Automated machine learning for fabric quality prediction: a comparative analysis
논문 정보
- 제목: Automated machine learning for fabric quality prediction: a comparative analysis
- 저자: Ahmet Metin (Bursa Technical University), Turgay Tugay Bilgin (Bursa Technical University)
- 학회/저널: PeerJ Computer Science
- 발행일: 2024-07-23
- DOI: 10.7717/peerj-cs.2188
- 주요 연구 내용: 7개의 오픈소스 AutoML(FLAML, AutoViML, EvalML, AutoGluon, H2OAutoML, PyCaret, TPOT) 기술을 비교하여 직물 품질 데이터의 불균형 문제를 해결하고, 계산 효율성과 예측 정확성 간의 최적 균형점을 찾는 방법론을 제시. IoT 센서와 ERP 시스템에서 수집된 데이터를 활용하여 품질 예측 모델을 자동화함.
- 주요 결과 및 결론: EvalML이 평균 절대 오차(MAE)에서 2.8282로 가장 우수한 성능을 보였고, AutoGluon은 평균 절대 백분율 오차(MAPE), 평균 제곱근 오차(RMSE), 결정 계수()에서 각각 1.0444, 21.129, 0.964로 가장 나은 성능을 기록함. 그러나 AutoGluon은 추론 시간이 길다는 단점이 있어, 정확성과 계산 효율성 간의 상충 관계를 확인함.
- 기여점: 섬유 산업에서 AutoML 적용에 대한 실용적인 가이드를 제공하고 Industry 4.0 기술을 활용한 직물 품질 예측 향상 로드맵을 제시. 예측 정확성과 계산 효율성 간의 균형점 탐색의 중요성을 강조하고, 모델 해석을 위한 특징 중요도(feature importance) 분석의 유용성을 입증함.
요약
초록
이 연구는 섬유 제조 분야에서 직물 품질 예측을 향상시키기 위해 IoT 센서와 ERP 시스템 데이터를 활용한다. 특히 직물 품질 데이터의 불균형 문제를 해결하기 위해 7가지 오픈소스 AutoML(Automated Machine Learning) 기술(FLAML, AutoViML, EvalML, AutoGluon, H2OAutoML, PyCaret, TPOT)을 비교 평가한다. 연구의 핵심은 계산 효율성과 예측 정확성 사이의 최적의 균형점을 찾는 혁신적인 접근법을 사용하는 것이다. 실험 결과, EvalML은 평균 절대 오차(MAE) 측면에서 가장 뛰어난 성능을 보였고, AutoGluon은 긴 추론 시간에도 불구하고 다른 평가지표(MAPE, RMSE, )에서 우위를 점했다. 또한, 각 AutoML 모델이 제공하는 특징 중요도 순위를 분석하여 예측 결과에 큰 영향을 미치는 속성을 파악했으며, 특히 고유값이 많은 범주형 변수를 특성화하는 데 sin/cos 인코딩이 효과적임을 발견했다.
서론
섬유 산업은 Industry 4.0 기술 도입의 초기 단계에 있으며, 생산 효율성 향상과 품질 관리 절차 간소화에 대한 잠재력이 크다. 기존의 수동 품질 관리 프로세스는 많은 인력을 필요로 하므로, 본 연구는 IoT 센서 및 ERP 시스템에서 수집된 데이터를 기반으로 AutoML을 활용하여 각 제품에 대한 새로운 품질 예측 모델을 생성하는 것을 목표로 한다. 이를 위해 7개의 최신 오픈소스 AutoML 기술을 비교하여 최적의 지도 학습 방법론을 선택하고 관련 하이퍼파라미터를 최적화하는 과정을 자동화하고자 한다.
