Cross-dataset learning and person-specific normalisation for automatic Action Unit detection
논문 정보
- 제목: Cross-dataset learning and person-specific normalisation for automatic Action Unit detection
- 저자: Tadas Baltrušaitis, Marwa Mahmoud, Peter Robinson (Computer Laboratory, University of Cambridge, United Kingdom)
- 학회/저널: IEEE International Conference on Automatic Face and Gesture Recognition (FG) 2015
- 발행일: 2015
- DOI: 10.1109/FG.2015.7284869
- 주요 연구 내용: 실시간 AU(Facial Action Unit) 감지 및 강도 추정 시스템을 제안함. 외형(HOG) 및 기하학적(landmark) 특징을 사용. 개인별 중립 표정 차이를 보정하기 위해 간단한 중간값(median) 기반 특징 정규화 기법을 사용.
- 주요 결과 및 결론: 제안한 시스템이 FERA 2015 챌린지의 3가지 태스크(AU 발생 감지, 완전 자동 AU 강도, 사전 분할 AU 강도 추정)에서 모두 기준선(baseline) 성능을 능가함. 여러 데이터셋을 함께 훈련(cross-dataset learning)하는 것이 일반화(generic) 모델 훈련에 이점을 보임.
- 기여점: 특정 AU 감지 시 개인 맞춤형 중립 표정 정규화의 이점을 시연. 일반화 모델 훈련을 위한 다중 데이터셋 사용의 이점을 시연. 20-30fps로 실시간 실행 가능한 전체 AU 감지 파이프라인을 제시.
요약
초록
얼굴 행동 단위(AU)의 자동 감지는 얼굴 분석 시스템에 중요함. 개인차가 크기 때문에 분류기 성능은 훈련 데이터와 중립 표정 추정 능력에 좌우됨. 본 논문은 외형(HOG)과 기하학적 특징(형상 파라미터, 랜드마크 위치)에 기반한 실시간 AU 강도 추정 및 발생 감지 시스템을 제시함. 실험을 통해 서로 다른 데이터셋의 레이블된 데이터를 추가로 사용하는 것이 접근법의 일반화 가능성을 보여주며 이점을 입증함. 이는 특정 데이터셋을 위한 훈련이나 일반 모델이 필요할 때 모두 유효함. 또한, 개인별 중립 표정을 고려하는 간단하고 효율적인 중간값 기반 특징 정규화 기법의 이점도 보임. FERA 2015 챌린지의 세 가지 태스크 모두에서 제안한 결과가 기준선 성능을 능가함을 보임.
서론
얼굴 표정 분석을 통한 정서 및 인지 상태의 기계적 이해에 대한 관심이 증가했음. 얼굴은 비언어적 소통의 주 채널이므로, 얼굴 표정 분석은 인간-컴퓨터 상호작용(HCI)이나 우울증 같은 의학적 상태 연구 등 다양한 분야에 활용됨. 자동 AU 감지 및 분석은 이러한 표정 분석의 핵심 구성 요소임. 하지만 불균형한 훈련 데이터셋, 개인차(중립 표정의 보편적 기준 부재), 포즈 변화, 가려짐 등 많은 난제가 있음. 본 논문은 외형 및 기하학적 특징에 기반한 실시간 AU 감지 접근법을 제시함. 개인차 문제는 개인 맞춤형 정규화 접근법을 사용하여 해결하며, 교차 데이터셋 학습이 AU 감지 성능을 향상시킬 수 있음을 보임.
배경
AU 인식은 많은 주목을 받아왔음. 이전 연구들에서 데이터셋 간 일반화가 가능함이 밝혀졌으나, 훈련 데이터셋에 성능이 크게 영향받고 데이터셋의 균형이 중요함이 지적됨. 본 연구는 광범위한 데이터셋에서 차원 축소 기법을 학습하여 일반화 가능성을 향상시킴. 또한, 기존의 복잡한 개인화 기법과 달리, 더 간단하고 온라인 적응이 가능한 방식으로 개인 정규화를 수행함.
