Analysing an imbalanced stroke prediction dataset using machine learning techniques
논문 정보
- 제목: Analysing an Imbalanced Stroke Prediction Dataset Using Machine Learning Techniques
- 저자: Viswapriya Subramaniyam Elangovan (SRM Institute of Science and Technology), Rajeswari Devarajan (SRM Institute of Science and Technology), Osamah I. Khalaf (Al-Nahrain University), Mhd Saeed Sharif (UEL University), Wael Elmedany (University of Bahrain)
- 학회/저널: KIJOMS
- 발행일: 2022-01-01
- DOI: DOI 링크 없음
- 주요 연구 내용: Kaggle의 공개 뇌졸중 예측 데이터셋은 소수 클래스(뇌졸중 환자)가 매우 적은 불균형 문제를 가짐. 이 문제를 해결하기 위해 SMOTE와 Adasyn 같은 오버샘플링 기법을 적용하여 데이터셋의 균형을 맞추고, 제안하는 하이브리드 신경망-랜덤 포레스트(NN-RF) 모델의 성능을 평가함.
- 주요 결과 및 결론: 제안된 NN-RF 모델은 Adasyn 오버샘플링 기법을 적용했을 때 가장 높은 성능을 보였음. F1-score 75%, 정확도 84%, AUC 86%를 달성하여 다른 벤치마킹 알고리즘(DT, LR, NN, RF)보다 우수한 예측 성능을 입증함.
- 기여점: 데이터 불균형 문제를 해결하기 위한 오버샘플링 기법의 효과를 검증함. 또한, 기존 단일 모델들의 한계를 극복하기 위해 신경망과 랜덤 포레스트를 결합한 하이브리드 모델을 제안하고 그 우수성을 실험적으로 증명함.
요약
초록
뇌졸중은 뇌 혈관의 파열로 인해 뇌 손상을 유발할 수 있는 심각한 질환이다. 이 연구의 주요 목표는 머신러닝(ML) 및 딥러닝(DL)을 사용하여 뇌졸중 발생 가능성을 조기에 예측하는 것이다. 뇌졸중의 여러 경고 징후를 시기적절하게 감지하면 심각도를 크게 줄일 수 있다. 이 논문은 뇌졸중 예측의 효율성을 높이기 위해 특징(feature)에 대한 포괄적인 분석을 수행했다. Kaggle의 뇌졸중 예측 데이터셋을 사용했으며, 이 데이터셋은 음성 샘플이 양성 샘플보다 훨씬 많은 클래스 불균형 문제를 가지고 있다. 오버샘플링 기법(SMOTE, Adasyn)을 사용하여 균형 잡힌 데이터셋을 생성했으며, Adasyn으로 균형을 맞춘 데이터셋에 하이브리드 NN-RF(신경망-랜덤 포레스트) 모델을 적용했을 때 75%의 가장 높은 F1-score와 84%의 정확도를 달성했다.
서론
뇌졸중은 전 세계적으로 주요 사망 원인 중 하나이며 심각한 공중 보건 문제이다. 적시에 뇌졸중을 예측하고 예방하는 것은 치명적인 결과를 줄이는 데 매우 중요하다. 최근 전자 건강 기록(EHR) 데이터와 머신러닝 모델을 활용한 예측 연구가 활발하지만, 대부분의 의료 데이터는 소수 클래스의 샘플 수가 현저히 적은 '불균형 데이터' 문제를 겪는다. 이는 모델이 다수 클래스에 편향되어 소수 클래스에 대한 예측 성능이 저하되는 원인이 된다. 이 연구는 데이터 레벨에서 불균형 문제를 해결하는 오버샘플링 기법에 초점을 맞추고, 이를 통해 뇌졸중 예측 모델의 성능을 향상시키고자 한다.
배경
데이터 불균형 문제를 해결하기 위한 접근법은 크게 알고리즘 레벨, 비용 민감 학습, 데이터 레벨로 나뉜다. 이 연구는 분류기에 독립적이고 적응성이 높은 데이터 레벨 기법에 집중했다.
- 언더샘플링(Under-sampling): 다수 클래스의 샘플을 제거하는 방식. 정보 손실의 위험이 있다.
- 오버샘플링(Over-sampling): 소수 클래스의 샘플을 복제하거나 생성하는 방식. 과적합(overfitting) 문제가 발생할 수 있다.
