컴퓨팅이론 및 시스템 특강
김정근 교수님
교수님께서 만약 비전공자인데 이 수업을 듣게 된다면 보면 좋을 영상이라고 추천해 주신 리스트이다. 시간 날 때 확인해보자.
- 100+ Computer Science Concepts Explained
- CS50x 2024: Introduction to Computer Science
- COMPUTER SCIENCE explained in 17 Minutes
- Computer Science Map
L4
von Neumann Architecture 개요
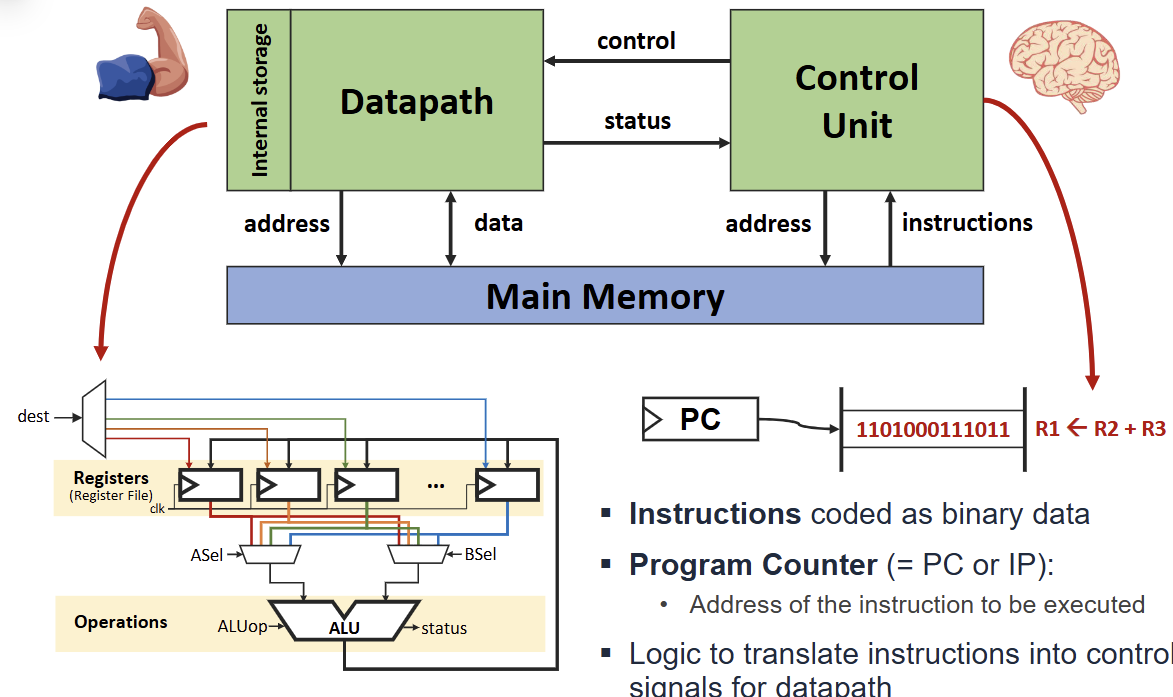
현대의 거의 모든 컴퓨터는 1945년 John von Neumann이 제안한 모델을 기반으로 한다. 이 구조는 크게 Central Processing Unit(CPU), Main Memory, Input/Output 장치로 구성된다.
CPU는 다시 Datapath와 Control Unit으로 나뉜다. Datapath는 레지스터와 메모리의 값에 대해 연산을 수행하는 경로이며, Control Unit은 명령어 실행을 위한 제어 신호를 생성하는 FSM(Finite State Machine) 역할을 한다. Main Memory는 N 비트 크기의 단어(word) W개로 구성된 배열이다.

von Neumann 컴퓨터의 핵심 요소는 다음과 같다.
- Registers: 내부 저장소(Internal storage) 역할을 하는 레지스터 파일.
- ALU(Arithmetic & Logic Unit): 산술 및 논리 연산을 수행한다.
- Program Counter(PC): 실행할 명령어의 주소를 저장한다.
- Control Logic: 명령어를 해석하여 Datapath를 위한 제어 신호로 변환한다.
명령어 처리 과정과 성능 분석
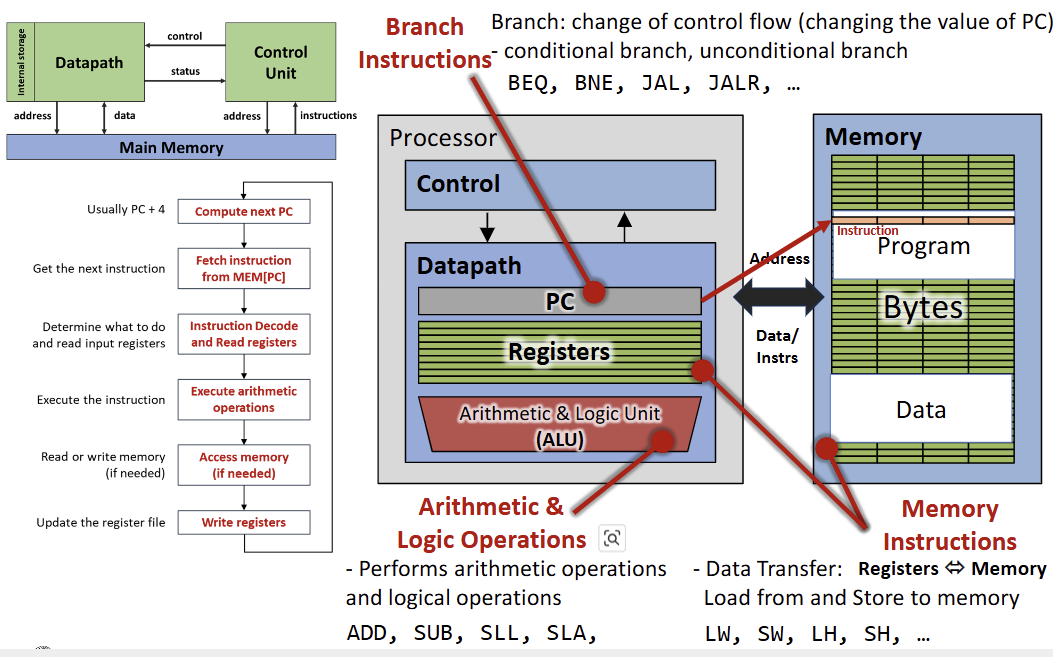
프로세서가 명령어를 처리하는 과정은 일반적으로 다음의 5단계를 거친다.
- Fetch: PC가 가리키는 메모리 주소에서 명령어를 가져온다. 일반적으로 다음 명령어를 위해 PC 값은 4 증가한다.
- Decode: 명령어를 해석하고 입력 레지스터의 값을 읽는다.
- Execute: ALU를 사용하여 산술 연산을 수행하거나 주소를 계산한다.
- Memory Access: 필요한 경우 메모리에서 데이터를 읽거나 쓴다.
- Writeback: 연산 결과를 레지스터 파일에 기록한다.
컴퓨터의 성능은 다음의 성능 방정식(Performance Equation)으로 분석할 수 있다. Execution Time = Instruction Count(IC) * Cycles Per Instruction(CPI) * Cycle Time
- Instruction Count(IC): 프로그램이 실행하는 명령어의 수. ISA, 컴파일러, 알고리즘 등에 영향을 받는다.
- CPI: 명령어 당 소요되는 사이클 수. 마이크로아키텍처, 컴파일러, 알고리즘 등에 영향을 받는다.
- Cycle Time: 한 사이클에 걸리는 시간. 공정 기술, 마이크로아키텍처 등에 영향을 받는다.
Instruction Set Architecture (ISA)
ISA는 하드웨어와 소프트웨어 사이의 인터페이스를 정의한다. 여기에는 명령어 집합, 데이터 타입, 레지스터, 주소 지정 방식(Addressing Modes), 메모리 구조 등이 포함된다. ISA 설계 방식은 크게 RISC와 CISC로 나뉜다.
RISC(Reduced Instruction Set Computer)
- 명령어의 수가 적고 단순하다.
- 모든 명령어가 고정된 길이를 가지며 인코딩이 규칙적이다.
- ALU 연산은 레지스터 간에만 수행되며 메모리 접근은 Load/Store 명령어로만 가능하다.
CISC(Complex Instruction Set Computer)
- 명령어의 수가 많고 복잡하다.
- 명령어의 길이가 가변적이다(예: 1바이트에서 14바이트).
- 복잡한 주소 지정 방식을 지원하며, ALU 연산에서 메모리 피연산자를 직접 사용할 수 있다.
RISC 설계의 4가지 원칙은 다음과 같다.
- Simplicity favors regularity: 규칙적인 구조가 하드웨어 구현을 단순화한다.
- Smaller is faster: 레지스터 파일이 작을수록 접근 속도가 빠르다.
- Make the common case fast: 자주 사용되는 명령어를 최적화한다.
- Good design demands good compromises: 명령어 형식의 규칙성을 유지하면서도 필요한 기능을 수용하기 위해 타협이 필요하다.
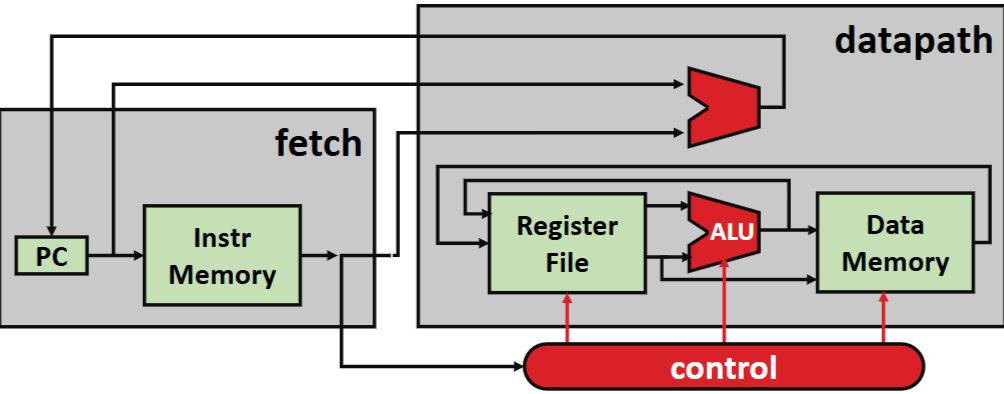
하드웨어 구현과 Datapath
프로세서의 하드웨어는 Combinational Logic과 Sequential Logic으로 구성된다.
- Combinational Logic: 상태가 없는 연산을 수행한다(예: ALU, MUX, Gate).
- Sequential Logic: 상태를 저장한다(예: PC, Memory, Register File).
메모리 아키텍처는 두 가지로 분류된다.
- Unified Architecture: 명령어 메모리와 데이터 메모리가 통합되어 있다(von Neumann 구조).
- Harvard Architecture: 명령어 메모리와 데이터 메모리가 물리적으로 분리되어 있다.
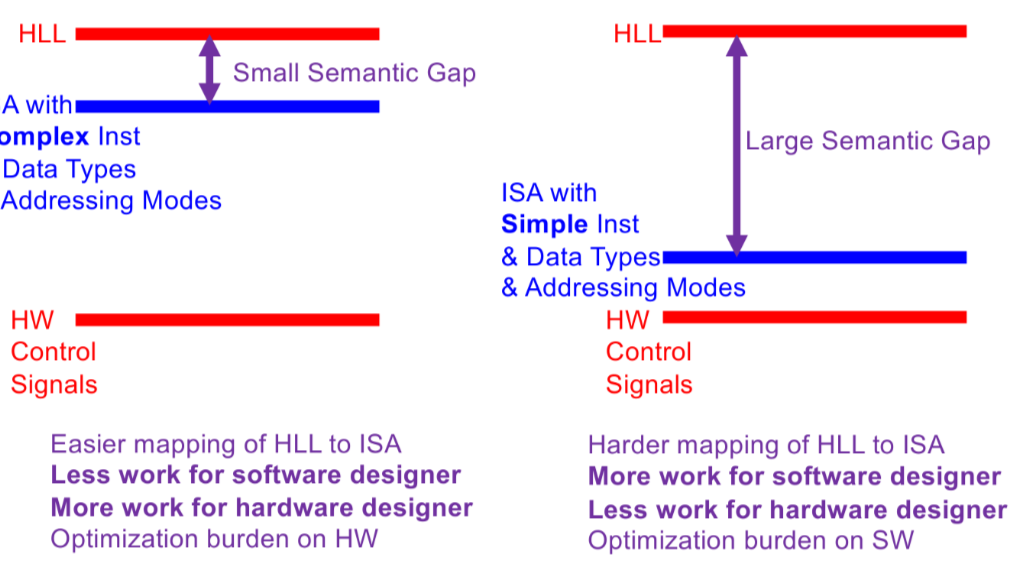
ISA Tradeoffs와 Semantic Gap
Semantic Gap은 High-Level Language(HLL)와 기계어(ISA) 사이의 차이를 의미한다.
- Large Semantic Gap(RISC): 명령어와 데이터 타입이 단순하다. HLL을 ISA로 매핑하는 것이 어려워 소프트웨어(컴파일러)의 부담이 크지만, 하드웨어 설계는 단순해진다.
- Small Semantic Gap(CISC): 복잡한 명령어와 데이터 타입을 지원한다. HLL 매핑이 쉬워 소프트웨어의 부담은 줄어들지만, 하드웨어 회로가 복잡해지고 최적화 부담이 하드웨어로 넘어간다.
주소 지정 방식(Addressing Modes)은 피연산자의 위치를 지정하는 방법이다. ARM 프로세서는 Register, Immediate, Base, PC-relative 등 다양한 방식을 사용한다. 복잡한 주소 지정 방식은 코드를 줄일 수 있지만 Datapath의 복잡도(예: 별도의 덧셈기나 Shifter 필요)를 증가시킨다.
Microarchitecture
Microarchitecture는 ISA를 물리적으로 구현한 것을 의미한다. 동일한 ISA(예: x86, ARM)라도 성능, 전력, 비용 목표에 따라 다양한 Microarchitecture로 구현될 수 있다.
명령어 처리는 Architectural State(AS)를 변환하는 과정으로 정의된다.
- AS: 프로그래머에게 보이는 상태(메모리, 레지스터, PC 등).
- ISA는 AS에서 다음 AS'로의 상태 전이를 추상적으로 정의한다.
- Microarchitecture는 이 상태 전이를 실제로 구현하는 방식이며, 단일 사이클(Single-cycle) 또는 다중 사이클(Multi-cycle) 등을 사용할 수 있다.