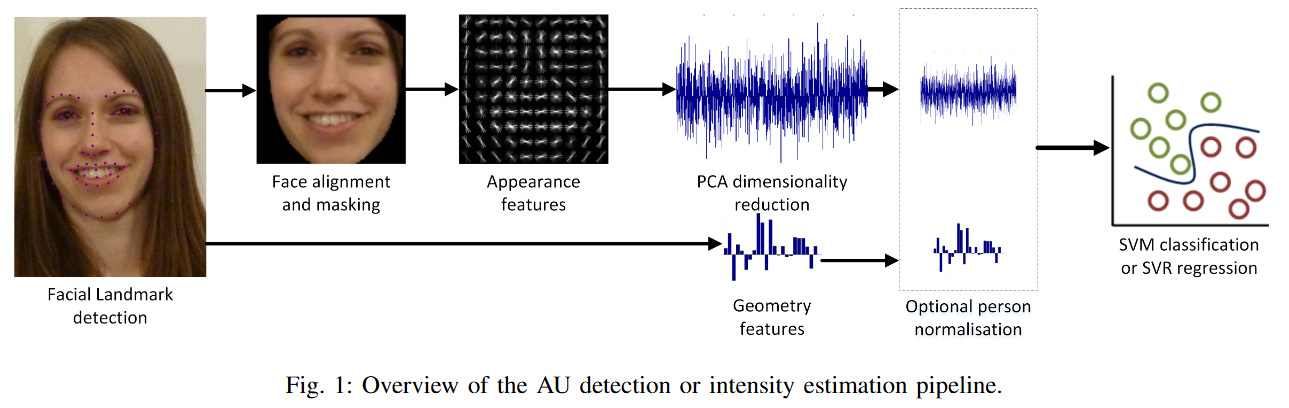
모델 아키텍처 / 방법론
-
핵심 구조/방법: 논문의 Figure 1에서 볼 수 있듯이, 전체 파이프라인은 '얼굴 랜드마크 감지' → '얼굴 정렬 및 마스킹' → '특징 추출(외형/기하학)' → 'PCA 차원 축소' → '(선택적) 개인 정규화' → 'SVM/SVR 분류/회귀' 순서로 진행됨.
-
주요 구성 요소:
- 얼굴 추적: CLNF(Constrained Local Neural Field) 랜드마크 감지기 사용.
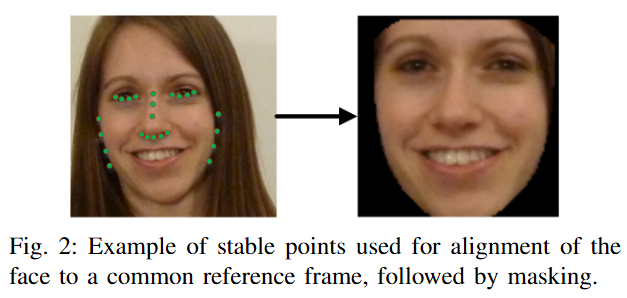
- 정렬 및 마스킹: 표정 변화에도 안정적인 랜드마크 포인트(Figure 2 참조)를 사용하여 얼굴을 픽셀의 공통 이미지 프레임으로 정렬. 비얼굴 영역은 마스킹 처리.
- 외형 특징: 정렬된 이미지에서 HOG(Histograms of Oriented Gradients) 특징 추출. 4464차원 벡터 생성.
- 기하학적 특징: CLNF 모델의 비강체 형상 파라미터(p)와 랜드마크 위치() 사용. 227차원 벡터 생성.
- 차원 축소: HOG 특징을 PCA를 사용해 1379차원으로 축소. CK+, DISFA, AVEC 2011, FERA 2011, FERA 2015 등 여러 데이터셋을 사용해 PCA 기반을 구축하여 일반화 성능 향상.
- 개인 정규화 (Dynamic Model): 개인별 중립 표정을 보정하기 위해, 비디오 시퀀스에서 특징 디스크립터의 중간값(median)을 계산함. 이 중간값을 '중립' 표현으로 간주하고, 현재 프레임의 특징 벡터에서 뺌. 이는 중립 표정이 대부분의 프레임에 나타난다는 가정에 기반함.
-
수식: CLM(Constrained Local Model)의 포인트 분포 모델(PDM)은 다음과 같음.
-
알고리즘:
- 분류/회귀: AU 발생 감지에는 선형 SVM(Support Vector Machines), 강도 추정에는 선형 SVR(Support Vector Regression) 사용. 실시간 성능을 위해 선형 커널을 사용.
- 데이터 불균형 처리: 훈련 데이터에서 음성(negative) AU 샘플을 언더샘플링하여 긍정/음성 샘플 수를 동일하게 맞춤.


실험 결과
-
주요 데이터셋: DISFA, BP4D-Spontaneous, SEMAINE 세 가지 데이터셋을 주로 사용함.
-
핵심 성능 지표 (개인 정규화): 'Dynamic' 모델(중간값 정규화 사용)이 'Static' 모델(정규화 미사용)과 비교됨. 논문의 Table I에 따르면, SEMAINE과 DISFA 데이터셋에서 특정 AU(예: AU 2, 9, 15, 17)의 F1 점수가 크게 향상됨. 반면, 중립 표정이 자주 나타나지 않는 BP4D 데이터셋에서는 효과가 미미하거나 부정적이었음.
