An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition
논문 정보
- 제목: An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition
- 저자: Baoguang Shi, Xiang Bai, Cong Yao (Huazhong University of Science and Technology)
- 학회/저널: IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
- 발행일: 2016-12-28
- DOI: 10.1109/TPAMI.2016.2646371
- 주요 연구 내용: 이미지 기반 시퀀스 인식을 위해 Convolutional Neural Network(CNN)와 Recurrent Neural Network(RNN)을 통합한 새로운 아키텍처인 CRNN(Convolutional Recurrent Neural Network)을 제안함. 이 모델은 특징 추출(CNN), 시퀀스 모델링(RNN), 전사(Transcription)의 세 부분을 하나의 프레임워크로 결합하여 문자 단위의 레이블 없이 종단간(End-to-End) 학습이 가능함.
- 주요 결과 및 결론: IIIT-5K, SVT, ICDAR 등 표준 장면 텍스트 인식 벤치마크에서 기존 최고 수준의 알고리즘들과 대등하거나 더 우수한 성능을 보임. 또한, 제안된 모델은 훨씬 적은 파라미터(8.3M)를 사용하여 효율적이며, 악보 인식과 같은 다른 시퀀스 인식 문제에도 일반화될 수 있음을 확인함.
- 기여점: 기존 방법들과 달리 구성 요소를 개별적으로 훈련할 필요 없는 완전한 종단간 학습이 가능함. 문자 분할이나 정규화 과정 없이 임의 길이의 시퀀스를 자연스럽게 처리하며, 사전(lexicon) 유무에 관계없이 높은 성능을 달성함.
요약
초록
이미지 기반 시퀀스 인식은 컴퓨터 비전 분야의 오랜 연구 주제이다. 본 논문에서는 그중에서도 가장 중요하고 도전적인 과제인 장면 텍스트 인식 문제를 다룬다. 이를 위해 특징 추출, 시퀀스 모델링, 전사(transcription)를 하나의 프레임워크로 통합한 새로운 신경망 아키텍처를 제안함. 제안된 아키텍처는 기존 시스템과 비교하여 네 가지 뚜렷한 특징을 가진다: (1) 개별 구성 요소를 따로 학습시키던 기존 방식과 달리 종단간 학습이 가능하다, (2) 문자 분할이나 수평 스케일 정규화 없이 임의 길이의 시퀀스를 자연스럽게 처리한다, (3) 특정 사전에 국한되지 않으며, 사전 기반 및 비사전 기반 인식 작업 모두에서 뛰어난 성능을 보인다, (4) 실제 적용에 더 실용적인, 효과적이면서도 훨씬 작은 모델을 생성한다. IIIT-5K, Street View Text, ICDAR 데이터셋에서의 실험은 제안된 알고리즘의 우수성을 입증한다. 나아가, 이미지 기반 악보 인식 작업에서도 좋은 성능을 보여 모델의 일반성을 확인했다.
서론
최근 딥러닝, 특히 DCNN(Deep Convolutional Neural Networks)의 성공으로 신경망 연구가 활발해졌지만, 대부분 객체 탐지나 분류에 집중되어 있다. 장면 텍스트, 필기체, 악보와 같은 시각적 객체들은 분리된 형태가 아닌 시퀀스 형태로 나타나는 경향이 있다. 이러한 시퀀스 객체들은 길이가 가변적이기 때문에 고정된 크기의 입출력을 다루는 DCNN을 직접 적용하기 어렵다. 기존에는 문자를 하나씩 검출하고 인식하거나, 단어 자체를 하나의 클래스로 취급하는 방식을 사용했으나, 이는 각각 강력한 문자 검출기를 요구하거나 일반화가 어려운 단점이 있었다. RNN은 시퀀스 처리에 적합하지만, 입력 이미지를 특징 시퀀스로 변환하는 전처리 과정이 필요해 종단간 학습이 불가능했다. 본 논문에서는 DCNN과 RNN을 결합한 CRNN(Convolutional Recurrent Neural Network)을 제안하여 이러한 문제들을 해결하고자 한다.