반도체 기술과 CMOS
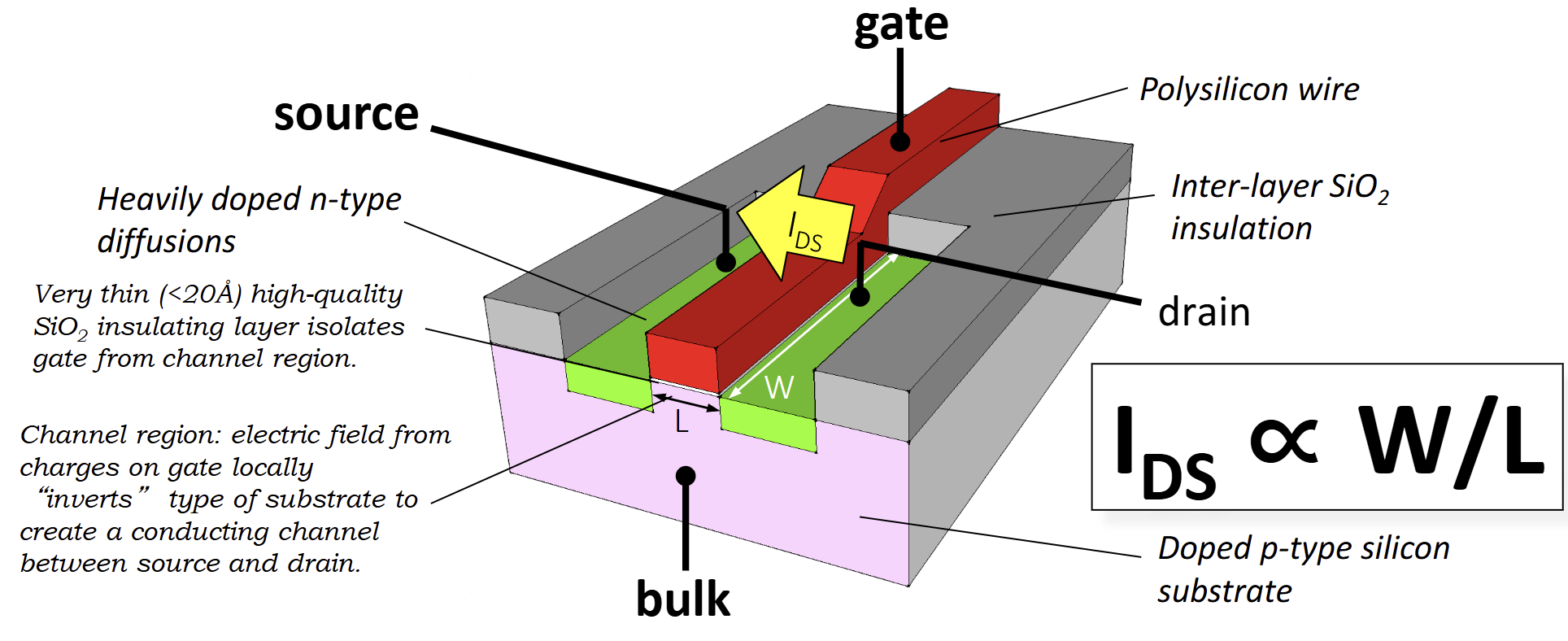
프로세서는 물리적으로 트랜지스터로 구성된다. 현대 프로세서는 주로 MOSFET(Metal-Oxide-Semiconductor Field-Effect Transistor)을 사용한다.
MOSFET의 구조와 동작
- Gate, Source, Drain, Body(Bulk)의 4개 단자로 구성된다.
- Gate 전압에 따라 Source와 Drain 사이에 전류가 흐르는 채널이 형성되어 스위치 역할을 한다.
- N-Channel MOSFET은 Gate 전압이 임계 전압(Vth)보다 높을 때 켜진다.
반도체 공정 기술(Process Technology)
- Scaling(미세화): 트랜지스터의 크기를 줄여 성능을 높이고 전력을 줄이는 과정이다.
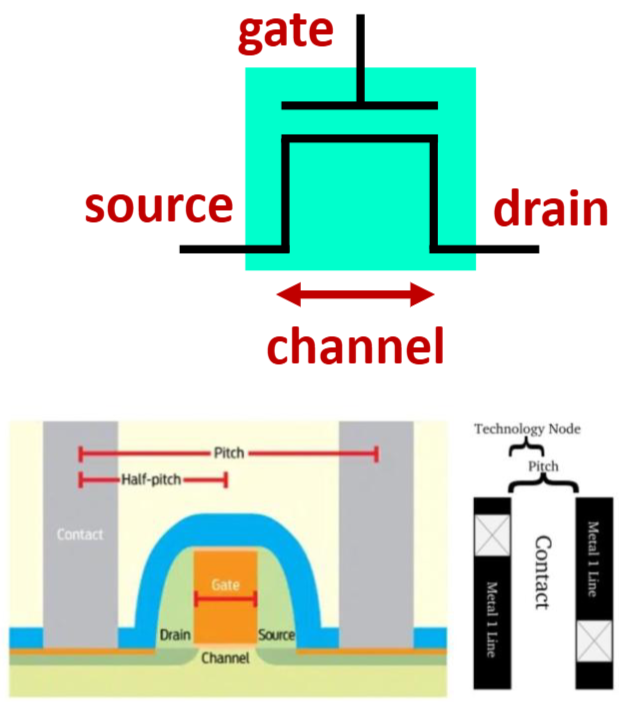
- Technology Node(예: 5nm, 3nm): 과거에는 Gate 길이를 의미했으나, 현재는 마케팅 용어에 가까우며 물리적 치수와 직접 일치하지 않는다.
- Pitch: 인접한 금속 배선 간의 최소 거리이다.
- Channel Length: Source와 Drain 사이의 거리로, 스위칭 속도와 밀접한 관련이 있다.
Semiconductor Fabrication Process Technology
컴퓨터는 수십억 개의 작고 단순한 구조인 트랜지스터로 구성된다. Moore's Law에 따르면 트랜지스터의 수는 약 18~24개월마다 두 배로 증가하며, 이는 컴퓨터 성능 향상의 주요 요인이 된다. 과거 1970년대에는 수천 개의 트랜지스터가 사용되었으나, 최근 Apple의 M2 Max 같은 프로세서는 500억 개 이상의 트랜지스터를 포함한다.
공정 기술(Process Technology)에서 5nm, 3nm와 같은 Process Node라는 용어는 역사적으로는 트랜지스터의 물리적 치수(예: Gate 길이)를 지칭했으나, 현재는 마케팅 용어에 가까우며 물리적 치수와 직접 일치하지 않는다. 인텔의 로드맵은 14nm, 10nm를 거쳐 Angstrom 시대로 진입하고 있으며, FinFET 구조에서 RibbonFET 및 PowerVia 기술로 발전하고 있다.
Transistor: MOSFET 구조와 동작
트랜지스터는 전기적으로 제어되는 스위치 역할을 하며, 현대 프로세서에서는 주로 MOSFET(Metal-Oxide-Semiconductor Field-Effect Transistor)이 사용된다. MOSFET은 Gate, Source, Drain의 3개 단자로 구성된다. Gate에 인가된 전압이 Drain과 Source 사이의 전류 흐름을 제어한다.
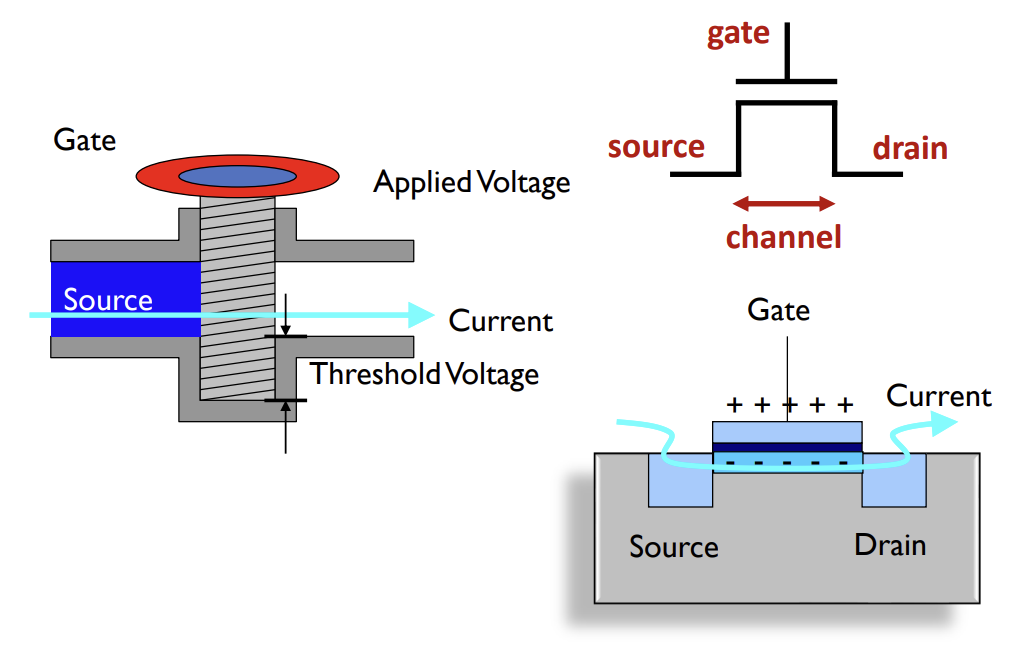
트랜지스터는 두 가지 유형으로 나뉜다.
- NFET (N-type): Gate 전압이 1(High)일 때 켜져서 전류가 흐른다. 0(Ground)을 전달하는 데 효율적이다.
- PFET (P-type): Gate 전압이 0(Low)일 때 켜져서 전류가 흐른다. 1(Power)을 전달하는 데 효율적이다.
CMOS Logic Design
CMOS(Complementary MOS)는 NMOS와 PMOS를 상호 보완적으로 사용하여 논리 게이트를 구성하는 방식이다. CMOS 회로를 구성할 때는 다음의 규칙을 따른다.
- Pull-up Network: PMOS만 사용하며, 출력을 1(Vdd)로 연결하는 역할을 한다.
- Pull-down Network: NMOS만 사용하며, 출력을 0(Ground)으로 연결하는 역할을 한다.
이 구조로 인해 Pull-down이 켜지면 Pull-up은 꺼지고, 그 반대의 경우도 성립하여 전력 소모와 신호 안정성을 최적화한다.

CMOS 게이트는 본질적으로 반전(Inverting) 특성을 가진다. 입력이 상승(0에서 1)하면 NFET이 켜져서 출력이 Ground(0)로 연결되므로 출력은 하강한다. 따라서 CMOS로 구현되는 기본 게이트는 Inverter, NAND, NOR이며, AND나 OR 같은 비반전 논리를 구현하려면 추가적인 Inverter가 필요하다.
Logic Gates와 Digital Abstraction
디지털 회로에서는 전압을 비트(0과 1)로 추상화하여 처리한다.
- Inverter(NOT Gate): 1개의 PMOS와 1개의 NMOS로 구성된다. 입력이 0이면 PMOS가 켜져 출력은 1이 되고, 입력이 1이면 NMOS가 켜져 출력은 0이 된다.
- NAND Gate: 모든 입력이 1일 때만 출력이 0이 된다.
- NOR Gate: 모든 입력이 0일 때만 출력이 1이 된다.
- Tristate Buffer: 0, 1 외에 Hi-Z(High Impedance) 상태를 가진다. Enable 신호가 0이면 출력은 끊어진 상태(Hi-Z)가 되어 다른 장치가 버스를 제어할 수 있게 한다.
Timing과 Delay
논리 회로에서 입력이 변한 후 출력이 업데이트되기까지는 시간이 소요되며, 이를 Gate Delay라고 한다. 현대 회로에서는 나노초(ns) 또는 피코초(ps) 단위이다.
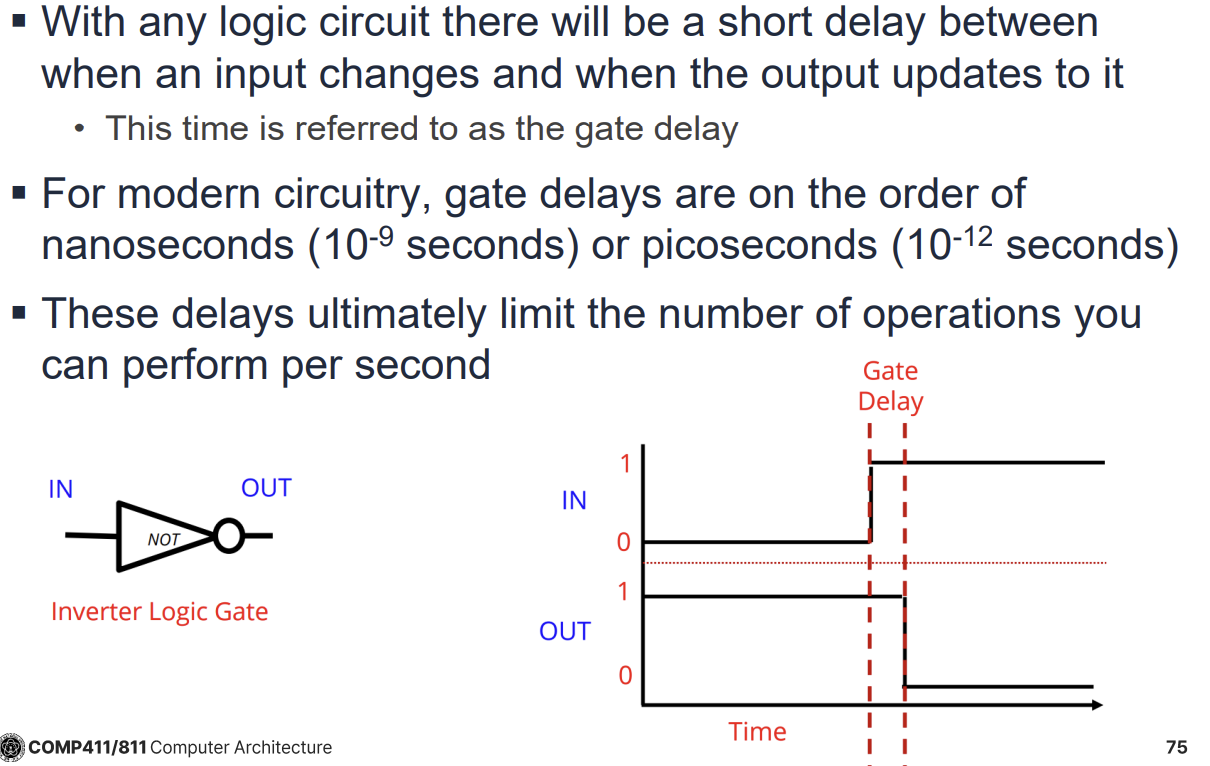
지연 시간은 두 가지로 정의된다.
- Propagation Delay (tPD): 입력이 유효해진 후 출력이 유효한 값으로 확정되기까지 걸리는 최대 시간(Upper Bound)이다. 회로 설계의 목표는 이 tPD를 최소화하는 것이다.
- Contamination Delay (tCD): 입력이 변한 후 출력이 변하기 시작(유효하지 않게 됨)할 때까지 걸리는 최소 시간(Lower Bound)이다.
Combinational Contract에 따르면, 모든 입력이 tPD 이상 유효하게 유지되면 출력도 유효함이 보장된다. Lenient Combinational Device는 출력을 결정하기에 충분한 일부 입력만 유효해도 출력이 유효해지는 특성을 가진다.
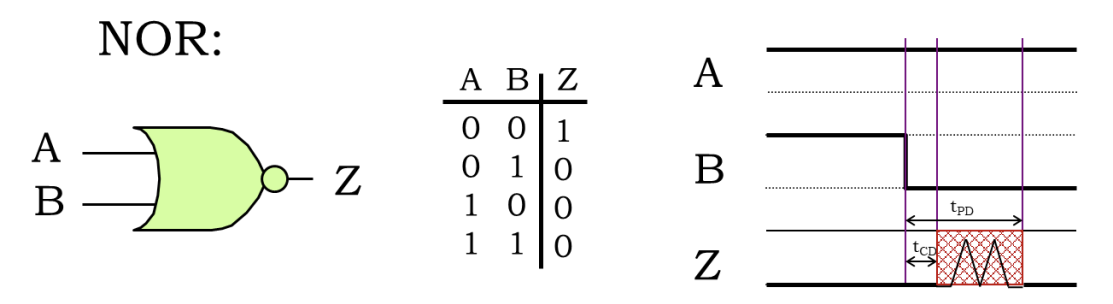
Combinational Logic 개요
디지털 회로는 크게 Combinational Logic(조합 논리)과 Sequential Logic(순차 논리)으로 분류된다.
- Combinational Logic: 출력이 오직 현재의 입력값에 의해서만 결정된다. 상태(State)나 메모리가 없는 무기억(Memoryless) 회로이다. 예시로는 Adder, Multiplexer, Decoder, Encoder 등이 있다.
- Sequential Logic: 출력이 현재 입력뿐만 아니라 과거의 입력 이력(History)에도 의존한다. 상태 변수(State Variable)를 가지며 클럭(Clock)을 사용한다. 예시로는 Latch, Flip-flop, Processor 등이 있다.
Combinational Circuit은 두 가지 명세(Specification)로 정의된다.
- Functional Specification: 입력 조합에 대해 어떤 출력이 나오는지 정의한다 (Truth Table, Boolean Equation).
- Timing Specification: 출력을 생성하는 데 시간이 얼마나 걸리는지 정의한다 (Propagation Delay).