- SMOTE (Synthetic Minority Over-sampling Technique): 소수 클래스 샘플과 그 이웃 샘플 사이에 새로운 합성 샘플을 생성하여 과적합 문제를 완화한다. 하지만 노이즈 샘플을 생성할 수 있다는 단점이 있다.
- Adasyn (Adaptive Synthetic Sampling): SMOTE를 개선한 기법으로, 분류하기 어려운 소수 클래스 샘플 주변에 더 많은 합성 샘플을 집중적으로 생성하여 데이터 분포를 적응적으로 학습한다.
모델 아키텍처 / 방법론
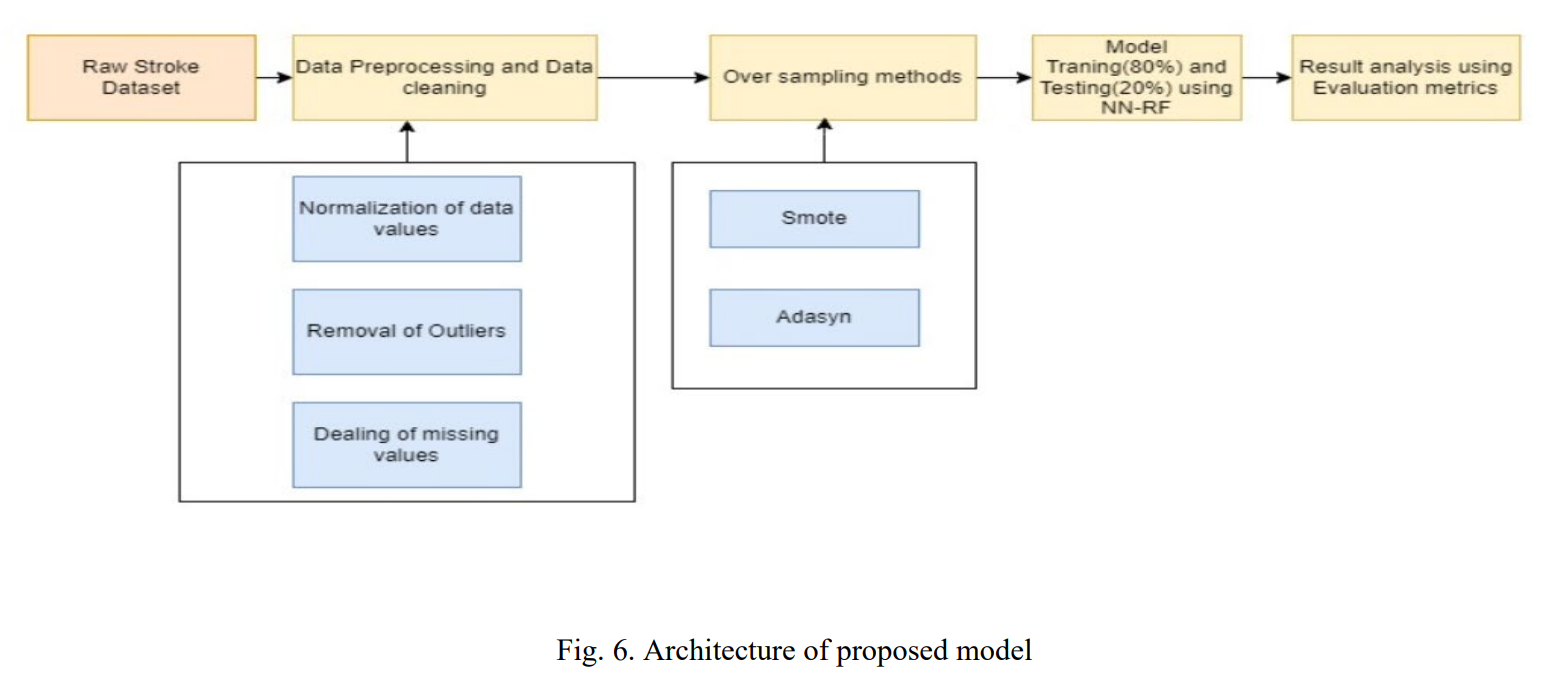 논문의 전체적인 방법론은 Figure 6에 제시된 아키텍처를 따른다.
논문의 전체적인 방법론은 Figure 6에 제시된 아키텍처를 따른다.
- 핵심 구조/방법: 원본 뇌졸중 데이터셋을 전처리하고, SMOTE와 Adasyn 오버샘플링을 적용하여 훈련 데이터를 재구성한 후, 제안하는 하이브리드 NN-RF 모델과 다른 분류 모델들을 학습시키고 성능을 비교한다.