모델 아키텍처 / 방법론
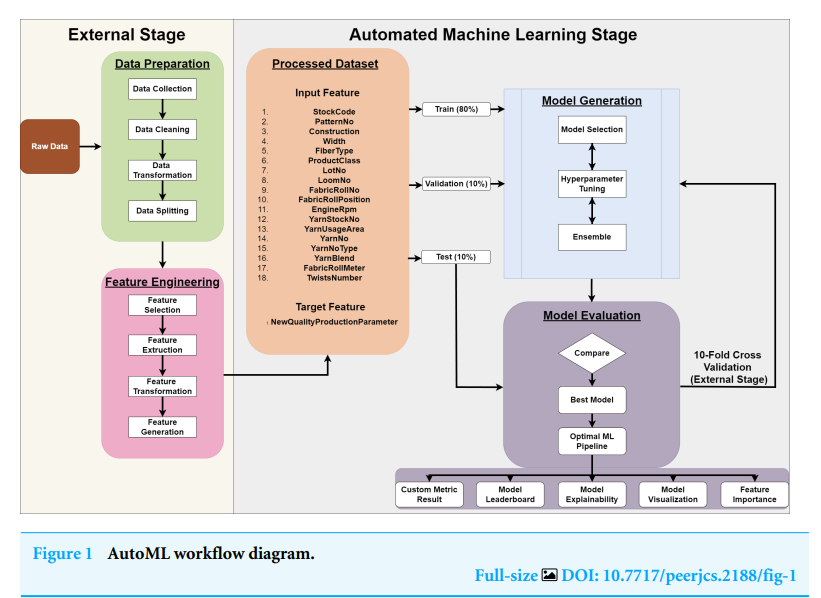
-
핵심 구조/방법: 연구의 전체적인 워크플로우는 논문의 Figure 1에 제시되어 있으며, 'External Stage'(데이터 준비, 특징 공학)와 'Automated Machine Learning Stage'(모델 생성, 모델 평가)로 구성된다. 이 연구에서는 AutoML 도구들의 모델 선택 및 하이퍼파라미터 최적화(HPO) 성능을 공정하게 비교하기 위해 데이터 준비와 특징 공학 단계를 수동으로 수행했다.
-
주요 구성 요소:
- 데이터 소스: 섬유 기계의 IoT 센서 및 ERP 시스템으로부터 수집된 데이터.
- 데이터 전처리: 객체(object) 타입 데이터를 수치형으로 변환하고 결측치 및 중복 데이터를 제거. 연속형 데이터는 Min-Max 정규화를 적용하여 -1에서 1 사이의 값으로 스케일링함.
- 특징 공학: 불균형한 품질 데이터 문제를 해결하기 위해 정지 수량, 정지 시간, 직물 길이, 기존 품질 등급 등의 속성을 조합하여 '신규 품질 생산 파라미터(NQPP)'라는 새로운 타겟 변수를 생성함. 또한, 고유값이 많은 범주형 변수에 대해 원-핫 인코딩의 단점을 보완하고자 Sin/Cos 인코딩 기법을 적용함.
-
수식:
- 총 정지 수량(SQT) 및 총 정지 시간(SDT)은 기계의 각 부분(예: 하단 위사, 상단 경사 등)에서 발생한 정지 수량과 시간의 합으로 계산된다.
- 신규 품질 생산 파라미터(NQPP)는 아래와 같이 정의된다. 이 식은 고장 발생 당 가동 중지 시간을 직물 미터로 정규화하고 품질 등급과 연관시켜 새로운 품질 지표를 생성한다.
- Sin/Cos 인코딩은 범주형 변수 X에 대해 다음과 같이 두 개의 새로운 특징을 생성한다. 여기서 H는 해당 속성의 총 범주 수를 의미한다.
- 총 정지 수량(SQT) 및 총 정지 시간(SDT)은 기계의 각 부분(예: 하단 위사, 상단 경사 등)에서 발생한 정지 수량과 시간의 합으로 계산된다.
-
알고리즘: 비교된 AutoML 도구들은 내부적으로 베이지안 최적화, 유전 알고리즘, 그리드 서치, 랜덤 서치 등 다양한 하이퍼파라미터 최적화(HPO) 기법을 사용한다. 또한, 예측 성능을 높이기 위해 스태킹(stacking), 보팅(voting)과 같은 앙상블 방법을 활용하며, 특히 AutoGluon은 다층 스태킹 구조를 통해 높은 성능을 달성한다.