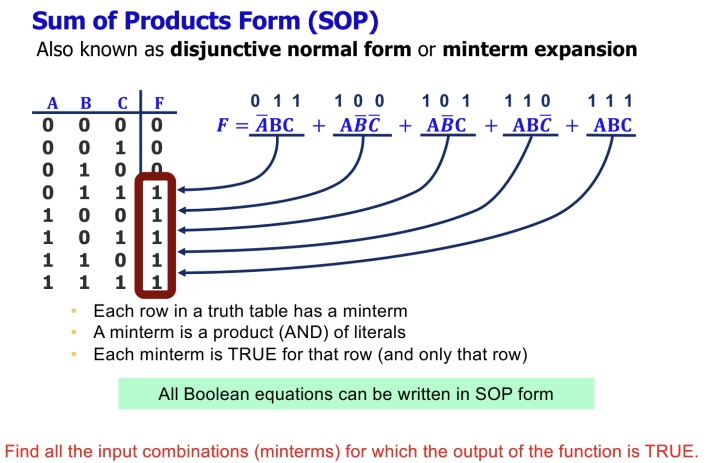
Boolean Algebra와 표현 방식
Boolean Algebra는 0과 1의 변수를 다루는 대수학이다.
- Literal: 변수 또는 그 변수의 보수(Complement, 예: A, A').
- Minterm: 모든 입력 변수를 포함하는 곱(AND) 항이다. Truth Table의 각 행은 고유한 Minterm에 대응된다.
- Maxterm: 모든 입력 변수를 포함하는 합(OR) 항이다.
Boolean Function을 표현하는 표준화된 방식(Canonical Form)에는 두 가지가 있다.
- Sum of Products (SOP): 출력이 1인 경우의 Minterm들을 OR로 결합한 형태이다.
- Product of Sums (POS): 출력이 0인 경우의 Maxterm들을 AND로 결합한 형태이다.
Timing과 Delay
모든 조합 회로는 입력이 변한 후 출력이 안정화되기까지 지연 시간(Delay)을 가진다.
- Propagation Delay (): 유효한 입력이 들어온 후 유효한 출력이 확정되기까지 걸리는 시간의 상한(Upper Bound)이다. 회로의 동작 속도를 결정짓는 Critical Path(가장 긴 경로)에 해당한다.
- Contamination Delay (): 입력이 변한 후 출력이 변하기 시작할 때까지 걸리는 시간의 하한(Lower Bound)이다.
- Glitch (Hazard): 입력이 변할 때 경로 간의 지연 차이로 인해 출력이 일시적으로 원치 않는 값을 가지는 현상이다.
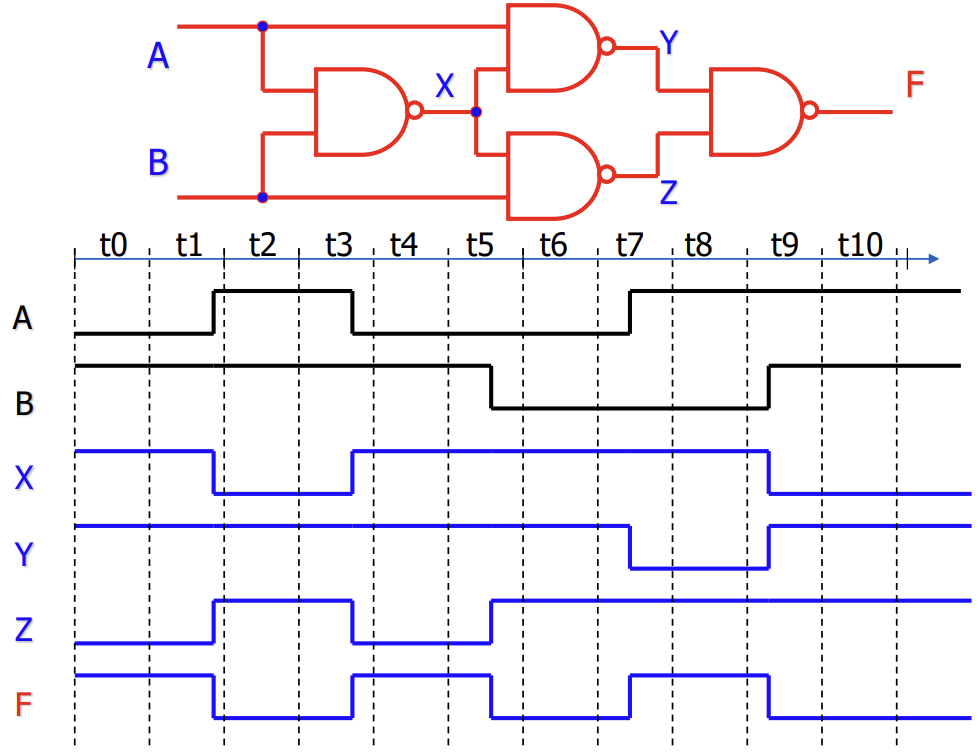
Logic Implementation: PLA, PAL, ROM
Truth Table이나 Boolean Equation을 하드웨어로 구현하는 다양한 방식이 있다.
Programmable Logic Array (PLA)
- 입력, Programmable AND Array, Programmable OR Array로 구성된다.
- SOP 형태의 논리를 효율적으로 구현할 수 있다.
Programmable Array Logic (PAL)
- PLA의 특수한 형태로, AND Array는 프로그래밍 가능하지만 OR Array는 고정되어 있다.
Read-Only Memory (ROM)
- Truth Table 자체를 메모리에 저장하여 구현하는 방식이다.
- 입력이 주소(Address)가 되고, 해당 주소에 저장된 값이 출력(Data)이 된다.
- N개의 입력이 있으면 개의 항목(Entry)이 필요하므로 입력 수가 늘어나면 크기가 기하급수적으로 증가한다.
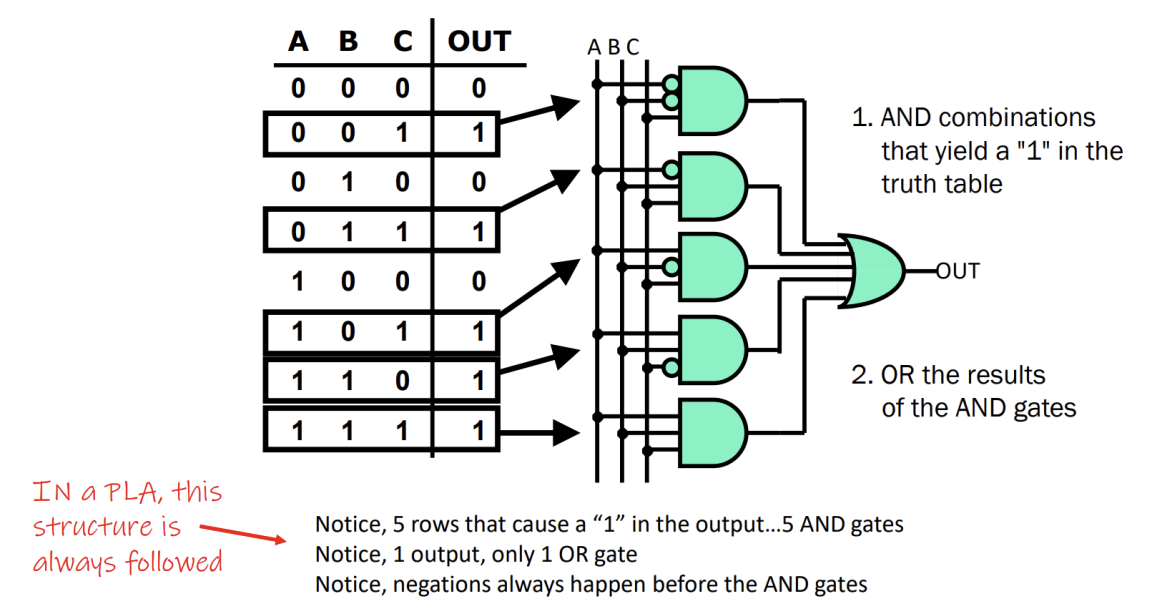
Karnaugh Map과 최적화
Boolean Equation을 간소화하기 위해 Karnaugh Map (K-Map)을 사용한다.
- Truth Table을 기하학적으로 배치하여, 인접한 항들이 하나의 변수만 다르도록 만든다.
- 인접한 1들을 묶음(Implicant)으로 만들어 논리식을 최소화한다.
- Prime Implicant: 다른 Implicant에 완전히 포함되지 않는 가장 큰 묶음이다.
Multiplexer와 Decoder
Multiplexer (Mux)
- 여러 데이터 입력 중 하나를 선택하여 출력으로 내보내는 회로이다.
- Select 신호에 따라 출력이 결정되며, 이를 이용해 모든 종류의 Combinational Logic을 구현할 수 있다(Universal).
Decoder
- k개의 입력 신호를 받아 개의 출력 중 하나를 활성화(High)한다.
- ROM 구조에서 주소 디코딩이나 Minterm 생성에 사용된다.
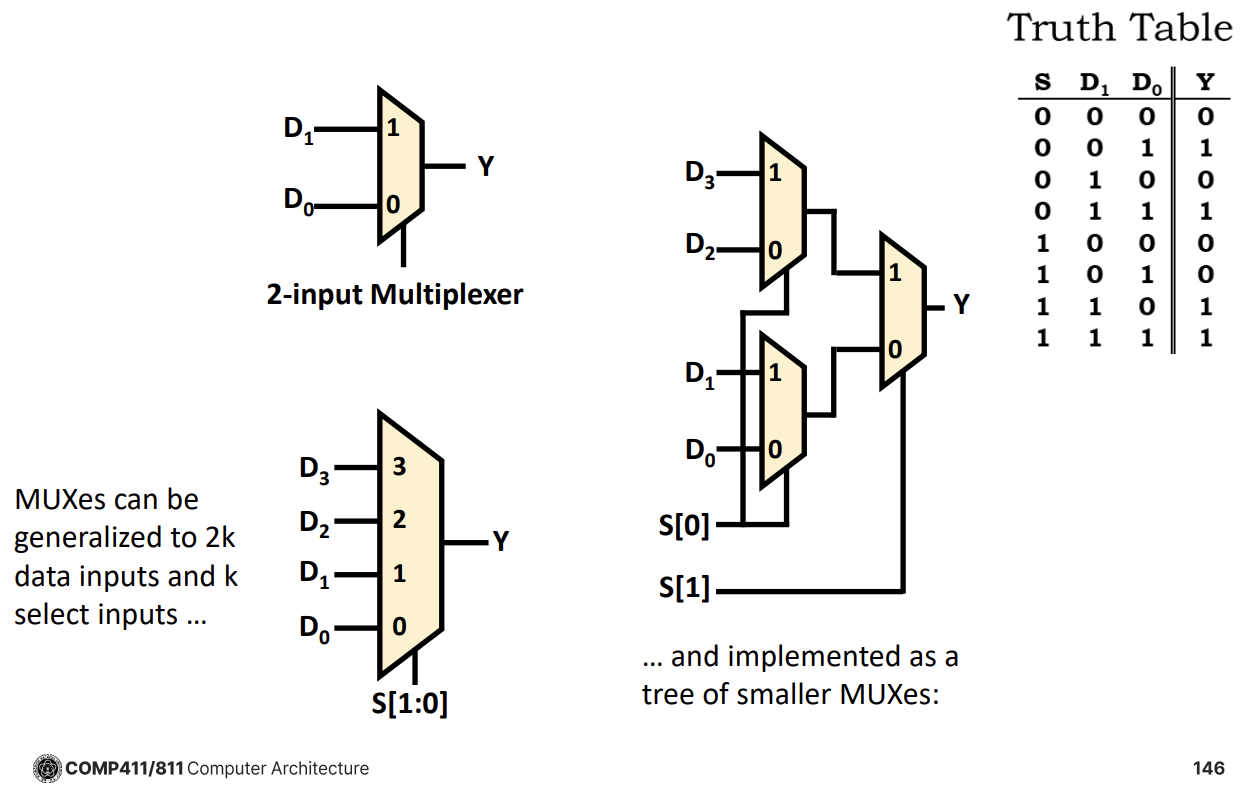
Combinational Elements와 Schematic 규칙
Combinational Logic을 구성하는 주요 빌딩 블록에는 AND-gate, Adder, Multiplexer (Mux), ALU, Decoder (Demux) 등이 있다. 회로도(Schematic)를 그릴 때는 다음과 같은 규칙을 따른다.
-
입력은 왼쪽이나 위쪽에, 출력은 오른쪽이나 아래쪽에 배치한다.
-
게이트의 신호 흐름은 왼쪽에서 오른쪽으로 진행한다.
-
와이어 연결 시 직선을 사용하는 것이 좋으며, T자 접합(T junction)은 항상 연결됨을 의미한다.
-
와이어가 교차할 때 점(Dot)이 있으면 연결된 것이고, 점이 없으면 연결되지 않은 것이다.
Multiplexer (Mux)
Multiplexer는 여러 개의 입력 중 하나를 선택하여 출력으로 내보내는 장치이다. 개의 입력을 제어하기 위해 개의 선택 비트(Selection bits)가 필요하다.
-
Enable 신호가 있는 Mux는 Enable이 비활성화되면 출력을 강제로 0으로 만든다.
-
4-to-1 Mux는 4개의 입력()과 2개의 선택 신호()를 가지며, 내부적으로 AND-OR 게이트 구조로 구현된다.
-
4비트 버스와 같이 여러 비트를 한 번에 스위칭해야 할 경우, Quadruple 2-to-1 Mux와 같은 형태로 병렬 구성하여 사용한다.
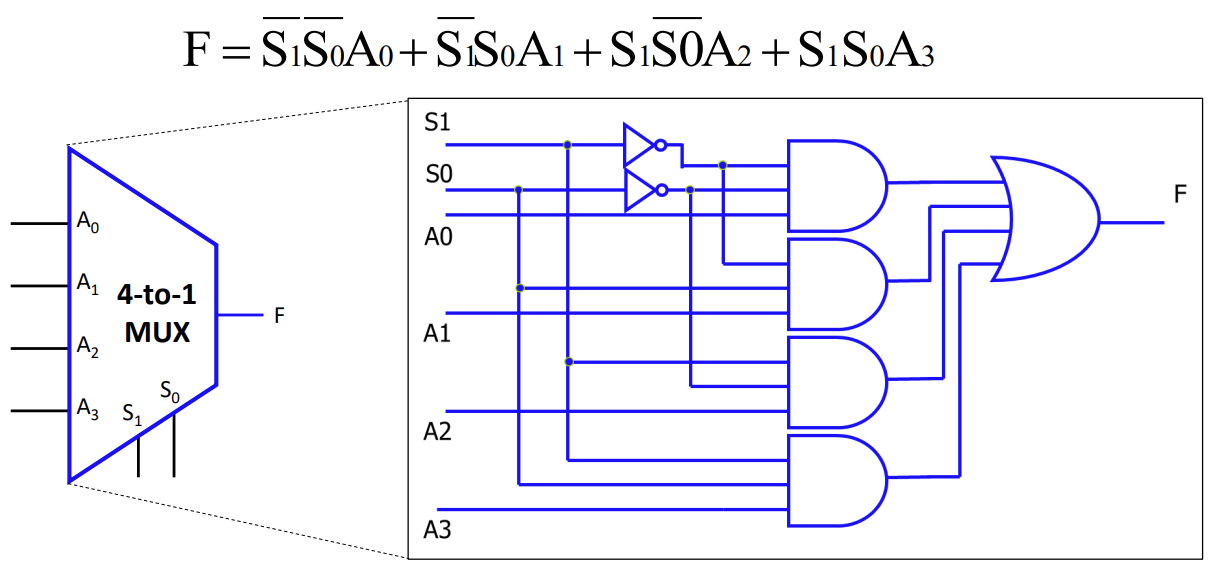
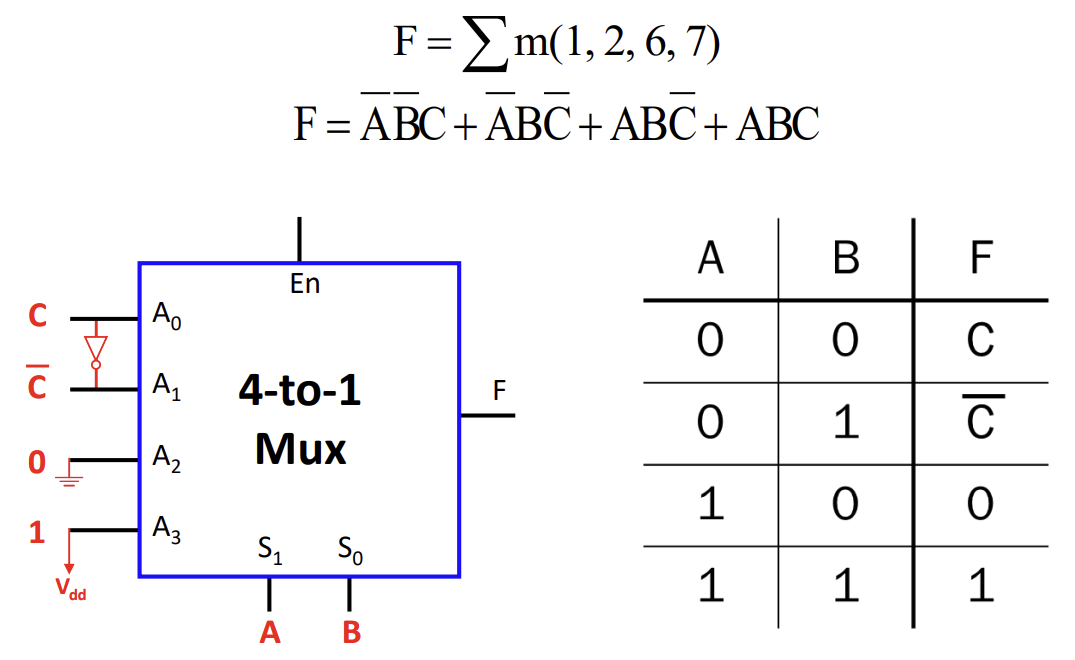
Multiplexer는 단순히 신호를 선택하는 것을 넘어, Boolean Function을 구현하는 데도 사용된다. 이를 통해 Truth Table을 하드웨어로 직접 변환할 수 있다.
