Deep learning-based fabric defect detection: A review
논문 정보
- 제목: Deep learning-based fabric defect detection: A review
- 저자: Yavuz Kahraman (Adiyaman University), Alptekin Durmuşoğlu (Gaziantep University)
- 학회/저널: Textile Research Journal
- 발행일: 2022-10-17
- DOI: 10.1177/00405175221130773
- 주요 연구 내용: 2003년부터 현재까지 발표된 딥러닝 기반 직물 결함 검출 관련 논문 38개를 체계적으로 검토하고 분류함. 연구들은 주로 합성곱 신경망(CNN), 생성적 적대 신경망(GAN), 오토인코더(Autoencoder), 순환 신경망(LSTM)과 같은 주요 딥러닝 아키텍처를 기반으로 분석되었음.
- 주요 결과 및 결론: 딥러닝, 특히 CNN 기반 방법론이 직물 결함 검출에서 95% 이상의 높은 성공률을 보이며 매우 효과적임을 확인함. 가장 많이 활용된 공개 데이터셋은 TILDA였으나, 연구의 일반화와 재현성을 위해 표준화된 대규모 데이터베이스 구축의 필요성을 제기함.
- 기여점: 본 논문은 딥러닝 기반 직물 결함 검출 분야를 전문적으로 다룬 최초의 최신 리뷰 연구임. 주요 딥러닝 아키텍처의 장단점을 비교 분석하고, 사용된 데이터셋과 성능을 종합적으로 정리하여 해당 분야 연구자들에게 유용한 참고 자료와 향후 연구 방향을 제시함.
요약
초록
지난 20년간 섬유 산업에서 결함 검출을 위해 딥러닝을 활용하는 추세가 증가해왔다. 대부분의 연구는 특정 문제에 집중했으며, 기존 리뷰 논문들은 더 일반적인 관점에서 접근하는 경향이 있었다. 이 연구는 2003년부터 현재까지 딥러닝을 이용한 직물 결함 검출 구현을 조사한 최초의 최신 연구이다. 본 논문은 딥러닝 기반 직물 결함 검출 논문들을 검토하여 사용된 방법, 데이터베이스, 성능, 비교 결과, 아키텍처 유형을 서로 비교한다. 가장 널리 사용된 딥러닝 아키텍처는 맞춤형 CNN, LSTM, GAN, 오토인코더였으며, 이들 접근법의 장단점도 함께 기술했다.
서론
직물 결함은 기계 공정, 원사 불량 등 다양한 원인으로 발생하며, 최종 제품의 품질을 저하시킨다. 전통적인 육안 검사는 시간과 비용이 많이 들고 미세한 결함을 놓치기 쉽다. 따라서 수십 가지 유형의 결함을 식별할 수 있는 자동화된 시스템이 중요해졌다. 하지만 결함 유형의 다양성, 변형, 적은 데이터 샘플 등의 문제로 인해 포괄적인 자동 결함 검출 시스템을 구축하는 데는 어려움이 따른다. 이 연구는 이러한 문제를 해결하기 위한 딥러닝 기반 접근법들을 종합적으로 검토하고 분석하는 것을 목표로 한다.