- 데이터 전처리: BMI 피처의 결측치는 평균값으로, 'smoking_status' 피처의 결측치는 'No Info'로 채웠다. 이후 모든 문자열 데이터를 정수형으로 인코딩하여 수치형 데이터셋으로 변환했다.
- NN-RF (Neural Network-Random Forest): 이 모델은 인공 신경망(ANN)의 마지막 SoftMax 계층을 결정 트리 앙상블인 랜덤 포레스트(RF)로 대체한 하이브리드 구조이다. 신경망이 데이터로부터 고수준의 특징을 학습하고, 랜덤 포레스트가 이를 입력받아 최종 분류를 수행함으로써 두 모델의 장점을 결합했다.
- 수식: 성능 평가는 다음 지표들을 사용했다.
- 정확도(Accuracy):
- 정밀도(Precision):
- 재현율(Recall):
- F1-Score:
실험 결과
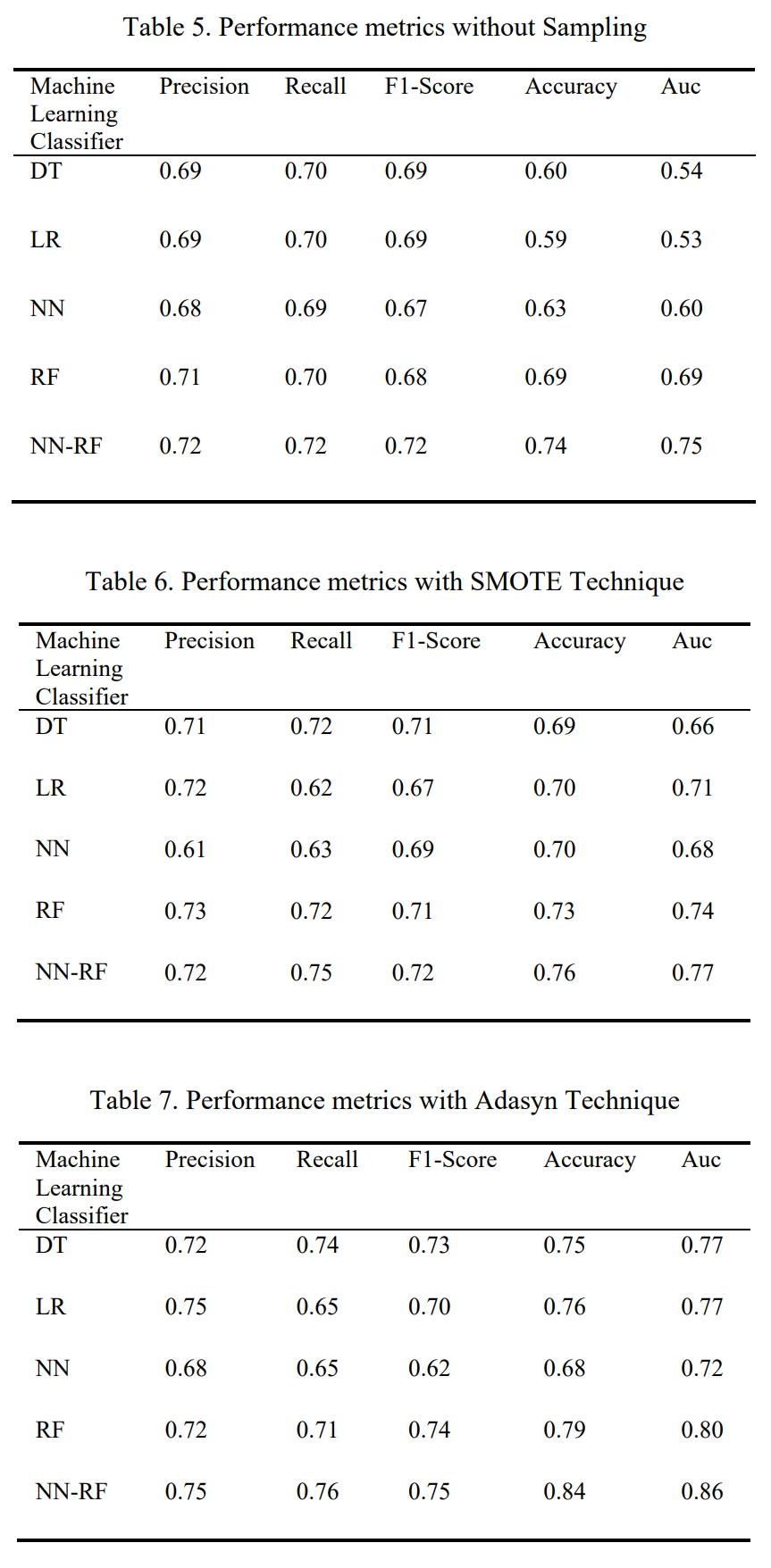
- 주요 데이터셋: Kaggle의 뇌졸중 예측 데이터셋을 사용했다. 총 43,400개의 샘플로 구성되어 있으며, 이 중 뇌졸중 환자(양성)는 783명(1.8%), 비환자(음성)는 42,617명(98.1%)으로 매우 불균형하다.