-
개의 변수를 가진 함수는 -to-1 Mux를 사용하여 구현할 수 있다.
-
입력 변수 중 일부를 Mux의 데이터 입력으로 활용하면 Mux의 크기를 줄일 수 있다(예: 3변수 함수를 4-to-1 Mux로 구현).
Demultiplexer (DeMux)와 Decoder
Demultiplexer (DeMux)는 Mux의 반대 동작을 수행한다. 하나의 데이터 입력을 받아 선택 신호에 따라 여러 출력 중 하나로 보낸다.
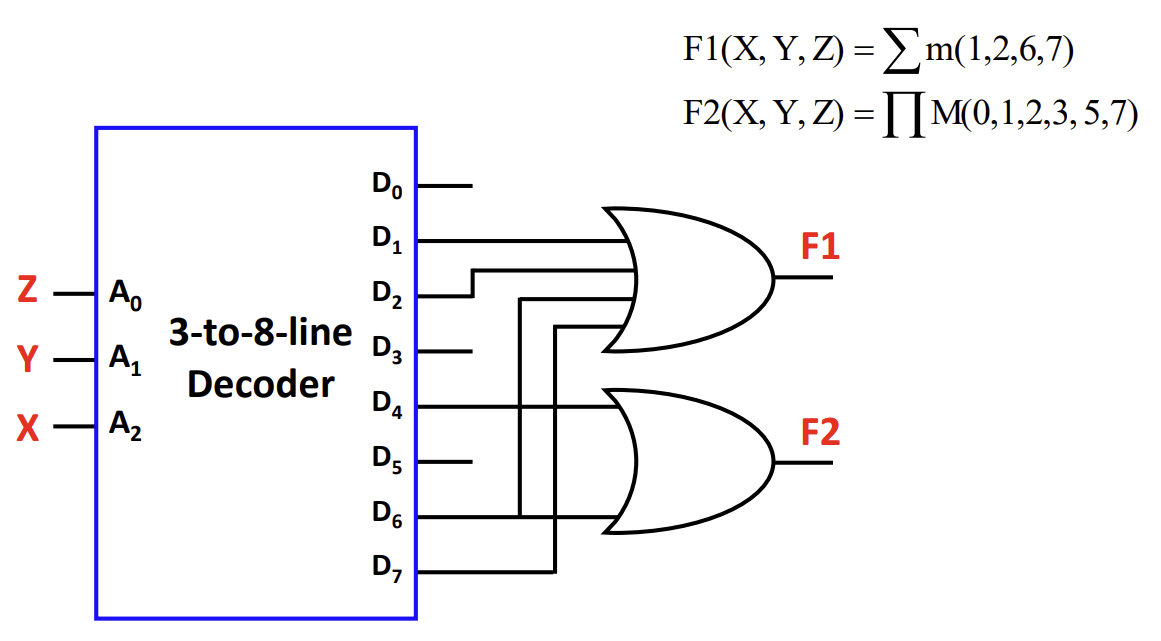
Decoder는 개의 입력 신호를 받아 개의 출력 중 하나를 활성화(High)하는 회로이다.
-
Minterm Generator라고도 하며, 입력 조합에 해당하는 특정 출력만 1이 된다.
-
Decoder의 출력들을 OR 게이트로 묶으면 임의의 Boolean Logic을 구현할 수 있다.
-
BCD-to-7-Segment Decoder는 4비트 BCD 입력을 받아 7-Segment 디스플레이를 제어하는 신호를 생성한다. 각 세그먼트(a~g)에 대한 논리는 Karnaugh Map을 통해 최적화하여 설계한다.
Encoder
Encoder는 Decoder의 반대 기능을 수행한다. 개의 입력 중 활성화된 입력의 인덱스를 비트 이진 코드로 변환하여 출력한다.
- Priority Encoder는 여러 입력이 동시에 활성화되었을 때, 가장 높은 우선순위(예: 가장 높은 숫자)를 가진 입력의 코드를 출력하도록 설계된 Encoder이다.
![PDF p.184: 8-to-3-line Encoder example mapping inputs to binary outputs]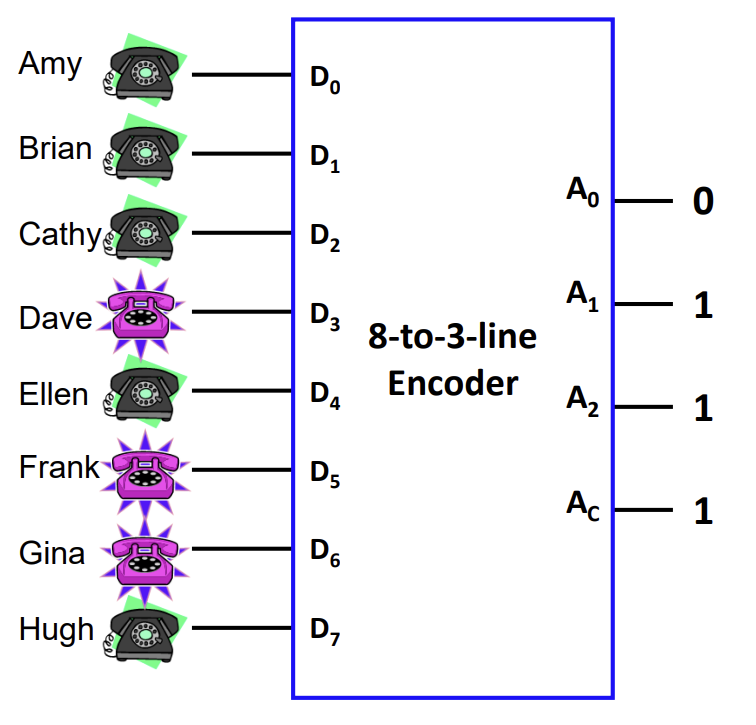
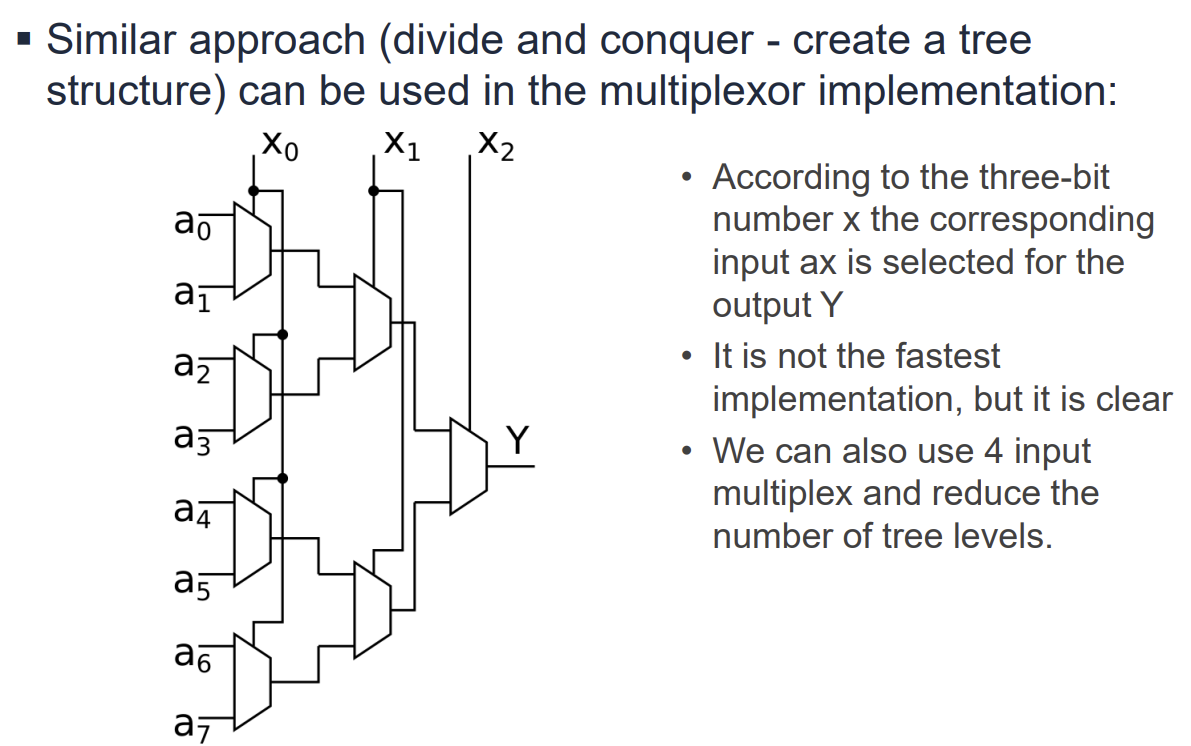
Mux Tree 구조
대규모의 Multiplexer는 작은 Mux들을 트리(Tree) 구조로 연결하여 구현할 수 있다. 예를 들어, 8-to-1 Mux는 두 개의 4-to-1 Mux와 하나의 2-to-1 Mux를 사용하여 구성할 수 있다. 이는 Divide and Conquer 접근 방식을 따른다.
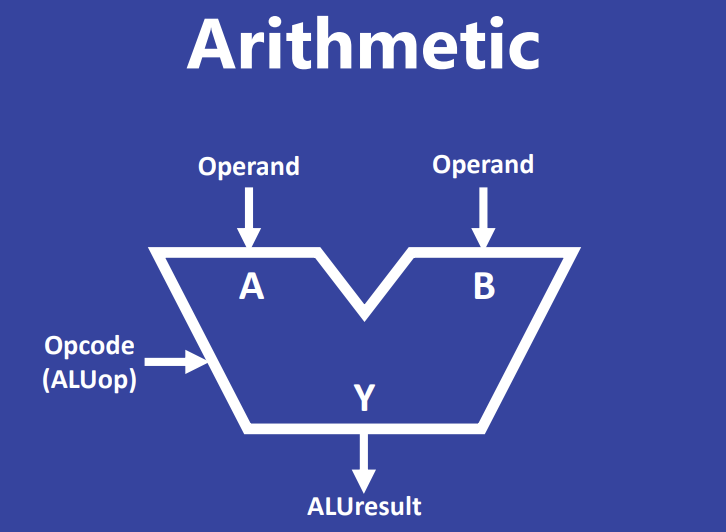
Arithmetic Logic Unit (ALU) 개요
ALU는 프로세서 내에서 산술 및 논리 연산을 수행하는 핵심 장치이다. 두 개의 피연산자(Operand A, B)와 수행할 연산을 지정하는 Opcode(ALUop)를 입력으로 받아, 연산 결과(Result)와 상태 플래그(예: Zero flag)를 출력한다.
하드웨어 설계의 주요 원칙들이 ALU에 반영되어 있다.
- Parallelism(병렬성): 유효한 입력이 주어지면 ALU 내의 모든 논리 게이트(ADD, AND, OR 등)는 병렬적으로 동시에 작동한다.
- Redundancy(중복성): 범용성을 위해 여러 연산을 동시에 수행하지만, 선택되지 않은 연산의 결과는 버려지므로 일부 자원이 낭비된다.
- Control Cost(제어 비용): 결과를 선택하기 위한 Multiplexer 등의 제어 회로가 추가적인 면적을 차지한다.
정수 표현 (Integer Representation)
컴퓨터는 전압 레벨을 이용해 비트(Bit)를 표현하고, 이를 조합하여 바이트(Byte) 단위로 데이터를 처리한다. C 언어 표준에서는 다음과 같은 정수형을 정의하지만, 정확한 크기는 플랫폼마다 다를 수 있다.
- char (1 byte), short (2 byte), long (4 byte), long long (8 byte).
- 상수는 10진수 외에도 16진수(0x), 8진수(0), 2진수(0b) 등으로 표현할 수 있다.
하드웨어에서 정수는 무한한 길이가 아닌 고정된 너비(Fixed Width, N bits)를 가진다.
- 표현 가능한 범위: 0 에서 까지 (Unsigned의 경우).
- 범위를 벗어나는 큰 수는 소프트웨어적으로 처리해야 한다.
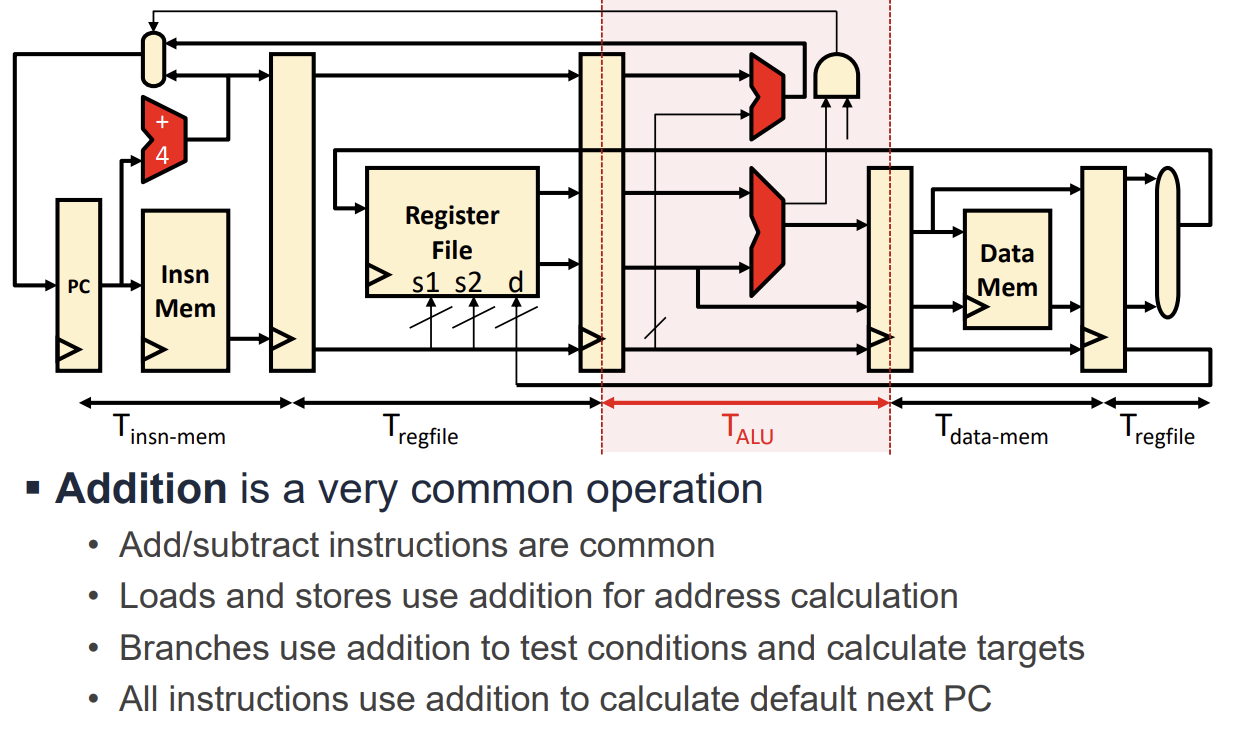
덧셈(Addition)의 중요성
덧셈은 프로세서에서 가장 빈번하게 발생하는 연산이다. 단순히 ADD 명령어뿐만 아니라 다양한 곳에 사용되기 때문에 덧셈기의 성능()은 전체 프로세서의 성능에 큰 영향을 미친다.