-
비교 결과 (교차 데이터셋 학습):
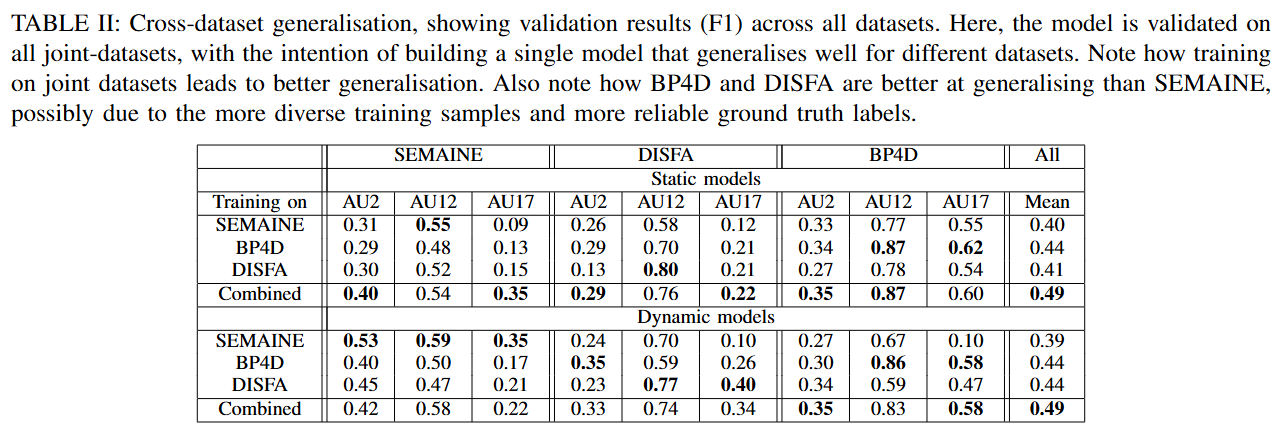
- 일반화 모델 (Generic Model): 여러 데이터셋(Combined)에서 훈련한 모델이 단일 데이터셋(SEMAINE, BP4D, DISFA)에서 훈련한 모델보다 전반적으로 더 나은 일반화 성능(평균 F1)을 보임 (논문의 Table II 참조).
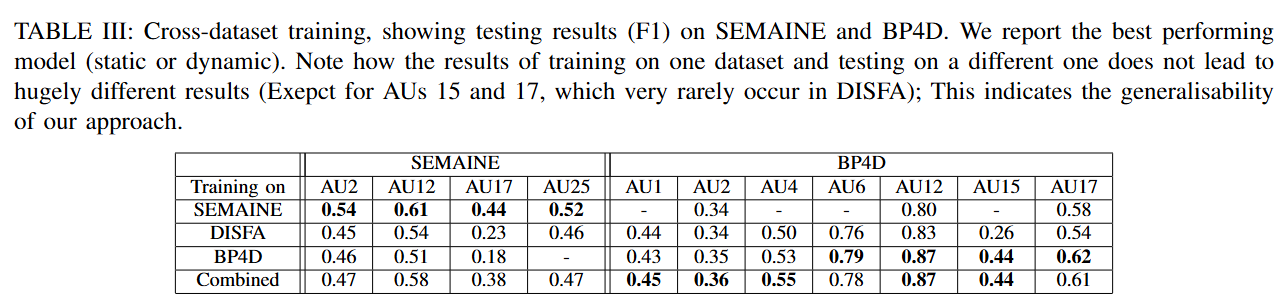
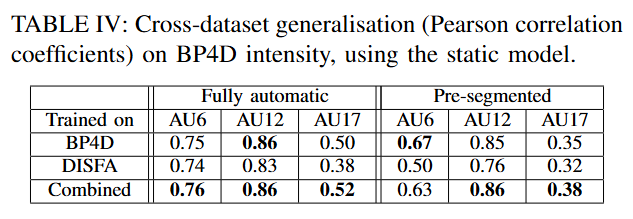
- 표적 모델 (Targeted Model): 특정 데이터셋을 목표로 훈련할 때도, 다른 데이터셋의 데이터를 추가(Combined)하는 것이 성능 향상에 긍정적인 영향을 미침 (논문의 Table III, IV 참조).
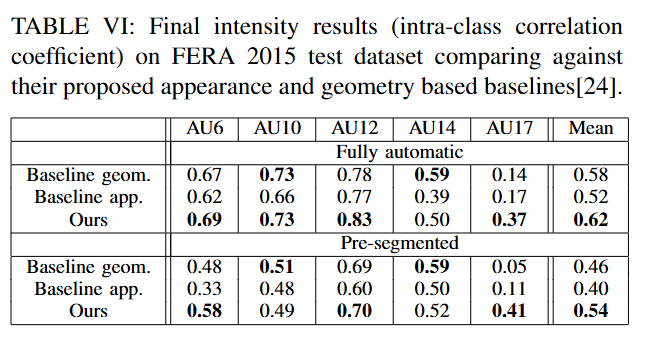
- FERA 2015 챌린지: 제안한 접근법이 FERA 2015 테스트셋에서 3가지 태스크(발생 감지, 강도 추정) 모두에 대해 두 가지 기준선(baseline) 성능을 능가함 (논문의 Table V, VI 참조).
결론
본 논문은 실시간 AU 감지 및 강도 추정 시스템을 제시함. 간단한 개인 맞춤형 중간값 정규화가 SEMAINE, DISFA 데이터셋의 특정 AU 감지에 이점이 있음을 보임. 또한, 결합된 훈련 데이터셋(cross-dataset learning)을 사용하는 것이 일반화 및 표적 모델 모두에서 더 나은 AU 감지기를 만드는 데 도움이 됨을 입증함. FERA 2015 챌린지 결과는 제안한 방법론의 효과성과 일반화 가능성을 보여줌.