실험 결과
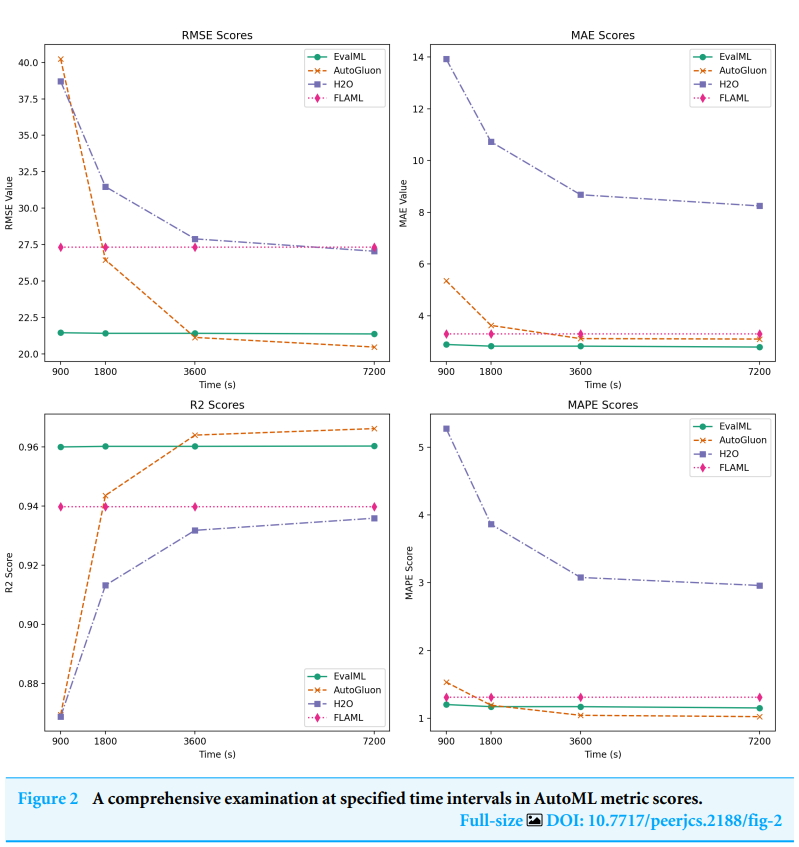
- 주요 데이터셋: 섬유 회사의 R&D 부서에서 2년간 수집한 ERP 및 IoT 센서 데이터. 특징 공학 및 전처리 후 268,474개의 행과 25개의 입력 변수, 1개의 타겟 변수로 구성됨. 데이터는 훈련(80%), 검증(10%), 테스트(10%) 세트로 분할하여 사용됨.
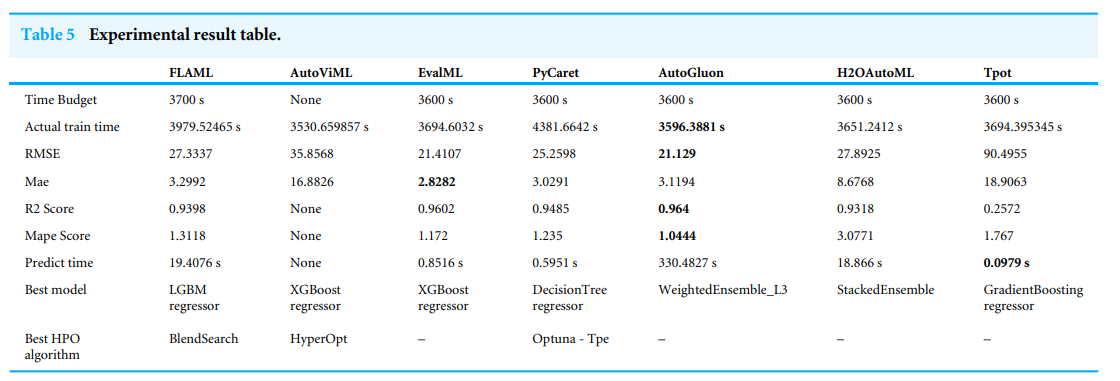
- 핵심 성능 지표: 모델 평가는 MAE, RMSE, , MAPE를 사용했다. 논문의 Table 5에 요약된 결과에 따르면, EvalML은 MAE(2.8282)에서 가장 좋은 성능을 보였다. 반면, AutoGluon은 RMSE(21.129), (0.964), MAPE(1.0444)에서 최고의 성능을 기록했다.
- 비교 결과: EvalML은 설정된 목적 함수(MAE)에 대해 가장 우수한 결과를 보였으며, 특히 추론 시간이 0.85초로 매우 빨랐다. AutoGluon은 다른 세 가지 지표에서 가장 뛰어났지만, 추론 시간이 330.48초로 매우 길어 실시간 예측 환경에서는 단점이 될 수 있다. 논문의 Figure 2는 시간에 따른 성능 변화를 보여주는데, EvalML과 FLAML은 짧은 학습 시간(약 900초) 내에 빠르게 최적 성능에 도달하는 반면, AutoGluon은 학습 시간이 길어질수록 점진적으로 성능이 향상되어 3600초 이후부터 대부분의 지표에서 다른 도구들을 능가했다.
결론
이 연구는 AutoML을 섬유 품질 예측에 성공적으로 적용할 수 있음을 입증했다. MAE를 최소화하고 빠른 추론 시간이 중요한 경우 EvalML이 최적의 선택이며, 전반적인 예측 정확도(RMSE, , MAPE)가 더 중요하다면 긴 학습 및 추론 시간을 감수하고 AutoGluon을 사용하는 것이 유리하다. 연구 결과는 정확성과 계산 비용 간의 상충 관계를 명확히 보여준다. 또한, 모델 해석에 있어 특징 중요도 분석이 유용하며, 특히 고유값이 많은 범주형 데이터에 대한 sin/cos 인코딩의 효과를 확인했다.