- Load/Store: 메모리 주소 계산에 사용된다.
- Branch: 분기 조건 테스트 및 타겟 주소 계산에 사용된다.
- PC Update: 다음 명령어 주소를 계산(PC + 4)하는 데 사용된다.
음수 표현과 2의 보수 (Two's Complement)
음수를 표현하는 방식에는 크게 두 가지가 있다.
Sign/Magnitude (부호/크기)
- 최상위 비트(MSB)를 부호 비트로 사용하고 나머지를 크기로 사용한다.
- +0과 -0 두 개의 0이 존재하며, 덧셈 회로 설계가 복잡하다는 단점이 있다.
Two's Complement (2의 보수)
- 현대 컴퓨터의 표준 방식이다.
- MSB가 0이면 양수, 1이면 음수를 의미한다.
- 0에 대한 표현이 하나뿐이며(Unique Zero), 덧셈 연산을 별도의 감산기 없이 수행할 수 있어 효율적이다.
- MSB는 의 가중치(Weight)를 가진다. 예를 들어 4비트 이진수
1010은 을 의미한다. - 어떤 수의 음수를 구하려면 비트를 반전(Invert)시킨 후 1을 더하면 된다().
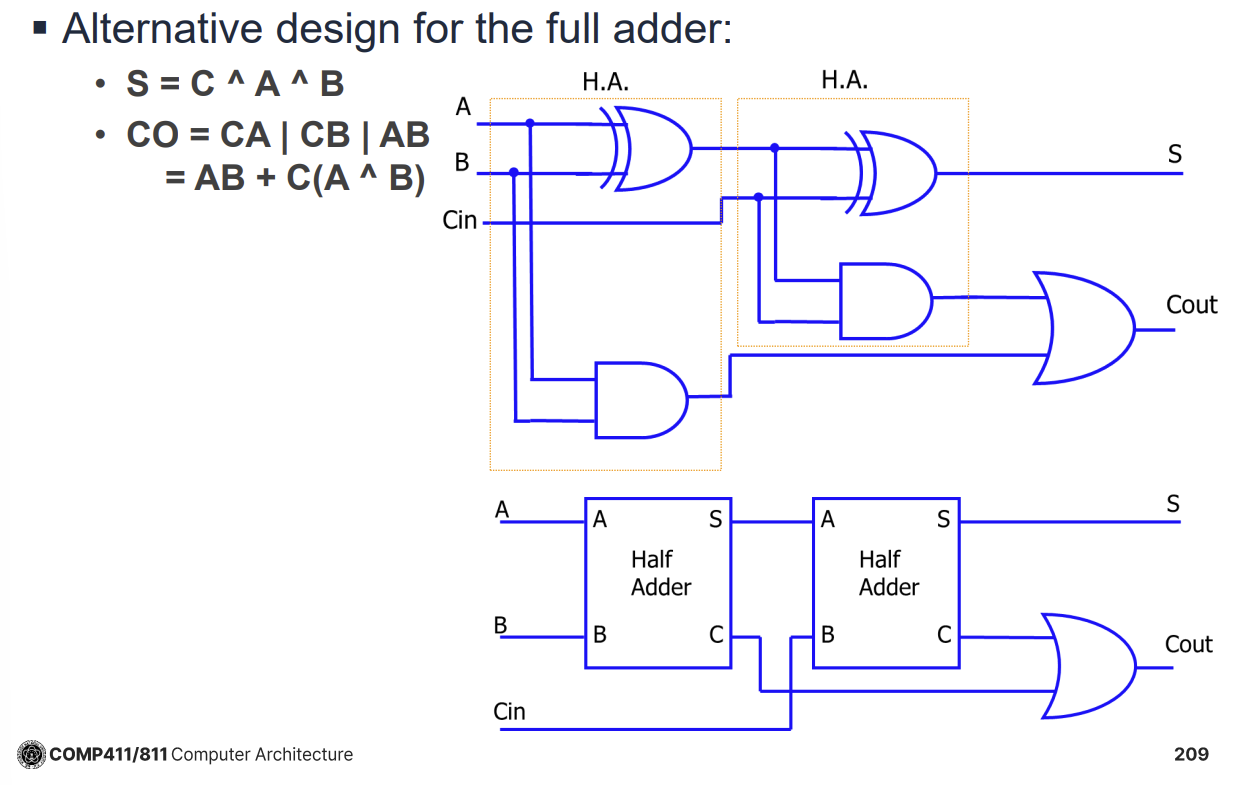
Binary Addition과 Adder 회로
이진수 덧셈은 십진수 덧셈과 유사하게 하위 비트부터 더하고 자리올림(Carry)을 다음 비트로 넘기는 방식으로 수행한다. 이를 하드웨어로 구현하기 위해 Half Adder와 Full Adder를 사용한다.
- Half Adder: 두 개의 입력 비트(A, B)를 더해 Sum(S)과 Carry Out(CO)을 출력한다. Carry In을 처리하지 못한다.
- Full Adder: 두 개의 입력 비트(A, B)와 하위 단계에서 올라온 Carry In(CI)을 더해 Sum과 Carry Out을 출력한다. 두 개의 Half Adder와 하나의 OR 게이트로 구성할 수 있다.
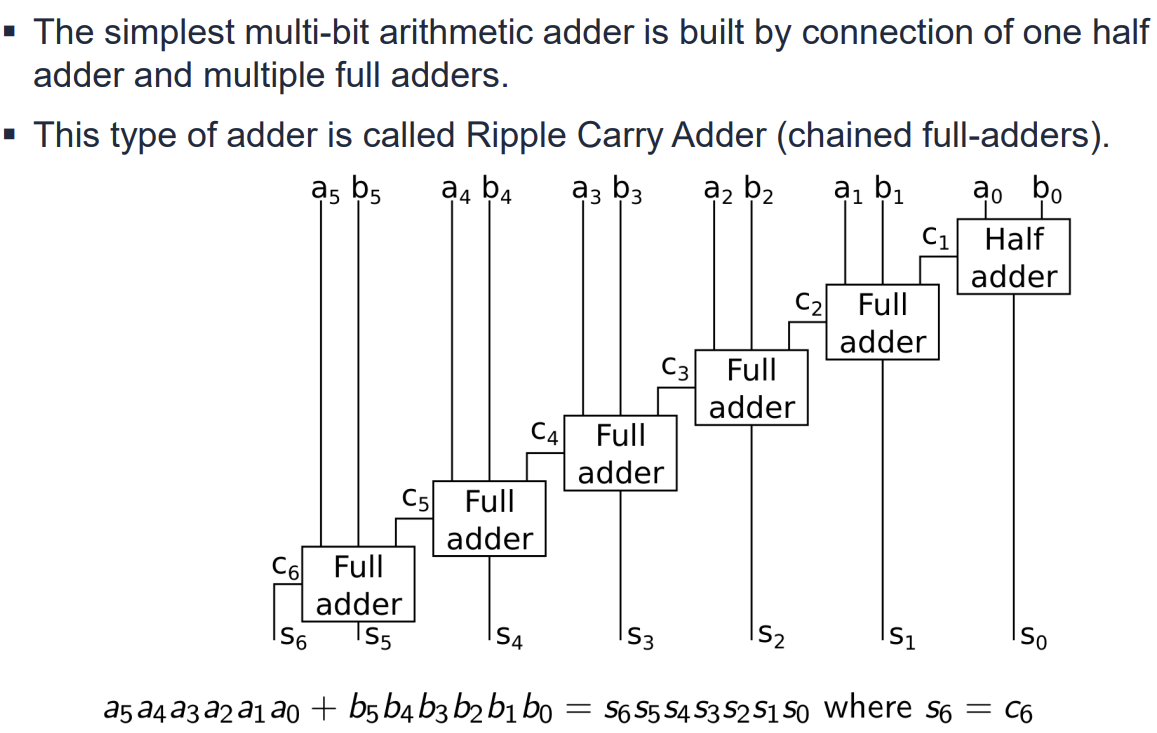
Ripple Carry Adder (RCA)
N비트 덧셈을 수행하기 위해 N개의 Full Adder를 직렬로 연결한 구조이다. 각 Full Adder의 Carry Out이 다음 Full Adder의 Carry In으로 연결된다.
- 구조가 단순하지만, 하위 비트의 Carry가 최상위 비트까지 순차적으로 전달되어야 하므로 지연 시간(Delay)이 비트 수 N에 비례하여 선형적으로 증가한다.
- 64비트와 같은 큰 수의 덧셈에서는 이 지연 시간이 성능의 병목이 된다.
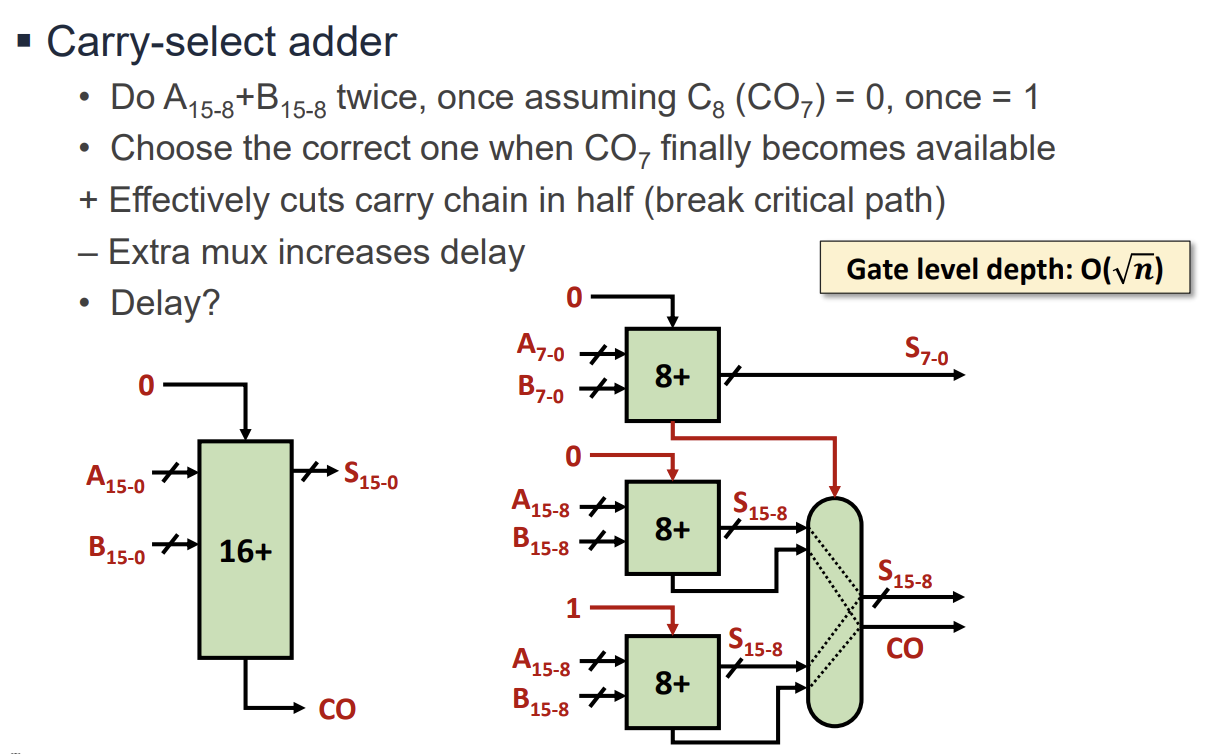
Fast Addition 기법 1: Carry Select Adder
Ripple Carry Adder의 속도 문제를 해결하기 위해 하드웨어 자원을 더 사용하여 속도를 높이는 방식이다.
- 상위 비트 블록의 덧셈을 하위 블록의 Carry Out이 도착하기 전에 미리 수행한다. 이때 Carry In이 0인 경우와 1인 경우 두 가지를 모두 계산한다.
- 하위 블록의 Carry 결과가 도착하면, Multiplexer(Mux)를 사용하여 미리 계산된 두 결과 중 올바른 것을 선택한다.
- 지연 시간은 수준으로 개선된다.
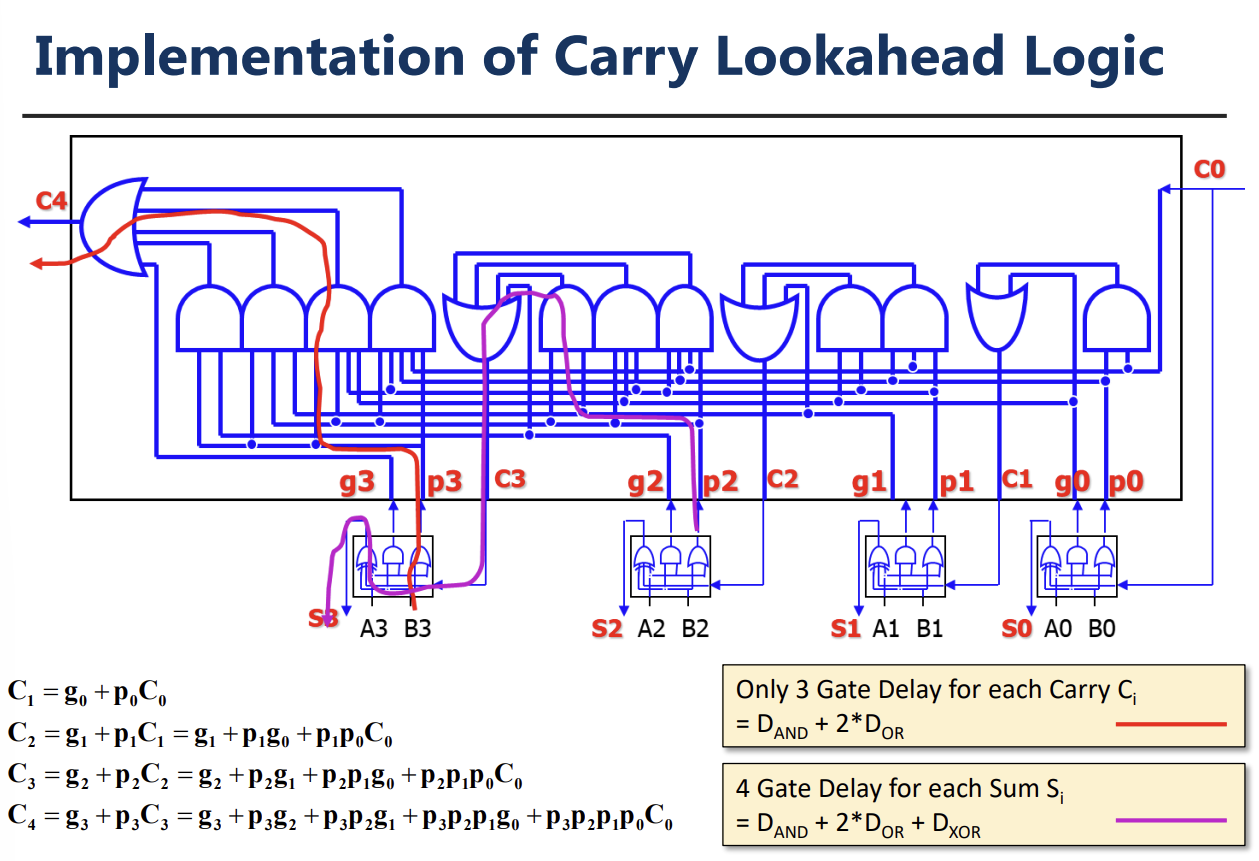
Fast Addition 기법 2: Carry Lookahead Adder (CLA)
Carry가 전파되기를 기다리지 않고, 입력값(A, B)만으로 Carry를 미리 예측하여 계산하는 방식이다. 이를 위해 Generate(G)와 Propagate(P) 신호를 정의한다.