모델 아키텍처 / 방법론
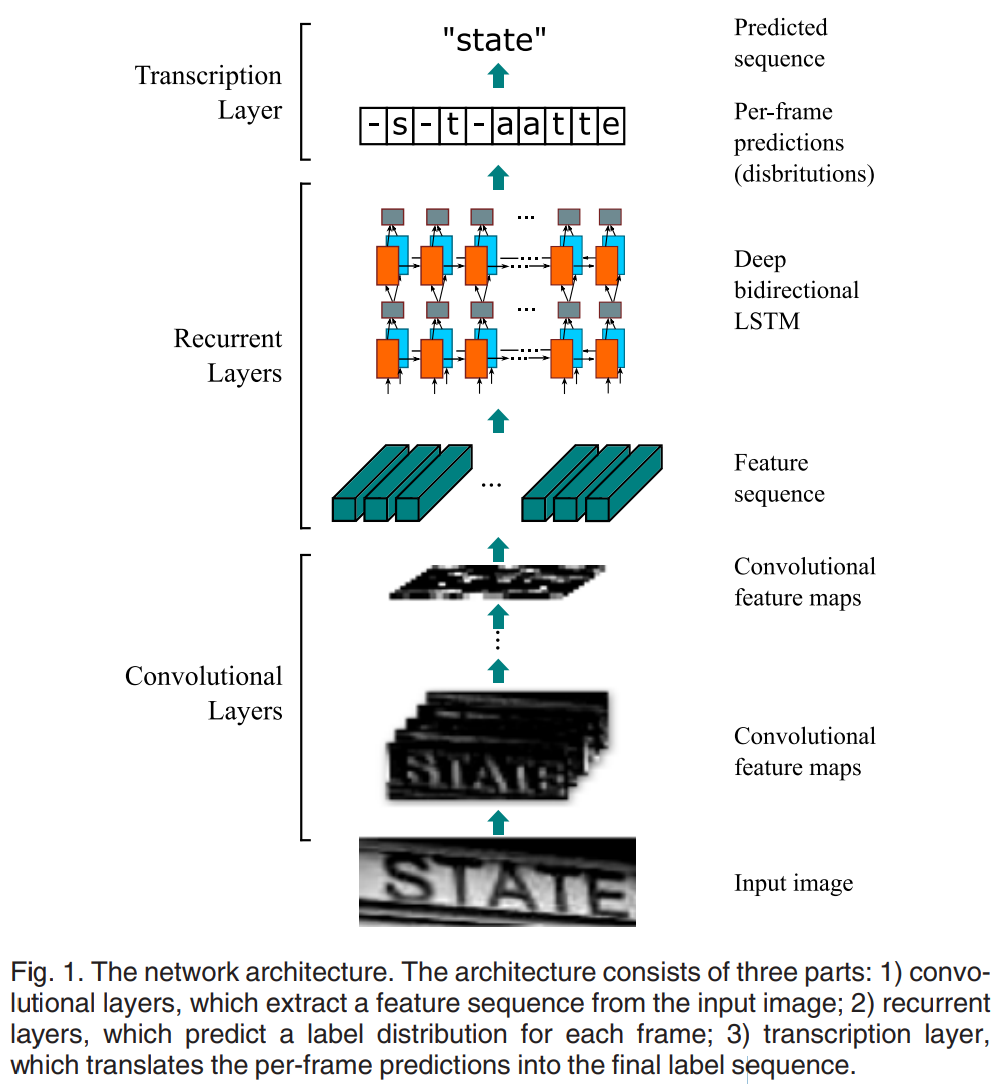 논문의 Figure 1에서 제시된 모델 구조도는 CRNN의 전체적인 흐름을 보여준다. 아키텍처는 컨볼루션 계층, 순환 계층, 전사 계층의 세 부분으로 구성된다.
논문의 Figure 1에서 제시된 모델 구조도는 CRNN의 전체적인 흐름을 보여준다. 아키텍처는 컨볼루션 계층, 순환 계층, 전사 계층의 세 부분으로 구성된다.
