Optimization of spinning processes in textile manufacturing using reinforcement learning
논문 정보
- 제목: Optimization of spinning processes in textile manufacturing using reinforcement learning
- 저자: SMM Sajadieh, Hye Kyung Choi, Whan Lee, Sang Do Noh (Sungkyunkwan University), Seung bum Sim (Korea Textile Development Institute)
- 학회/저널: IISE Annual Conference & Expo 2024
- 발행일: 2024-05-18
- DOI: 10.21872/2024IISE_6980
- 주요 연구 내용: 기존 회귀 모델을 기반으로 보상 계산을 수행하는 Q-러닝 알고리즘을 제안하여 섬유 방사 공정을 최적화함. 이 데이터 기반 접근법은 공정 변수를 자동으로 조정하여 원하는 강도와 신율을 가진 섬유를 생산하는 최적의 레시피를 추천함.
- 주요 결과 및 결론: 실제 방사 공정 데이터에 제안된 알고리즘을 적용하여, 사전 경험이 없는 고강도 섬유 생산을 위한 22개의 최적 공정 레시피를 도출함. 검증 결과, 86%의 정확도를 달성하며 제안 방법의 실용적 효용성을 입증함.
- 기여점: 기존의 전문가 경험이나 시행착오에 의존하던 방사 공정 최적화를 데이터 기반 강화학습으로 대체함. 이를 통해 생산 비용과 시간을 절감하고, 지능형 제조 기술의 학술적, 산업적 이해와 적용을 촉진하는 방법론을 제시함.
요약
초록
본 연구는 데이터 기반 강화학습 알고리즘을 통해 섬유 제조의 방사 공정을 최적화하는 방법을 제안한다. 특히 섬유의 강도와 신율 특성을 향상시키는 것을 목표로 한다. Q-러닝 알고리즘을 사용하며, 보상 계산은 사전에 구축된 강도 및 신율 예측 회귀 모델의 통찰을 활용한다. 이 데이터 기반 접근법은 기존의 실험적 방법에 비해 생산 비용과 시간을 줄이고, 학계와 산업계 모두에서 지능형 제조 기술의 이해와 적용을 증진시킨다.
서론
4차 산업혁명 시대에 스마트 제조가 부상하면서, 복잡한 품질 변수를 가진 섬유 산업도 기술 혁신이 요구된다. 기존의 방사 공정은 작업자의 숙련도에 의존하거나 시행착오를 겪는 경우가 많아 품질 관리에 어려움이 있었다. 이 연구는 강화학습, 특히 Q-러닝 알고리즘을 섬유 제조 공정에 통합하여 강도와 신율 같은 핵심 물성을 최적화하는 혁신적인 전략을 제시한다. 이를 통해 이론적 발전과 실제 산업 현장 간의 격차를 줄이고자 한다.
배경
섬유 제조 공정 중 합성 섬유를 생산하는 용융 방사(melt spinning)는 최종 제품의 품질을 결정하는 핵심 단계이다. 이 공정은 비선형적 특성 때문에 정밀한 제어가 어렵다. 인공지능, 특히 강화학습(RL)은 이러한 복잡한 문제를 해결하는 데 효과적이다. 강화학습은 마르코프 결정 과정(MDP) {S, A, T, R}을 기반으로 에이전트가 환경과의 상호작용을 통해 최적의 행동 정책을 학습한다. 그중 Q-러닝은 환경에 대한 사전 모델 없이 최적의 행동을 학습할 수 있는 대표적인 알고리즘이다.