- Generate (): 입력 A, B가 모두 1이면 무조건 Carry가 생성된다.
- Propagate (): 입력 중 하나라도 1이면 하위에서 올라온 Carry를 상위로 전달한다.
- Carry 식:
- 이 방식을 사용하면 모든 Carry를 병렬적으로 계산할 수 있어 지연 시간이 으로 줄어든다. 비트 수가 많아지면 여러 단계(Level)의 계층적 구조로 구현한다.
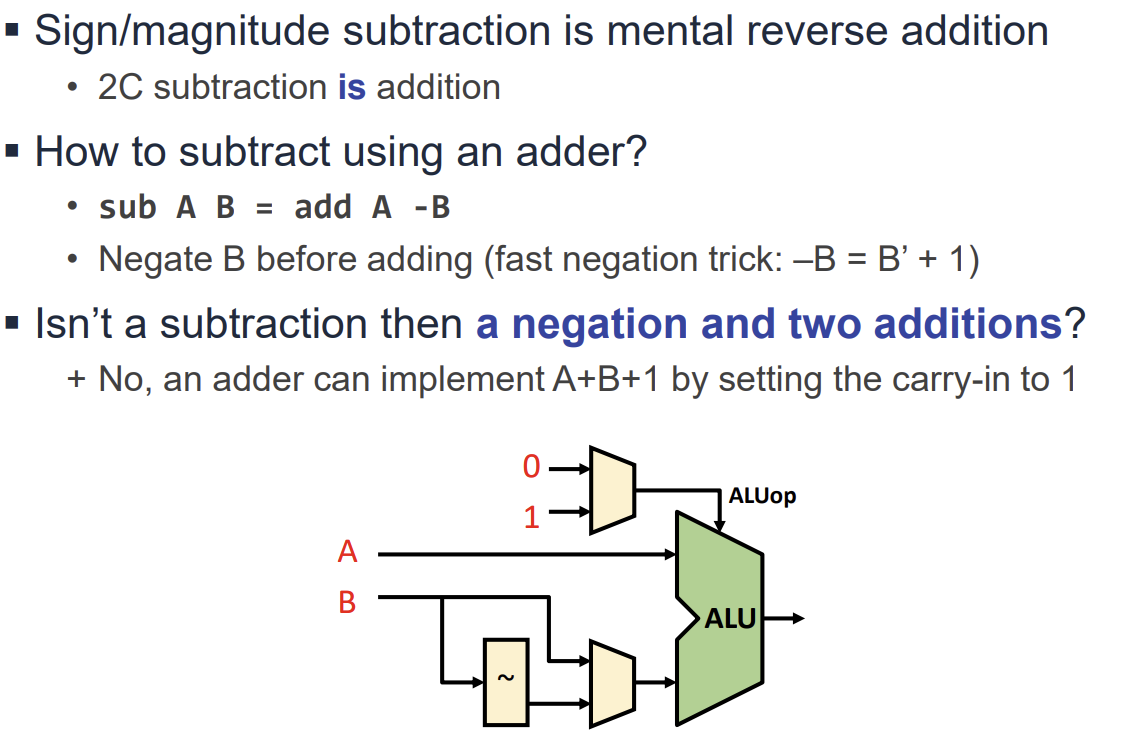
Subtraction과 Overflow
뺄셈(A - B)은 2의 보수(2's Complement)를 이용하여 덧셈(A + (-B))으로 처리한다.
- 하드웨어적으로는 B를 반전(Invert)시키고, Adder의 첫 번째 Carry In을 1로 설정하여 구현한다.
Overflow는 연산 결과가 표현 가능한 범위를 벗어나는 현상이다.
- Unsigned 정수: 최상위 비트(MSB)에서 Carry Out이 발생하면 Overflow이다.
- Signed 정수: 양수+양수=음수 또는 음수+음수=양수 결과가 나올 때 발생한다. 양수+음수 연산에서는 발생하지 않는다.
- 하드웨어적으로는 마지막 두 Carry 비트(과 )의 XOR 연산으로 감지한다.
Shift 및 Rotate 연산
Shift와 Rotate 연산은 비트 단위 조작이나 빠른 곱셈/나눗셈에 사용된다.
-
Logical Shift: 빈 자리를 0으로 채운다. Unsigned 정수의 연산에 적합하다.
-
Arithmetic Shift: 부호를 유지하기 위해 MSB(Most Significant Bit)를 복제하여 채운다(Right Shift 시). Signed 정수의 연산에 적합하다.
-
Rotate: 밀려 나가는 비트를 반대편 빈자리로 다시 채워 넣는다.
Barrel Shifter
Barrel Shifter는 한 번의 연산으로 임의의 비트 수만큼 데이터를 이동시킬 수 있는 회로이다.
-
번의 Shift 연산을 순차적으로 수행하는 대신, 단계의 Multiplexer를 사용하여 지연 시간을 줄인다.
-
예를 들어 16비트 Barrel Shifter는 1, 2, 4, 8비트 이동을 담당하는 4개의 단계로 구성된다.
-
Funnel Shifter: 더 넓은 입력 소스(예: 2N-1 비트)에서 N비트 윈도우를 선택하는 방식으로 Shift를 구현한다.

Shifter 구현 방식
간단한 Shifter는 Mux를 사용하여 구현할 수 있다.
-
1비트 Shift: 입력과 0을 선택하는 2-to-1 Mux로 구현한다.
-
4비트 Logical Shifter: 4-to-1 Mux를 사용하여 0, 1, 2, 3비트 Shift를 선택적으로 수행할 수 있다.
-
Arithmetic Shifter: Overflow/Underflow 감지 로직과 부호 비트 처리를 추가하여 구현한다.
![PDF p.273: 4-bit Logical Shifter using 4-to-1 Muxes]
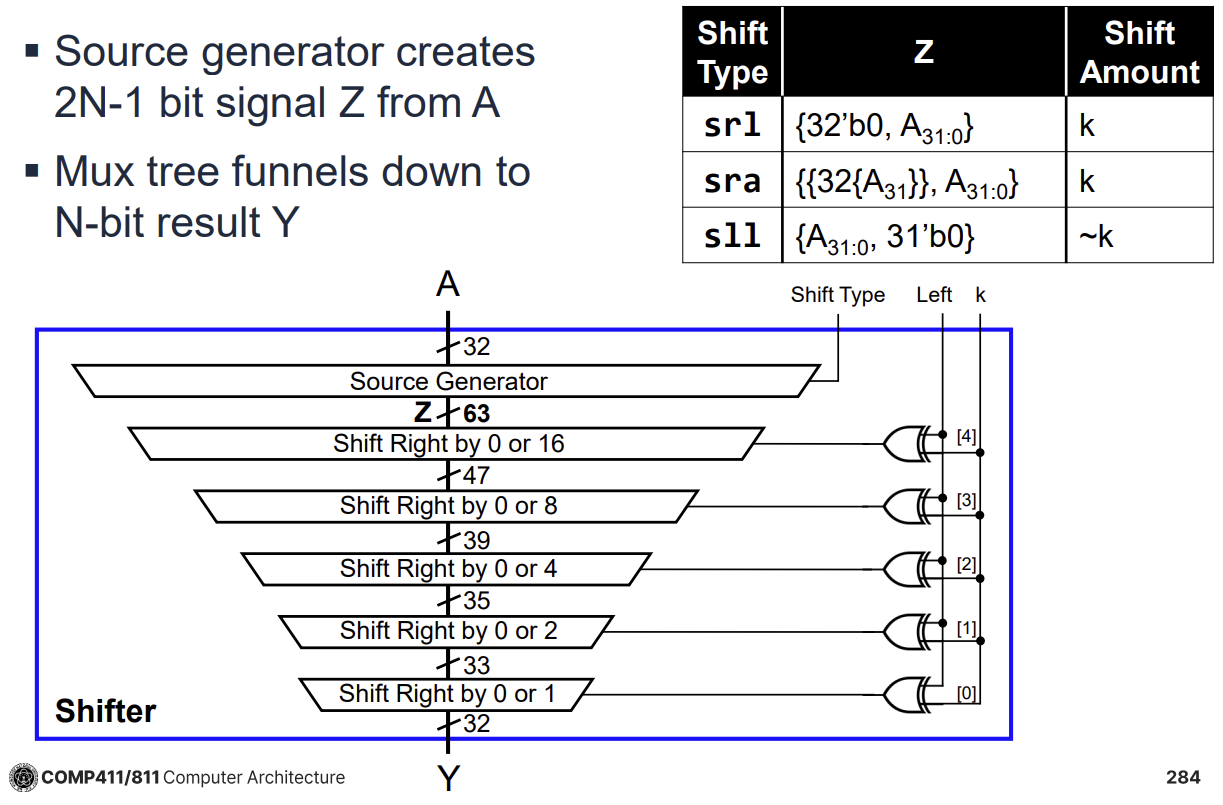
Funnel Shifter의 구조
Funnel Shifter는 Source Generator를 통해 입력 데이터를 확장하고, Mux Tree를 통해 원하는 비트 위치를 선택한다.
-
Source Generator: 입력 데이터 A에 대해 Shift 종류(Logical, Arithmetic, Rotate)에 따라 0이나 부호 비트 등을 패딩하여 2N-1 비트의 중간 신호 Z를 생성한다.
-
Logarithmic Shifter: 여러 단계의 2-input Mux를 거치며 최종 Shift 결과를 만들어낸다.
-
Wider Mux 사용: 4:1이나 8:1 Mux를 사용하여 단계 수를 줄이고 지연 시간과 전력 소모를 감소시킬 수 있다.
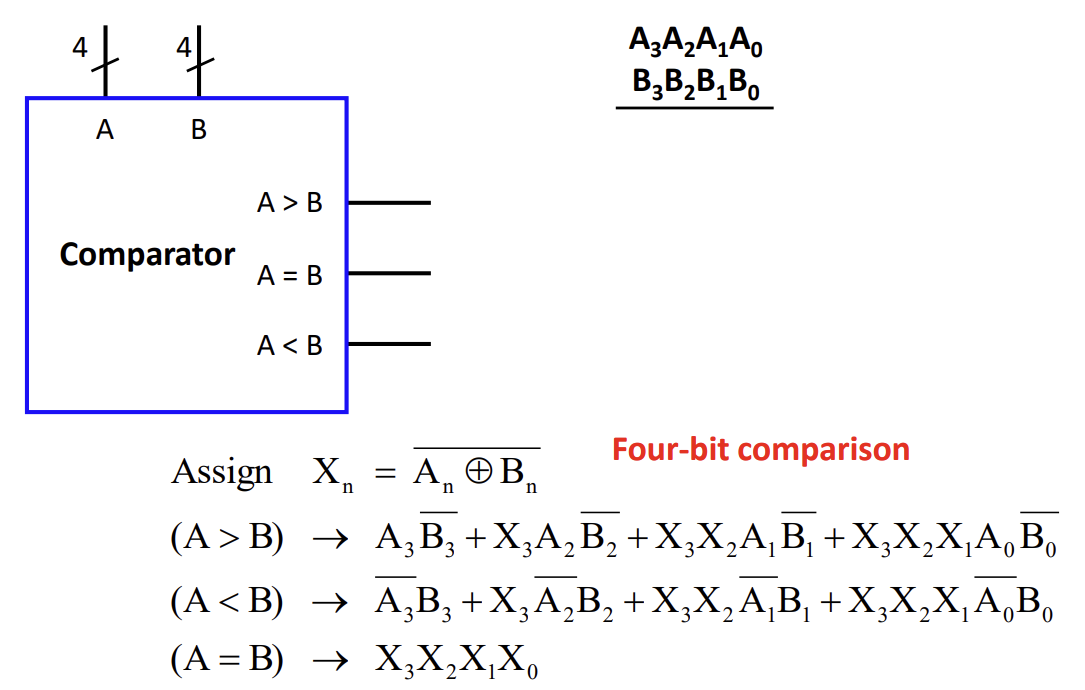
Comparator (비교기)
Comparator는 두 이진수 A와 B를 비교하여 크기 관계(, , )를 출력하는 조합 논리 회로이다.
1-bit Comparator
- : (A는 1이고 B는 0인 경우)
- : (A는 0이고 B는 1인 경우)
- : 의 부정 (XNOR, 두 비트가 같을 때 1)
Multi-bit Comparator (예: 4-bit)
- 상위 비트부터 차례대로 비교한다.
- 와 가 다르면 그 결과가 전체 대소 관계를 결정한다.
- 와 가 같으면, 다음 비트()를 비교하는 식으로 진행한다.
- Cascading Comparator: 하위 비트의 비교 결과를 상위 비트 비교기의 입력으로 사용하여 확장성을 높인 구조이다.
Multiplication (곱셈기)
곱셈은 부분 곱(Partial Product)을 생성하고 이를 더하는 과정으로 이루어진다. 이진수 곱셈은 0 또는 1과의 곱셈이므로 십진수보다 단순하다(Multiplicand를 그대로 더하거나 0을 더함).
Sequential Multiplier (순차 곱셈기)
- 32비트 덧셈기와 시프트 레지스터를 사용하여 구현한다.
- Multiplier의 LSB가 1이면 Multiplicand를 Product에 더하고, Multiplicand를 왼쪽으로 시프트, Multiplier를 오른쪽으로 시프트한다.
- 하드웨어 비용은 적지만, -bit 곱셈에 사이클이 소요되어 속도가 느리다.
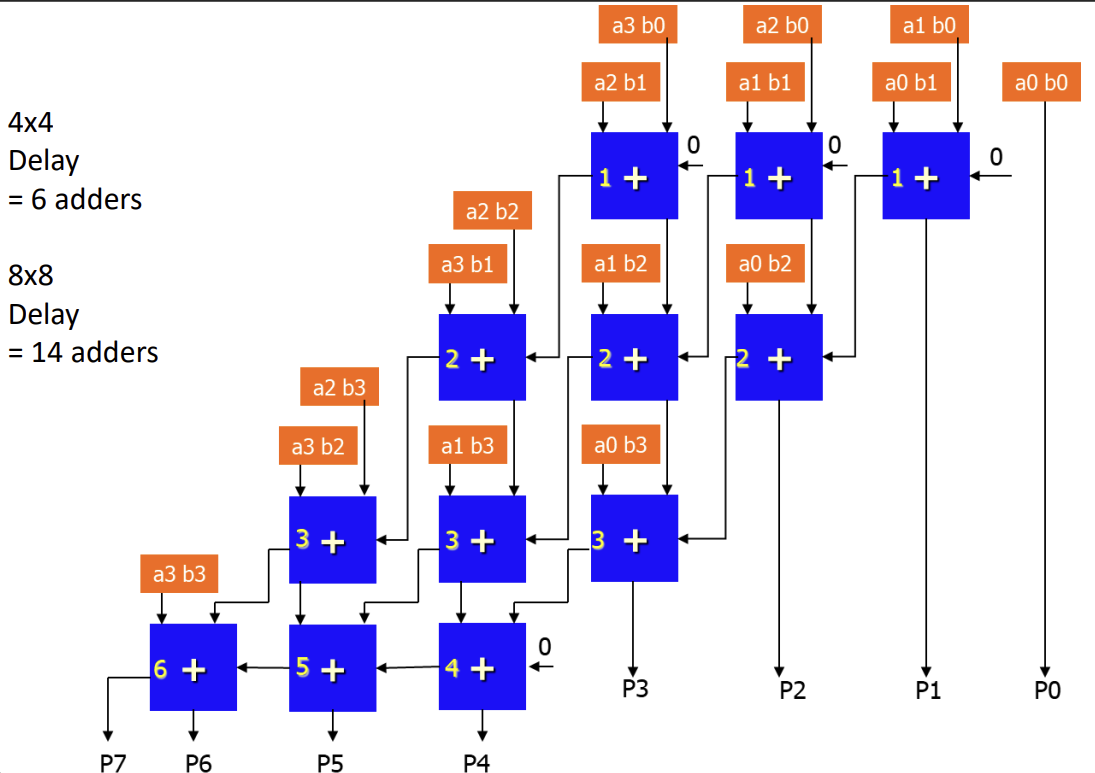
Array Multiplier (배열 곱셈기)
- 모든 부분 곱을 동시에 생성하고, 이를 덧셈기 배열(Array of Adders)을 통해 병렬로 더한다.