-
핵심 구조/방법:
- 컨볼루션 계층 (Feature Sequence Extraction): 표준 DCNN 모델(VGGNet 기반)에서 완전 연결 계층을 제거한 형태로, 입력 이미지로부터 특징 맵(feature map)을 추출한다. 이 특징 맵을 세로로 스캔하여 순차적인 특징 벡터 시퀀스를 생성한다. 이 방식은 이미지의 너비(즉, 시퀀스 길이) 변화에 강건하다.
- 순환 계층 (Sequence Labeling): 컨볼루션 계층에서 추출된 특징 시퀀스를 입력으로 받아, 각 프레임(특징 벡터)에 대한 레이블 분포를 예측한다. 여기서는 양방향 LSTM(Bidirectional LSTM)을 여러 층으로 쌓은 깊은 Bi-LSTM 구조를 사용하여 시퀀스 내의 양방향 컨텍스트 정보를 효과적으로 포착한다.
- 전사 계층 (Transcription): 순환 계층의 프레임 별 예측 결과를 최종 레이블 시퀀스로 변환한다. 이 과정에서 Connectionist Temporal Classification(CTC) 손실 함수를 사용한다. CTC는 프레임별 예측 결과와 최종 시퀀스 간의 정렬을 자동으로 학습하므로, 문자 단위의 정확한 위치 정보 없이도 종단간 학습이 가능하게 한다.
-
수식:
- CTC는 B 변환을 통해 반복되는 레이블과 'blank'를 제거하여 최종 시퀀스를 만든다(예:
B(-h-e-ll-o--)->"hello"). 조건부 확률은 다음과 같이 정의된다. - 여기서 은 최종 레이블 시퀀스, 는 프레임별 예측 시퀀스, 는 RNN의 출력 확률 분포다.
- 네트워크 학습의 목적 함수는 전체 학습 데이터셋 에 대한 음의 로그 우도(negative log-likelihood)를 최소화하는 것이다.
- CTC는 B 변환을 통해 반복되는 레이블과 'blank'를 제거하여 최종 시퀀스를 만든다(예:
-
알고리즘:
- 네트워크는 이미지와 그에 해당하는 단어 시퀀스 쌍으로 구성된 데이터셋을 사용하여 종단간으로 학습된다.
- 최적화에는 SGD(Stochastic Gradient Descent)와 ADADELTA를 사용하여 학습률을 자동으로 조정하고 빠른 수렴을 유도한다.
- 전사 과정은 사전에 제약받지 않는 'Lexicon-Free' 방식과, 주어진 사전 내에서 최적의 단어를 찾는 'Lexicon-Based' 방식 두 가지로 나뉜다. 후자의 경우, BK-tree 자료구조를 사용하여 대규모 사전에서도 효율적인 검색이 가능하다.
실험 결과
- 주요 데이터셋: 학습에는 8백만 개의 이미지로 구성된 합성 텍스트 데이터셋(Synth)을 사용했으며, 별도의 파인튜닝 없이 실제 데이터셋에 대한 평가를 진행했다. 평가에는 ICDAR 2003 (IC03), ICDAR 2013 (IC13), IIIT 5k-word (IIIT5k), Street View Text (SVT) 벤치마크를 사용했다.
- 핵심 성능 지표:
- Table 2에 요약된 결과에 따르면, CRNN은 사전(lexicon)을 사용하는 경우와 사용하지 않는 경우 모두에서 높은 인식 정확도를 달성했다.
- 사전 미사용(None): SVT 데이터셋에서 82.7%, IC03에서 **91.9%**의 정확도를 기록하며 기존 방법들 대비 뛰어난 성능을 보였다.
- 사전 사용: IIIT5k ('50' lexicon)에서 97.8%, SVT ('50' lexicon)에서 **97.5%**의 정확도를 달성하며, 대부분의 경우에서 기존 최고 성능을 능가했다.
- 비교 결과:
- Table 3의 비교 분석에 따르면, CRNN은 종단간 학습이 가능하고, 문자 단위의 주석(GT)이 필요 없으며, 사전에 제약받지 않는다는 장점을 가진다.
- 특히 모델 크기가 8.3MB로, 300MB가 넘는 다른 딥러닝 기반 모델들에 비해 매우 작고 효율적이다.
