.
실험 결과
- 주요 데이터셋: KGS Go 서버의 6~9단 유저 기보 3,000만 개를 지도 학습에 사용했고, RL 정책망과 가치망 훈련을 위해 3,000만 개의 자체 대국 데이터를 생성했다.
- 핵심 성능 지표:
- 단일 머신 알파고는 다른 최상위 바둑 프로그램(Crazy Stone, Zen 등)과의 대결에서 495전 494승 (99.8%)을 기록했다.
- 분산 버전 알파고는 단일 머신 알파고를 상대로 77%의 승률을 보였다.
- 2015년 10월, 유럽 챔피언 판후이 프로 2단과의 공식 5번기에서 5대 0으로 완승했다.
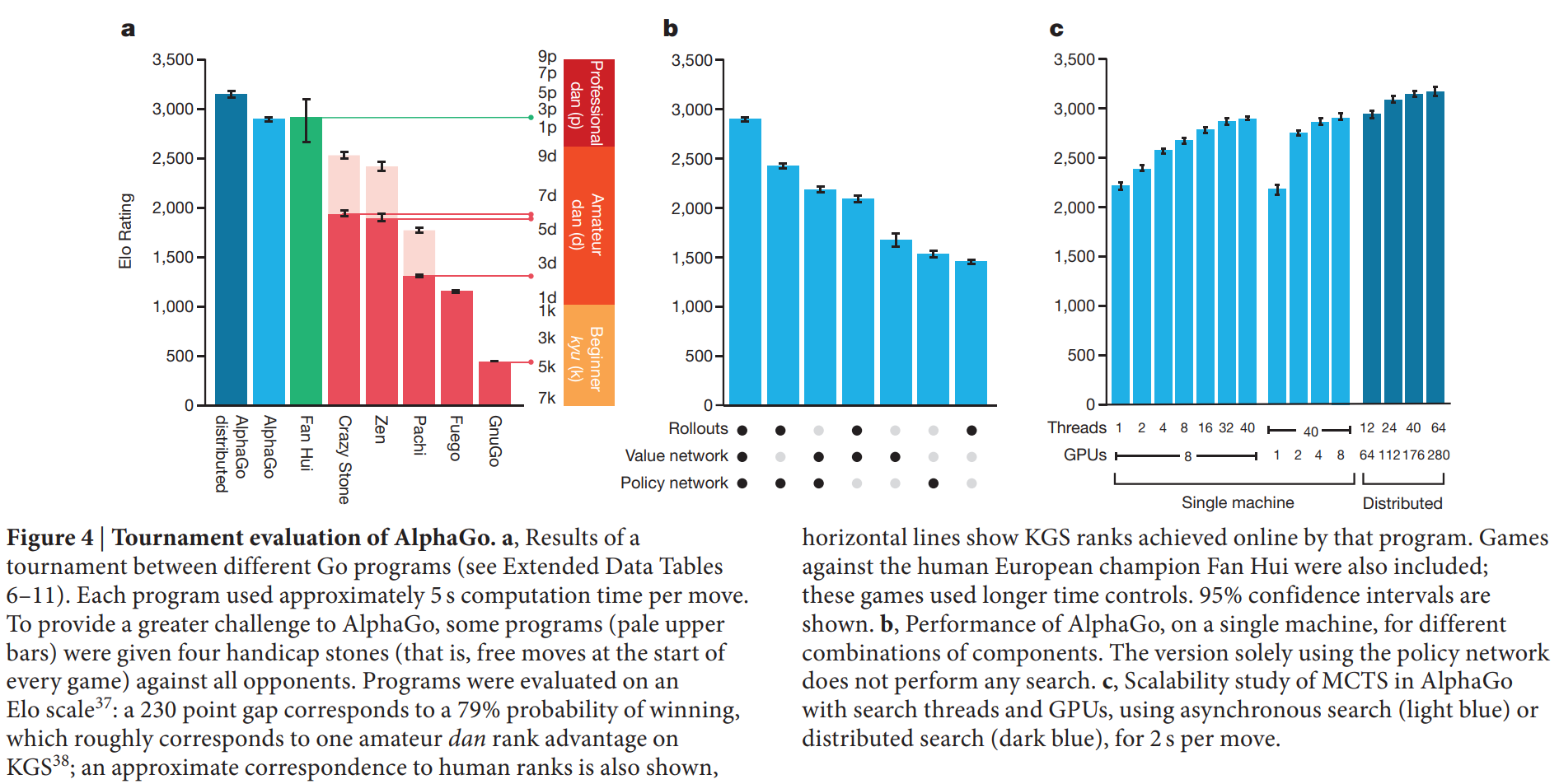
- 비교 결과: 논문의 Figure 4a는 알파고와 다른 프로그램들의 Elo 레이팅을 비교하며 알파고의 압도적인 성능을 보여준다. 기존의 어떤 프로그램보다 수 단계 높은 기력을 달성했다. 또한, Figure 2b는 가치망이 롤아웃 시뮬레이션보다 게임 결과를 훨씬 더 정확하게 예측함을 보여주며, 이는 15,000배나 적은 계산량으로 이룬 결과이다. 가치망과 롤아웃을 함께 사용했을 때(혼합 평가) 가장 좋은 성능을 보였다.
결론
본 연구는 심층 신경망과 트리 탐색을 결합하여 인공지능의 오랜 난제였던 바둑에서 프로 기사를 능가하는 수준을 달성했다. 알파고는 체스 챔피언을 이긴 딥블루보다 훨씬 적은 수의 국면을 탐색했지만, 정책망을 통해 더 지능적으로 유망한 수를 선택하고 가치망으로 더 정확하게 국면을 평가함으로써 이를 보완했다. 이는 인간의 직관과 유사한 접근 방식이다. 알파고의 성공은 지도 학습과 강화 학습을 결합한 이 접근법이 바둑을 넘어 다른 해결하기 어려운 인공지능 문제에도 적용될 수 있다는 가능성을 제시한다.