- 속도가 빠르지만 하드웨어 면적을 많이 차지한다.
- 곱셈에서 지연 시간은 대략 (Carry Ripple Adder 사용 시) 정도이다.
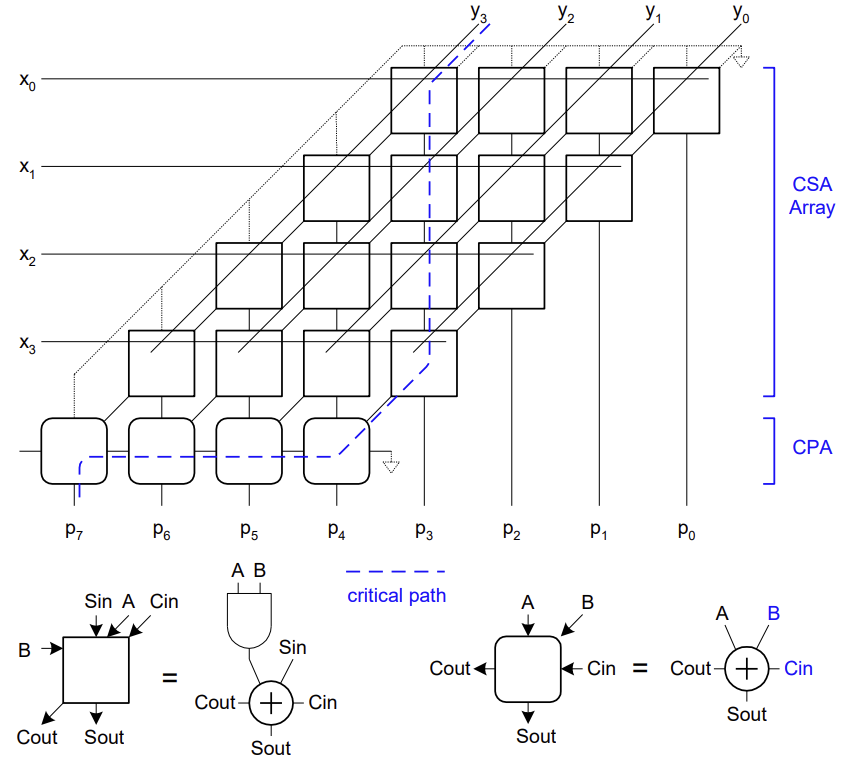
Carry Save Adder (CSA)
세 개 이상의 수를 더할 때 사용하는 효율적인 덧셈 방식이다.
- 일반적인 덧셈은 2개의 수를 더해 1개의 결과를 만들지만, CSA는 3개의 수()를 입력받아 Sum()과 Carry() 2개의 결과를 출력한다.
- Carry를 옆으로 전파(Propagate)하지 않고 그대로 저장(Save)하여 다음 단계로 넘긴다. 따라서 Carry 전파 지연이 발생하지 않는다.
- 개의 수를 더할 때 CSA 트리를 구성하여 의 지연 시간으로 합을 구할 수 있다(예: Wallace Tree).
- 마지막 단계에서는 2개의 수(Sum 벡터와 Carry 벡터)가 남게 되며, 이를 최종적으로 일반적인 Adder(예: CLA)로 더하여 결과를 얻는다.
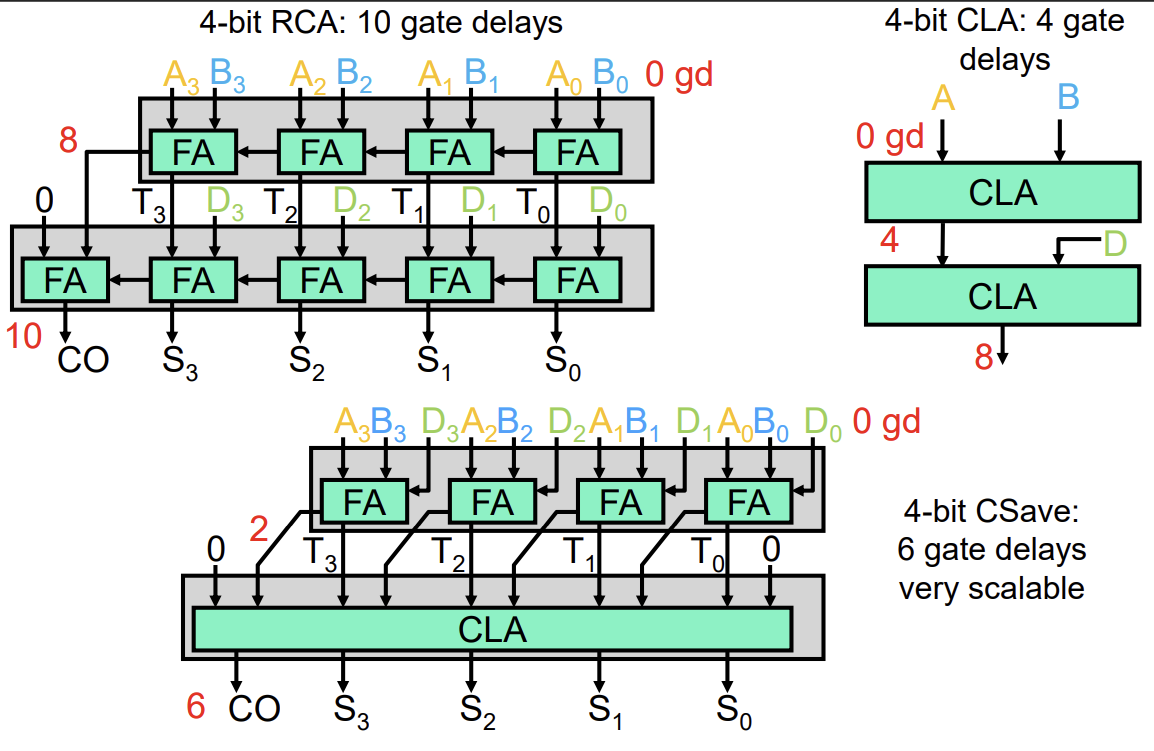
Propagation Delay 비교
- Ripple Carry Multiplier: 개의 Ripple Carry Adder를 사용하므로 지연 시간이 길다.
- Carry Save Multiplier: CSA를 사용하여 부분 곱을 압축하므로 지연 시간이 획기적으로 줄어든다. 곱셈에서 Ripple 방식은 8 Adder Delay인 반면, CSA 방식은 6 Adder Delay이다.
Signed Arithmetic
Unsigned Arithmetic과 달리 Signed Arithmetic에서는 연산의 종류에 따라 처리 방식이 달라진다.
-
덧셈과 뺄셈: Signed와 Unsigned 연산에 동일한 회로를 사용한다. 비트 패턴에 대한 해석만 다를 뿐이다.
-
곱셈과 나눗셈: 부호에 따라 결과가 달라지므로 다른 처리 방식이 필요하다.
Signed Multiplication and Division
Signed Multiplication
-
2비트 예시: 3×3=9 (Unsigned), −1×−1=1 (Signed), 3×−1=−3 (Mixed).
-
k비트 수 두 개를 곱하면 최대 2k 비트의 결과가 필요하며, 하위 k비트는 부호와 관계없이 동일하다.
-
RISC-V 명령어:
mul(하위 32비트),mulh(상위 32비트, Signed × Signed),mulhsu(상위 32비트, Signed × Unsigned),mulhu(상위 32비트, Unsigned × Unsigned).

Division
-
Unsigned Division: 0으로 나누는 경우 몫은 모든 비트가 1이 된다.
-
Signed Division: 나눗셈 결과는 항상 0 방향으로 내림(floor)한다. 부호가 다른 두 수의 나눗셈 결과는 음수가 되어야 한다.
Floating Point (FP) Numbers
부동소수점 수는 과학적 표기법(Scientific Notation)을 사용하여 실수와 매우 큰/작은 수를 표현한다.
-
구성 요소: Sign (부호), Significand/Fraction (가수), Exponent (지수).
-
IEEE 754 표준:
-
Single Precision (32-bit): 1-bit Sign, 8-bit Exponent, 23-bit Significand. 유효 숫자 약 7자리.
-
Double Precision (64-bit): 1-bit Sign, 11-bit Exponent, 52-bit Significand. 유효 숫자 약 15자리.
-
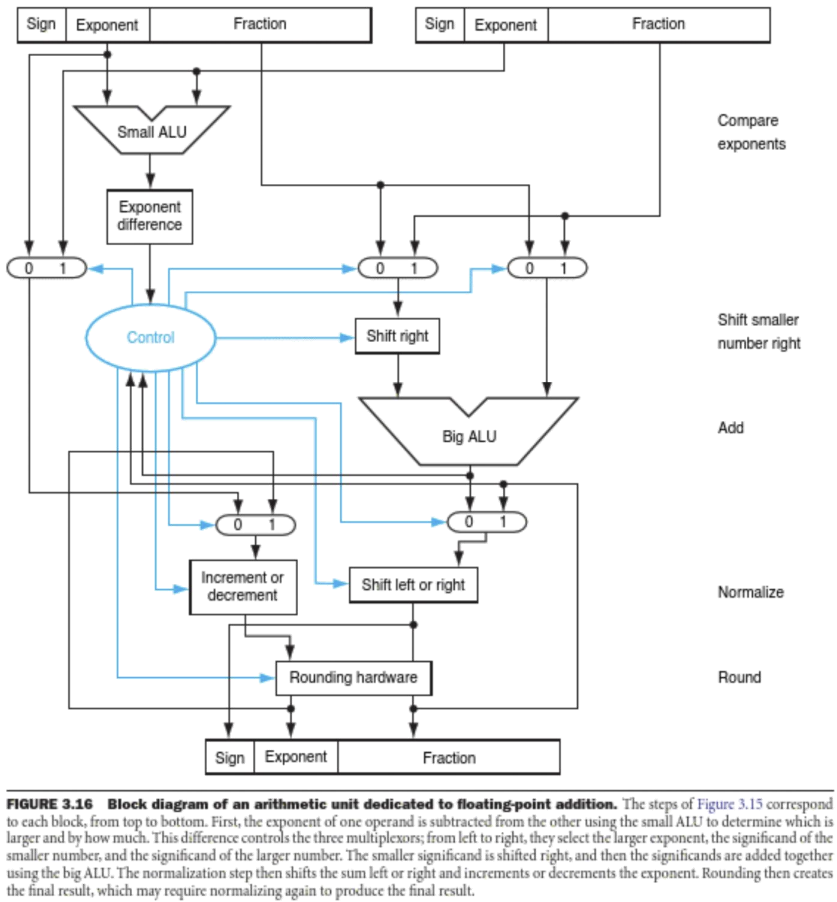
FP 연산의 특징과 주의점
-
부정확성(Inexact): FP 연산은 근사값을 사용하므로 결합법칙((A+B)+C=A+(B+C))이 성립하지 않는다.
-
크기 차이가 큰 두 수의 덧셈이나 비슷한 두 큰 수의 뺄셈에서 정밀도 손실이 발생할 수 있다.
-
프로그래밍 시 두 FP 수의 동등성(Equality)을 직접 비교하면 안 되며, 오차 범위 내 비교를 해야 한다.
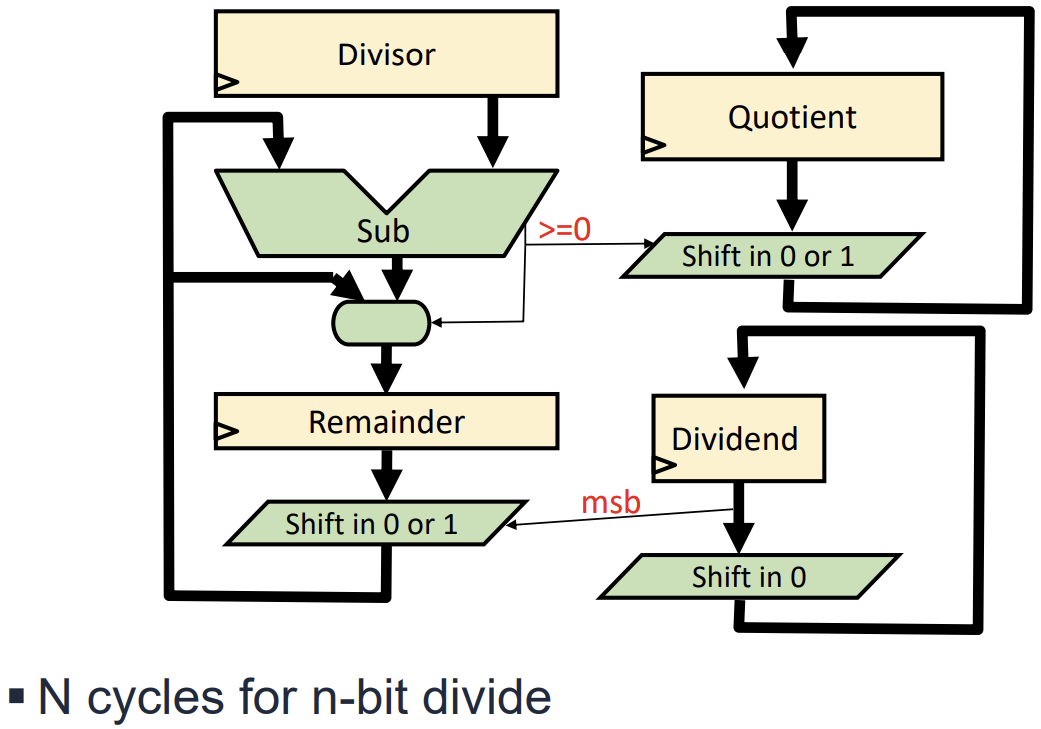
Division Algorithms and Hardware
십진수 나눗셈과 유사하게 이진수 나눗셈도 반복적인 뺄셈과 시프트 연산으로 수행된다.
-
Sequential Divider: 32비트 나눗셈을 위해 32 사이클이 소요된다. 피제수(Dividend)에서 제수(Divisor)를 뺄 수 있는지 확인하고, 뺄 수 있으면 몫(Quotient) 비트를 1로 설정하고 뺀다.
-
Hardware implementation: Adder/Subtractor, Shift Register, Control Logic으로 구성된다.