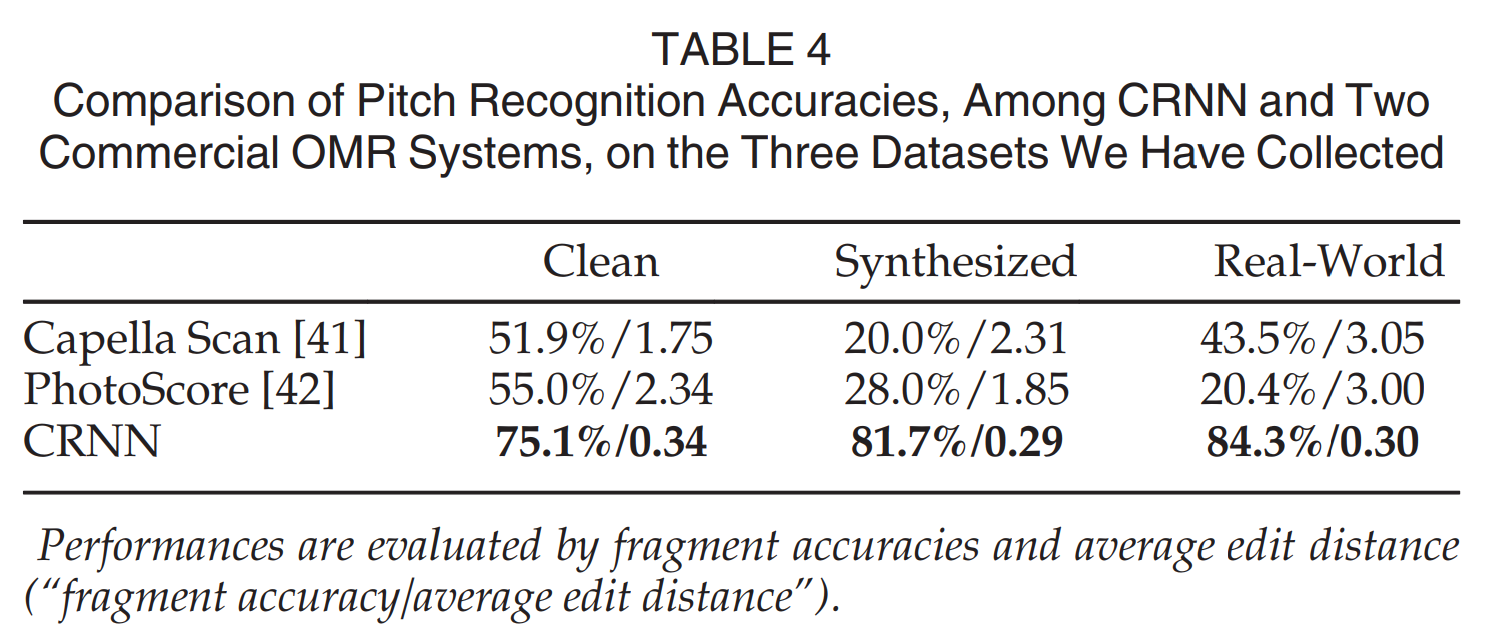
- 악보 인식 실험에서도 상용 OMR 엔진보다 월등히 높은 정확도를 보여(Table 4), CRNN의 일반성과 강인함을 입증했다.
결론
본 연구는 DCNN의 강력한 특징 추출 능력과 RNN의 시퀀스 모델링 능력을 결합한 CRNN 아키텍처를 제안했다. CRNN은 가변적인 크기의 이미지를 입력받아 다양한 길이의 예측을 생성할 수 있으며, 단어와 같은 대략적인 수준의 레이블만으로 학습이 가능하다. 또한, 기존 신경망의 완전 연결 계층을 제거하여 훨씬 작고 효율적인 모델을 구현했다. 장면 텍스트 인식 벤치마크에서의 실험 결과는 CRNN이 기존 방법들보다 우수하거나 매우 경쟁력 있는 성능을 보임을 증명했으며, 악보 인식 과제를 통해 그 일반성을 확인했다.