배경
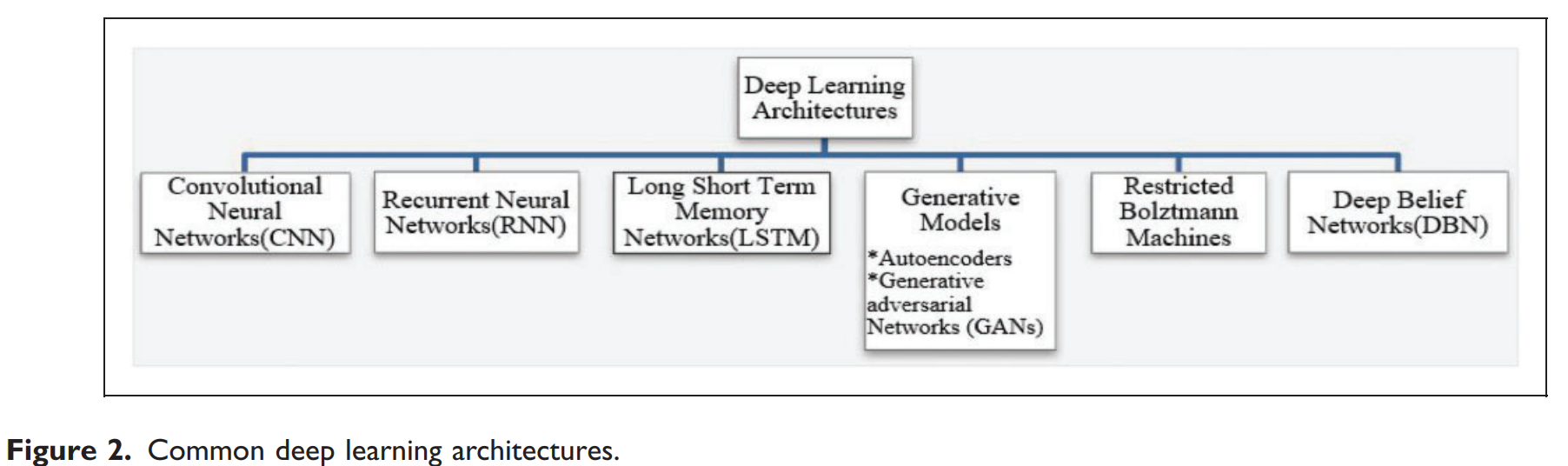 딥러닝은 다중 처리 계층으로 구성된 계산 모델을 사용하여 여러 추상화 수준에서 데이터의 표현을 학습하는 인공지능의 한 분야이다. 기존 머신러닝 기술과 달리, 딥러닝은 원시 데이터로부터 직접 특징을 학습하는 능력이 뛰어나 이미지 인식과 같은 분야에서 뛰어난 성능을 보인다. 본 논문에서 주로 검토하는 딥러닝 아키텍처는 다음과 같으며, 이는 논문의 Figure 2에 잘 나타나 있다.
딥러닝은 다중 처리 계층으로 구성된 계산 모델을 사용하여 여러 추상화 수준에서 데이터의 표현을 학습하는 인공지능의 한 분야이다. 기존 머신러닝 기술과 달리, 딥러닝은 원시 데이터로부터 직접 특징을 학습하는 능력이 뛰어나 이미지 인식과 같은 분야에서 뛰어난 성능을 보인다. 본 논문에서 주로 검토하는 딥러닝 아키텍처는 다음과 같으며, 이는 논문의 Figure 2에 잘 나타나 있다.
- 합성곱 신경망 (CNNs): 이미지 인식에 특화된 구조로, 합성곱과 풀링 계층을 통해 특징을 추출한다.
- 순환 신경망 (RNNs) 및 Long Short-Term Memory (LSTM): 순차적 데이터 처리에 강점을 보이며, 이전 정보를 기억하여 현재 입력 처리에 활용한다.
- 생성 모델 (Generative Models): 비지도 학습을 통해 데이터 분포를 학습하며, 오토인코더와 생성적 적대 신경망(GAN)으로 나뉜다.
- 제한된 볼츠만 머신 (RBMs) 및 심층 신뢰 신경망 (DBNs): 확률적 생성 모델로, 특징 학습 및 추출에 사용된다.
모델 아키텍처 / 방법론
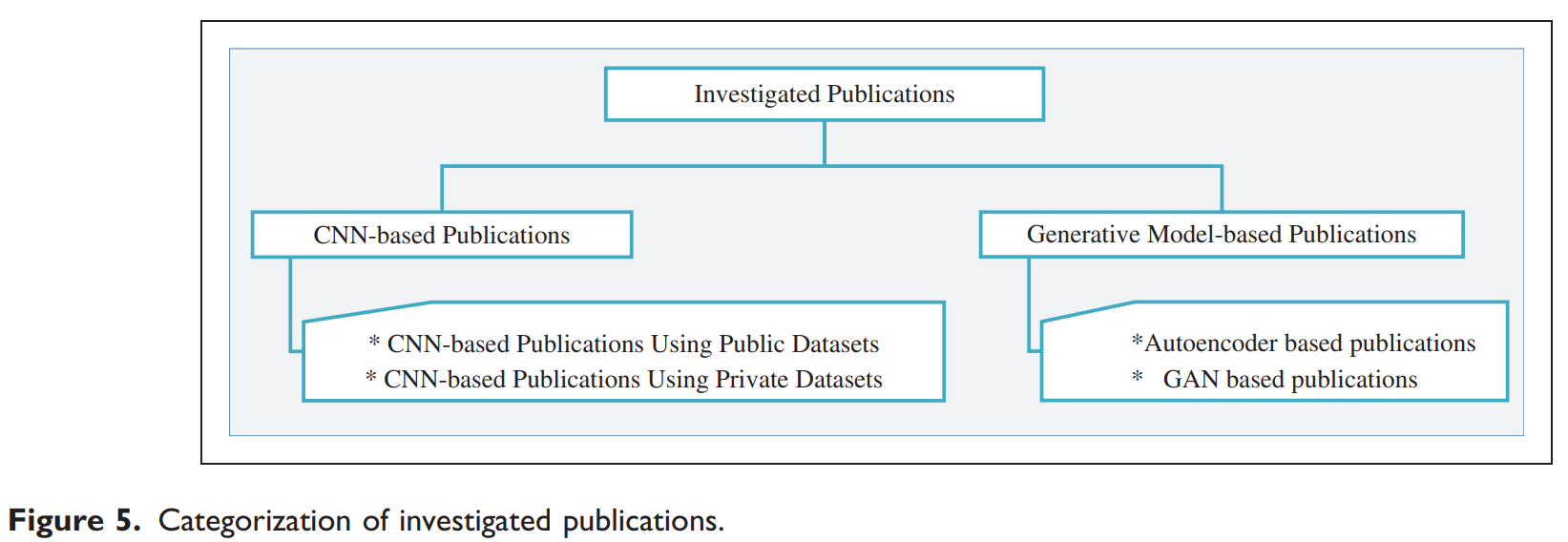 본 논문은 리뷰 연구이므로, 방법론은 기존 연구들을 체계적으로 분류하고 분석하는 것이다. 논문의 Figure 5에서 제시된 바와 같이, 검토된 논문들은 다음과 같이 두 가지 주요 그룹으로 나뉜다.
본 논문은 리뷰 연구이므로, 방법론은 기존 연구들을 체계적으로 분류하고 분석하는 것이다. 논문의 Figure 5에서 제시된 바와 같이, 검토된 논문들은 다음과 같이 두 가지 주요 그룹으로 나뉜다.