- 핵심 성능 지표: 불균형 데이터셋 평가에 중요한 F1-score를 핵심 지표로 사용했다. 정확도, 정밀도, 재현율, AUC도 함께 평가했다.
- 비교 결과:
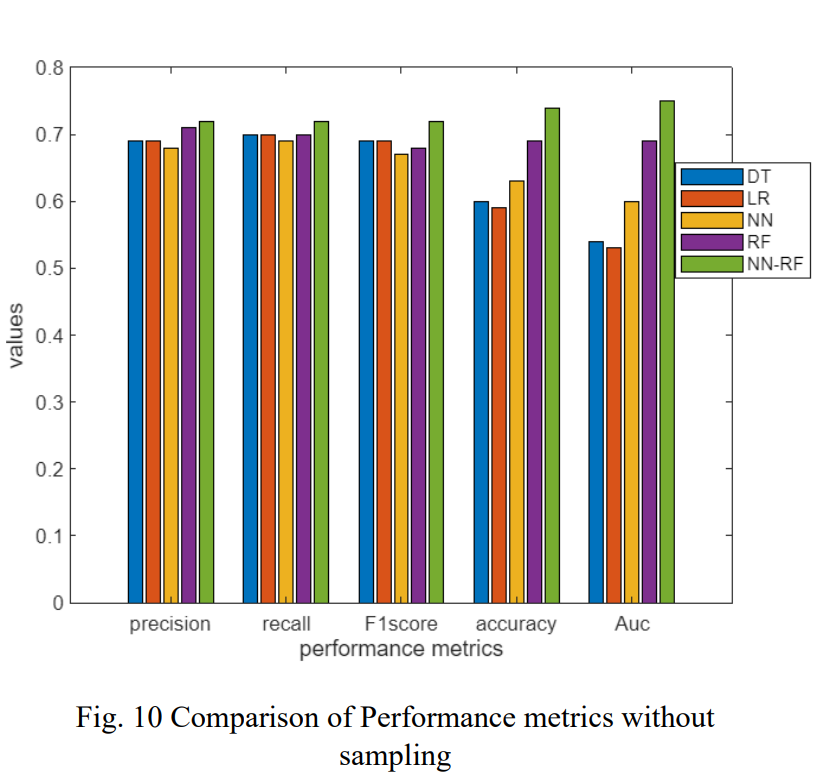
- 샘플링 미적용: 제안 모델(NN-RF)이 F1-score 0.72, 정확도 0.74로 가장 좋은 성능을 보였다.