모델 아키텍처 / 방법론
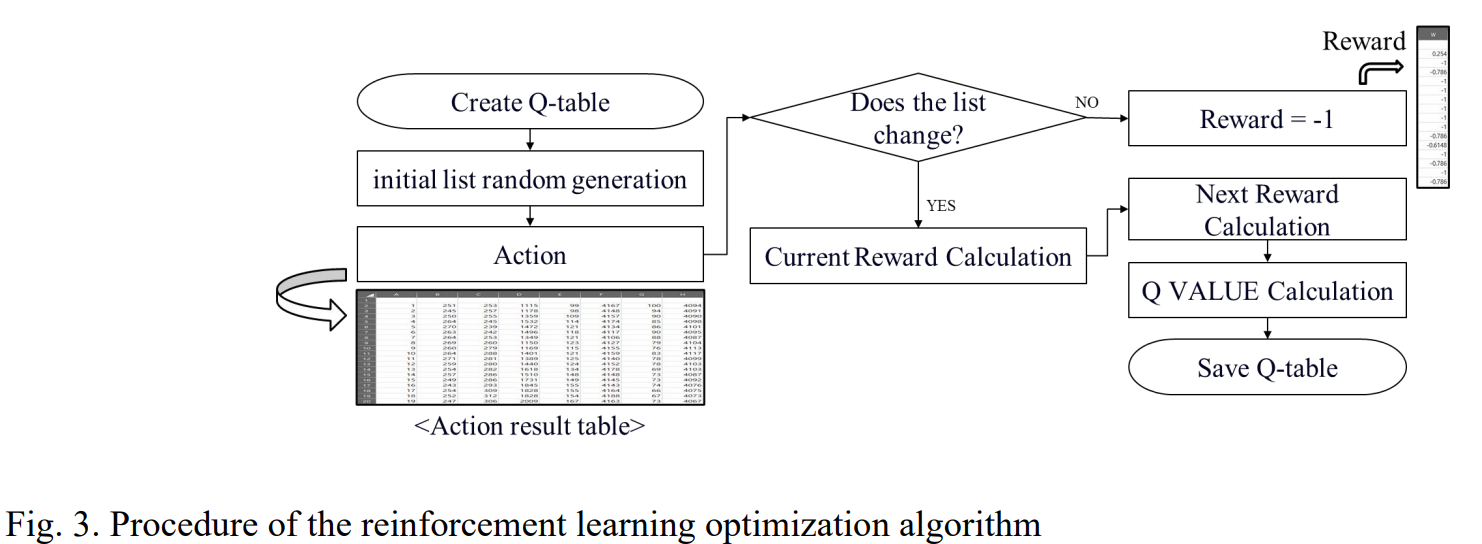
- 핵심 구조/방법: 논문에서 제안한 강화학습 최적화 알고리즘의 절차는 논문의 Figure 3에 시각적으로 표현되어 있다. 알고리즘은 무작위로 생성된 초기 공정 설정 목록에서 시작한다. 이후 행동(Action)을 통해 공정 목록을 변경하고, 변경된 목록에 대한 보상을 계산하여 Q-테이블을 업데이트한다. 보상 계산에는 이전에 구축된 LSTM 회귀 예측 모델이 사용된다.
- 주요 구성 요소:
- 상태(State): 각 공정 변수들이 가질 수 있는 값의 범위 내에서 특정 값으로 정의.
- 행동(Action): 현재 상태에서 공정 변수 값을 조정하는 것.
- 보상(Reward): 변경된 공정 값으로 예측된 섬유의 품질(강도, 신율)을 평가하여 계산. 목록에 변화가 없으면 -1의 보상을 부여.
- 수식: 정책 선택과 Q-가치 업데이트에는 다음 수식이 사용된다.
- 정책(Policy):
- Q-가치 업데이트:
- 알고리즘: 입실론-탐욕(epsilon-greedy) 정책에 따라 행동을 선택하며, 가장 높은 Q-가치를 가진 행동을 선택하거나 무작위 탐색을 수행한다. 이 과정을 반복하여 최적의 공정 레시피를 찾는 Q-테이블을 완성한다.
실험 결과
- 주요 데이터셋: 한국섬유개발연구원에서 제공한 실제 용융 방사 공정 데이터를 사용했다. 초기 데이터는 50개 변수를 포함한 1,525개 항목으로 구성되었다. 분산 분석(ANOVA) 및 다변량 분산 분석(MANOVA)을 통해 고정 변수와 결측치를 제거하고, 강도 및 신율에 유의미한 영향을 미치는 7개의 핵심 독립 변수(예: Spinbeam 온도, GODET 롤러 속도 등)를 식별했다.
- 핵심 성능 지표: 통계 분석을 통해 식별된 7개의 주요 변수들이 섬유의 강도와 신율에 95% 이상의 신뢰수준(P-value < 0.05)에서 유의미한 영향을 미침을 확인했다. 최종적으로 제안된 모델은 실제 생산 테스트에서 높은 정확도를 보였다.
- 비교 결과: 이 연구를 통해 공장에서 생산 경험이 없던 고강도 섬유를 만들기 위한 22개의 최적 공정 레시피를 도출했다. 이 레시피들을 기반으로 실제 생산 테스트를 진행한 결과 86%의 정확도를 달성했다. 이는 기존의 시행착오 방식에 비해 훨씬 효율적이고 정밀한 방법임을 입증한다.
결론
본 연구는 강화학습(Q-러닝)을 섬유 방사 공정 최적화에 성공적으로 적용했다. 통계 분석으로 핵심 변수를 식별하고 이를 강화학습 모델에 통합함으로써, 작업자의 개입 없이 효율적이고 정밀하게 최적의 공정 시나리오를 생성할 수 있었다. 실제 데이터를 활용한 사례 연구에서 86%의 정확도를 달성하여 제안 방법론의 실용성을 입증했다. 이 데이터 기반 접근법은 생산 비용 절감, 품질 향상, 의사결정 과정 개선에 기여하며, 향후 지능형 알고리즘이 섬유 제조 공정의 차세대 혁신을 이끌 것임을 보여준다.