- CNN 기반 연구: 가장 많은 수(28개)의 연구가 여기에 속하며, 사용된 데이터셋의 종류에 따라 다시 두 가지로 분류된다.
- 공개 데이터셋 사용 연구: TILDA, DAGM 2007 등 공개된 데이터셋을 활용하여 모델의 성능을 평가하고 다른 연구와 비교한다.
- 자체 제작 데이터셋 사용 연구: 특정 생산 환경에 맞춰 자체적으로 수집하고 레이블링한 데이터셋을 사용한다.
- 생성 모델 기반 연구: 비지도 학습의 이점을 활용하는 연구들로, 다음과 같이 나뉜다.
- 오토인코더 기반 연구: 정상 샘플만으로 학습하여 입력 이미지를 재구성하고, 원본과의 차이를 통해 결함을 탐지한다. 차원 축소 및 특징 학습에 효과적이다.
- GAN 기반 연구: 정상 이미지 분포를 학습한 생성자가 실제와 유사한 이미지를 만들고, 판별자가 이를 구별하는 과정에서 결함을 탐지한다. 레이블이 없는 데이터 학습에 유용하다.
논문은 각 아키텍처의 장단점을 Table 2에 정리하여 비교하였다. 예를 들어, CNN은 높은 정확도와 실시간 처리 능력을 갖지만, 대량의 데이터와 높은 컴퓨팅 자원을 필요로 한다. 반면 GAN은 레이블 없는 데이터로 학습 가능하지만, 학습 과정이 불안정하고 어렵다는 단점이 있다.
실험 결과
- 주요 데이터셋: 연구들에서 사용된 공개 데이터셋 정보는 논문의 Table 3에 요약되어 있다. 가장 빈번하게 사용된 데이터셋은 TILDA였으며, 이 외에도 Kylberg texture, DAGM 2007, DHU FD 등이 활용되었다. 많은 연구(약 절반)가 특정 공정에 맞춰 자체 제작한 비공개 데이터셋을 사용하기도 했다.
- 핵심 성능 지표: 검토된 대부분의 딥러닝 기반 연구들은 95% 이상의 높은 결함 검출 정확도를 달성했다. 이는 딥러닝이 직물 결함 검출에 매우 효과적인 접근법임을 입증한다. 특히 CNN 기반의 다양한 모델(LeNet, AlexNet, VGG, ResNet 등)들이 꾸준히 높은 성능을 보였다.