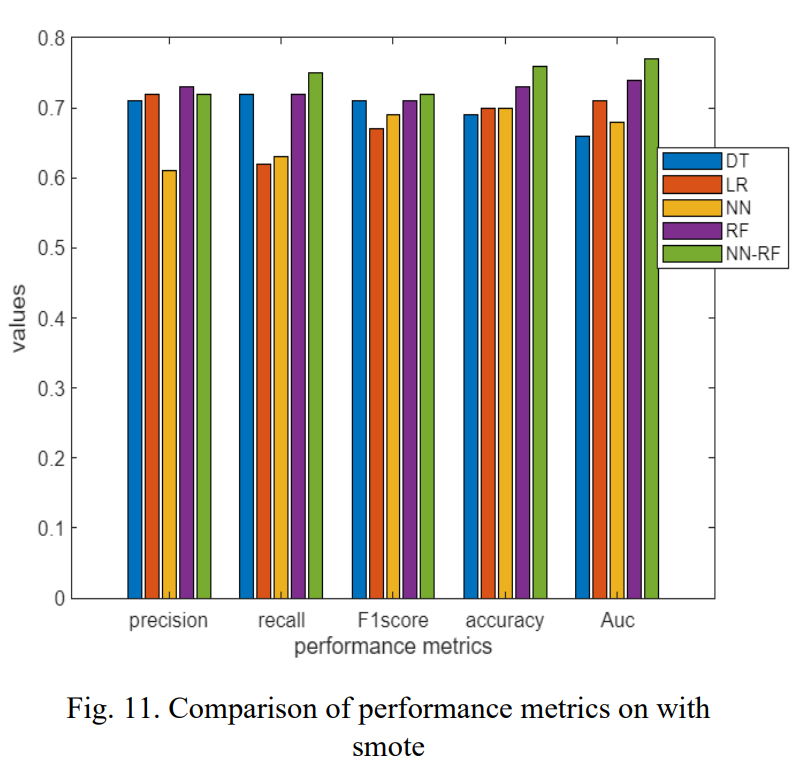
- SMOTE 적용: NN-RF 모델이 F1-score 0.72, 정확도 0.76을 기록했다.
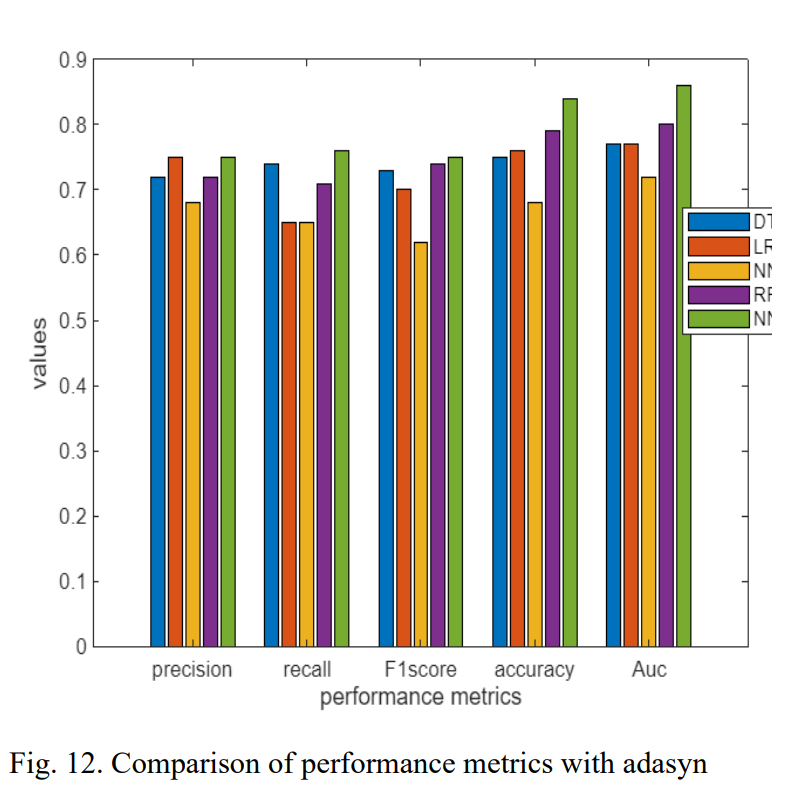
- Adasyn 적용: NN-RF 모델이 F1-score 0.75, 정확도 0.84, AUC 0.86으로 모든 시나리오 중 가장 뛰어난 성능을 달성했다.
- 실험 결과는 논문의 Table 5, 6, 7 및 Figure 10, 11, 12에서 상세히 비교되어 있으며, Adasyn 기법이 SMOTE보다 성능 향상에 더 효과적이었음을 보여준다.
결론
이 연구는 불균형 데이터셋에서 뇌졸중을 효과적으로 예측하기 위해 오버샘플링 기법과 하이브리드 NN-RF 모델을 제안했다. 실험 결과, Adasyn 오버샘플링 기법으로 데이터 불균형을 해결하고 NN-RF 모델로 분류했을 때, F1-score 75%, 정확도 84%라는 우수한 성능을 달성했다. 이는 데이터 기반의 접근법이 뇌졸중 예측의 정확성과 효율성을 크게 향상시킬 수 있음을 시사한다. 향후 연구로는 공개적으로 사용 가능한 LOD(Linked Open Data) 클라우드와 데이터셋을 연결하여 예측 성능을 더욱 개선하는 방향을 제안했다.