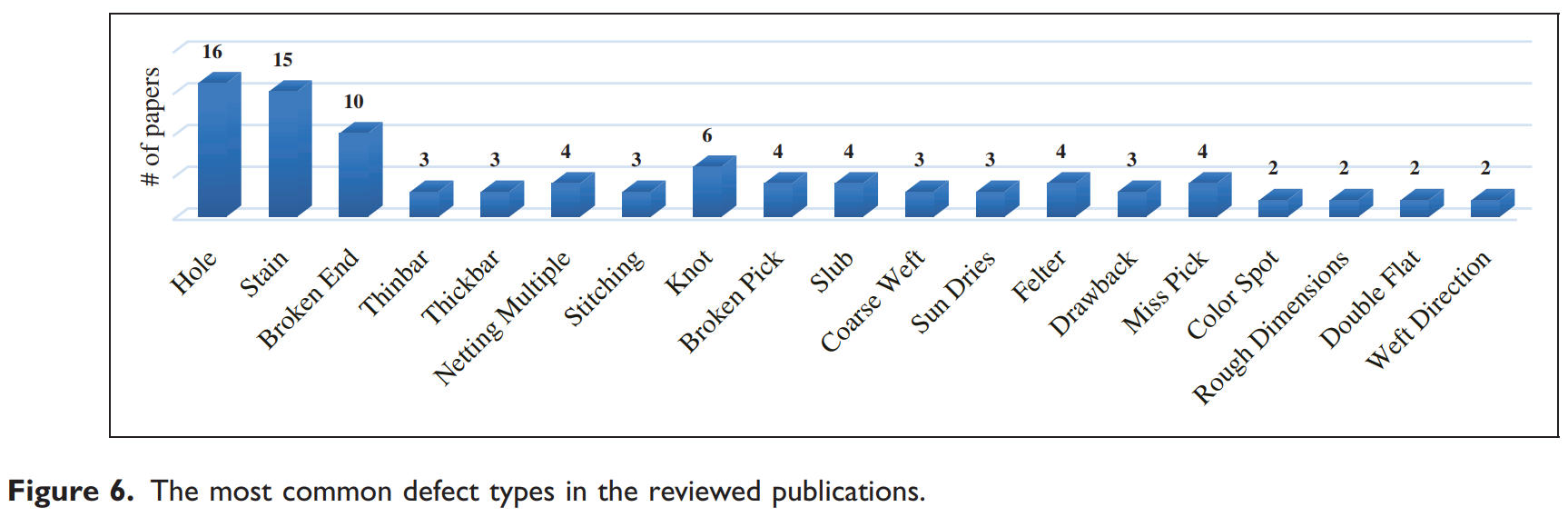
- 비교 결과: 연구들을 종합한 결과, CNN 기반 접근법이 가장 지배적으로 사용되었다(38개 중 28개). 오토인코더(6개)와 GAN(3개)은 주로 비지도 학습 환경에서 활용되었으며, LSTM은 1개의 연구에서만 사용되었다. 논문의 Tables 4, 5, 6은 각 연구에서 사용한 구체적인 방법, 분류 클래스 수, 성공률, 비교 대상 모델을 상세히 보여준다. 가장 흔하게 연구된 결함 유형은 구멍(hole), 얼룩(stain), 끊어진 실(broken end) 순이었다 (Figure 6 참조).
결론
본 연구는 딥러닝 기반 직물 결함 검출 분야의 연구들을 포괄적으로 검토하여, 딥러닝 기술이 이 분야에서 매우 성공적임을 확인했다.
- 연구 의의: 딥러닝, 특히 CNN은 기존 방법에 비해 월등한 성능을 보이며, 작은 결함 검출에도 강점을 보인다. 이 논문은 해당 분야의 연구 동향을 체계적으로 정리하고 주요 아키텍처의 장단점을 비교함으로써 향후 연구의 기초 자료를 제공한다.
- 향후 방향:
- 공통 데이터베이스 구축: 연구 결과의 객관적인 비교와 일반화를 위해 모든 결함 유형을 포함하는 표준화된 대규모 공개 데이터베이스가 필요하다.
- 하이브리드 방법 연구: 서로 다른 딥러닝 모델이나 전통적인 컴퓨터 비전 기법을 결합하여 성능을 높이는 하이브리드 접근법에 대한 연구가 유망하다.
- 계산 복잡도 감소: 실제 산업 현장에 적용하기 위해 모델의 경량화 및 계산 효율성을 높이는 연구가 필요하다.
- 비정형 직물 연구 확대: 패턴이 있는 직물뿐만 아니라 패턴이 없는 다양한 직물 구조에 대한 연구가 확대되어야 한다.