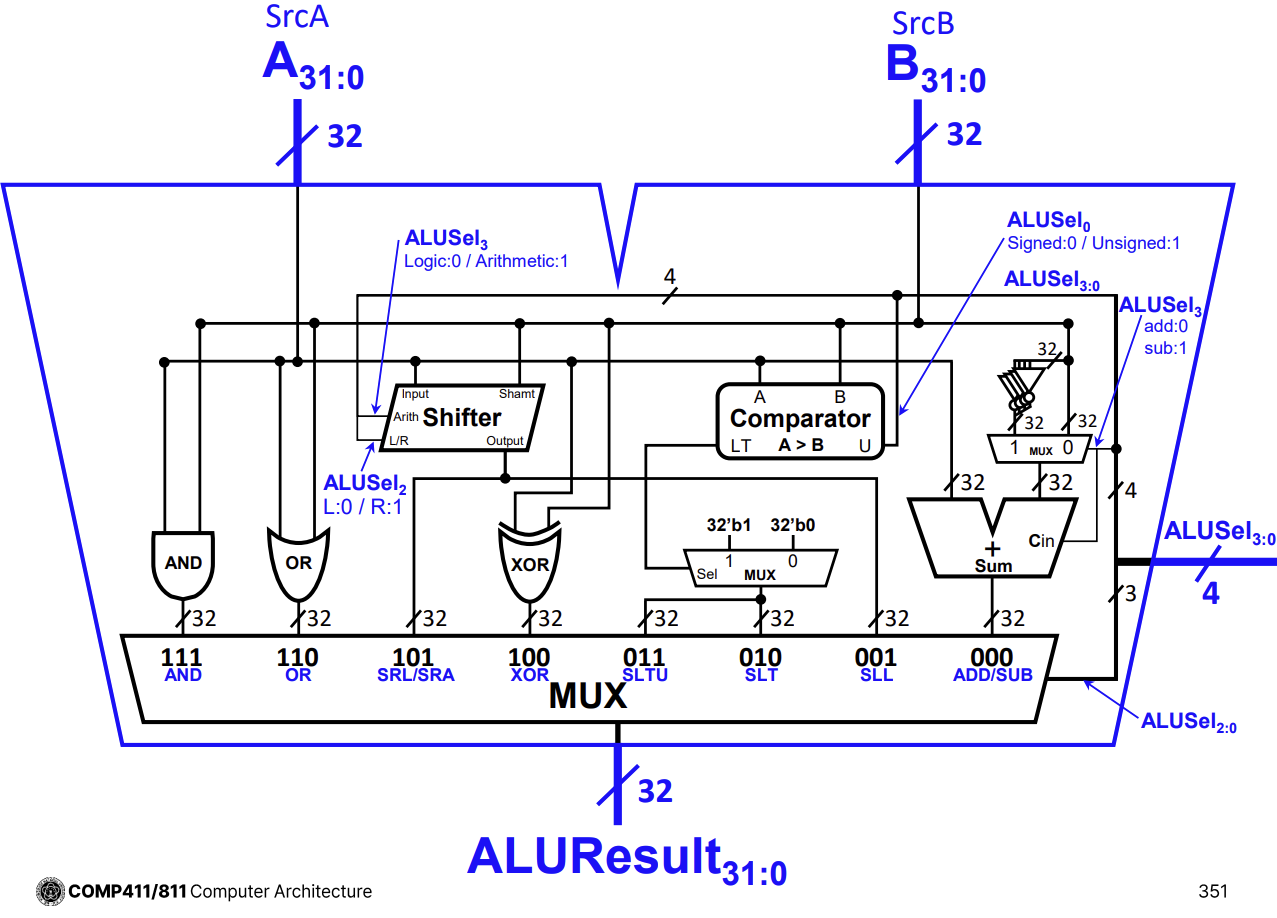
Comprehensive ALU Design
ALU는 덧셈, 뺄셈, 논리 연산(AND, OR, XOR), 시프트(SLL, SRL, SRA), 비교(SLT, SLTU) 등 다양한 기능을 통합한 회로이다.
-
입력 선택 신호(ALUSel)에 따라 내부의 Mux가 적절한 연산 결과를 선택하여 출력한다.
-
Adder는 덧셈, 뺄셈, 비교 연산에 공통적으로 사용된다.
-
Shifter와 Logic Unit은 별도의 경로로 구성되어 병렬로 동작한다.
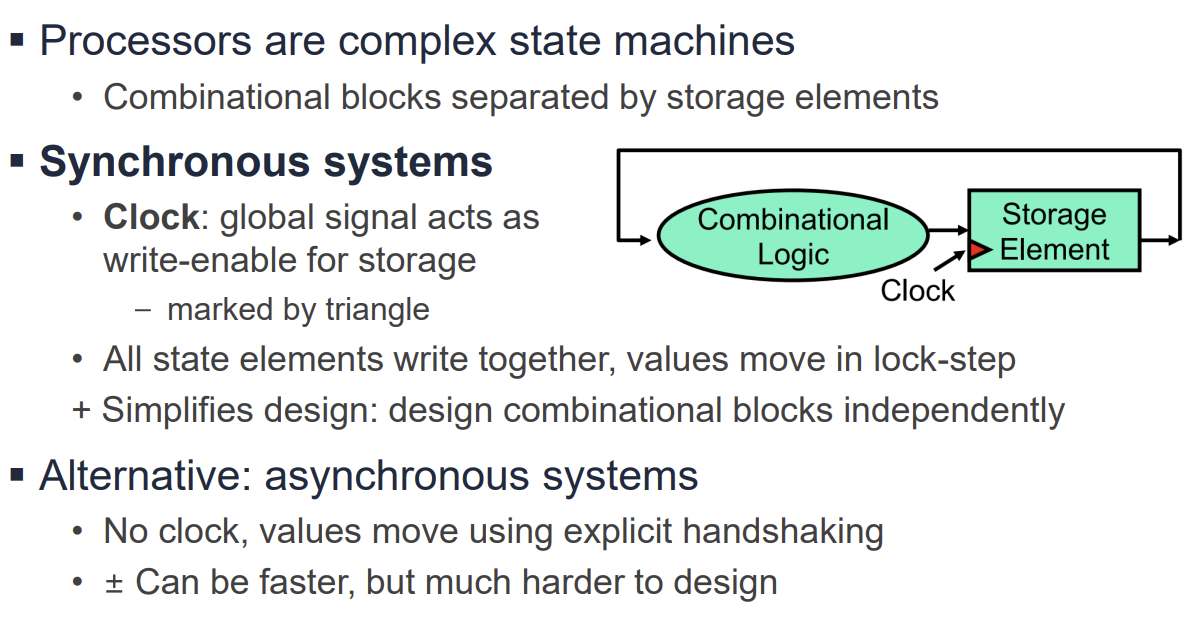
Sequential Logic Circuits
Sequential Logic은 출력이 현재의 입력뿐만 아니라 과거의 입력 이력(History)에도 의존하는 회로이다. 이는 회로 내부에 정보를 저장하는 메모리 요소(Storage Element)가 있음을 의미한다.
- Combinational Logic: 상태(State)가 없으며, 출력은 오직 현재 입력에 의해서만 결정된다(예: Adder, Mux).
- Sequential Logic: 상태를 가지며, 클럭(Clock) 신호에 맞춰 동작한다(예: Latch, Flip-Flop, Register, Memory).
동기식 시스템(Synchronous System)은 클럭이라는 전역 신호를 사용하여 모든 저장 요소의 업데이트 타이밍을 맞춘다. 클럭의 주기(Period)는 회로의 동작 속도를 결정하는 중요한 요소이다.
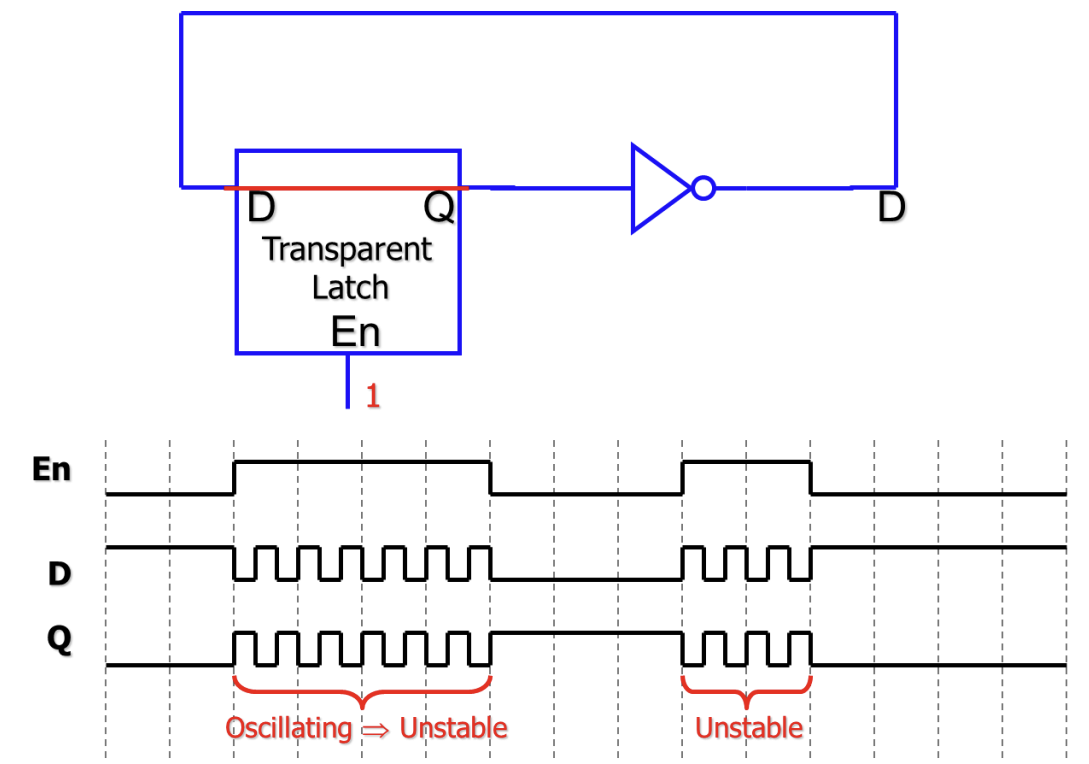
Latches와 Transparency
Latch는 가장 기본적인 저장 요소이다.
- S-R Latch: NOR 게이트 두 개를 교차 연결(Cross-coupled)하여 구현하며, Set(S)과 Reset(R) 입력을 가진다.
- D Latch: 데이터(D)와 인에이블(Enable/Clock) 입력을 가진다. Enable 신호가 1일 때 입력 D가 출력 Q로 그대로 전달되며, 이를 투명성(Transparency)이라고 한다. Enable이 0이면 값을 유지한다.
투명성(Transparency) 문제
- Latch가 열려 있는(Enable=1) 동안 입력이 변하면 출력이 즉시 변한다.
- 피드백 루프가 있는 회로에서 Latch를 사용하면, 한 클럭 주기 내에 신호가 여러 번 순환하는 레이스 컨디션(Race Condition)이나 발진(Oscillation)이 발생할 수 있어 회로가 불안정해진다.
Flip-Flops
Flip-Flop은 Latch의 투명성 문제를 해결하기 위해 고안된 저장 장치이다. 주로 Master-Slave 구조를 사용하여 구현한다.
- Master-Slave D Flip-Flop: 두 개의 D Latch를 직렬로 연결하고 클럭을 반전시켜 공급한다.
- Edge-Triggered: 클럭의 레벨(Level)이 아닌 에지(Edge, 상승 또는 하강)에서만 상태를 업데이트한다. 이를 통해 한 클럭 사이클에 데이터가 한 번만 샘플링되도록 보장한다.
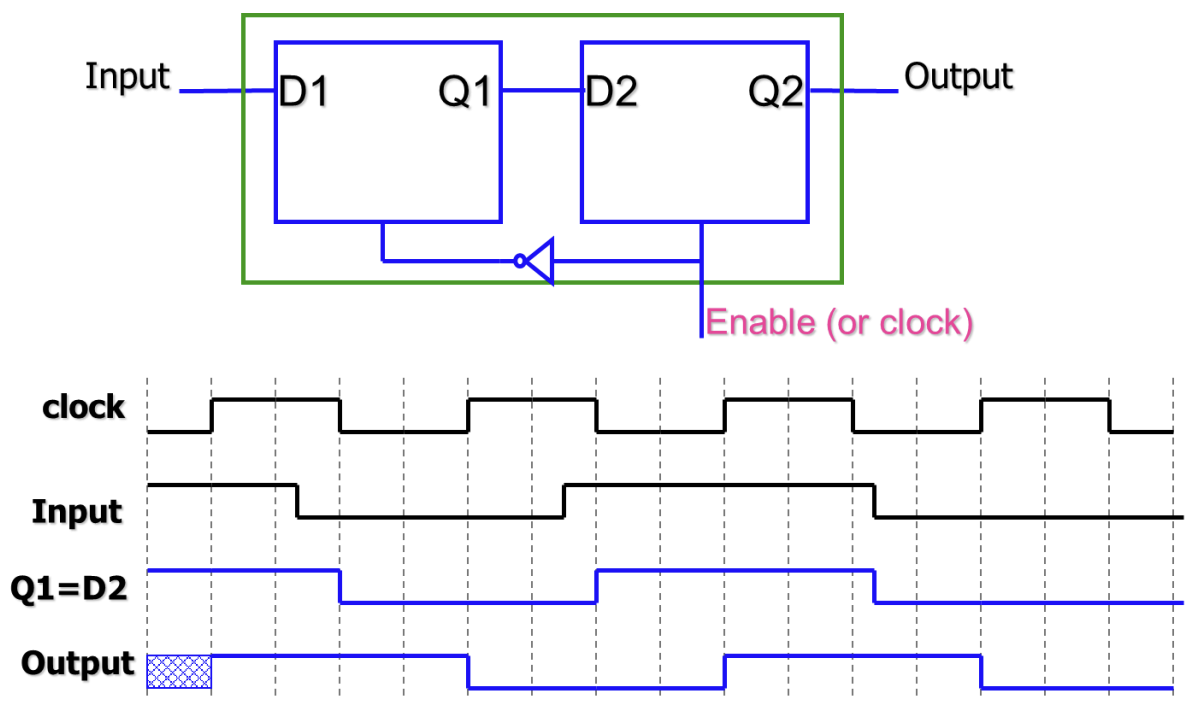
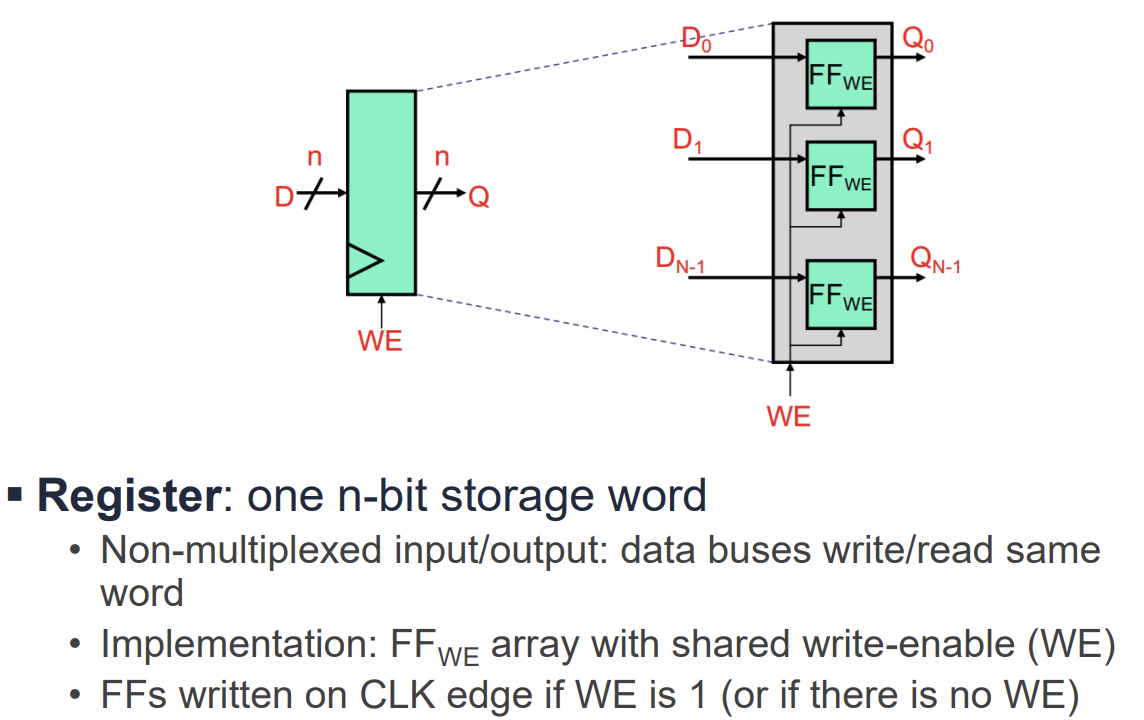
Registers
레지스터는 N비트 데이터를 저장하기 위해 N개의 Flip-Flop을 병렬로 연결한 구조이다.
- Write Enable (WE): 레지스터의 값을 업데이트할지 유지할지를 결정하는 신호이다.
- 구현 방식: 클럭 신호 자체를 게이팅(Gating)하는 것은 글리치(Glitch) 문제로 인해 지양해야 한다. 대신, 멀티플렉서(Mux)를 사용하여 WE가 0일 때는 기존 값을, 1일 때는 새로운 값을 D 입력으로 선택하는 방식을 사용한다.
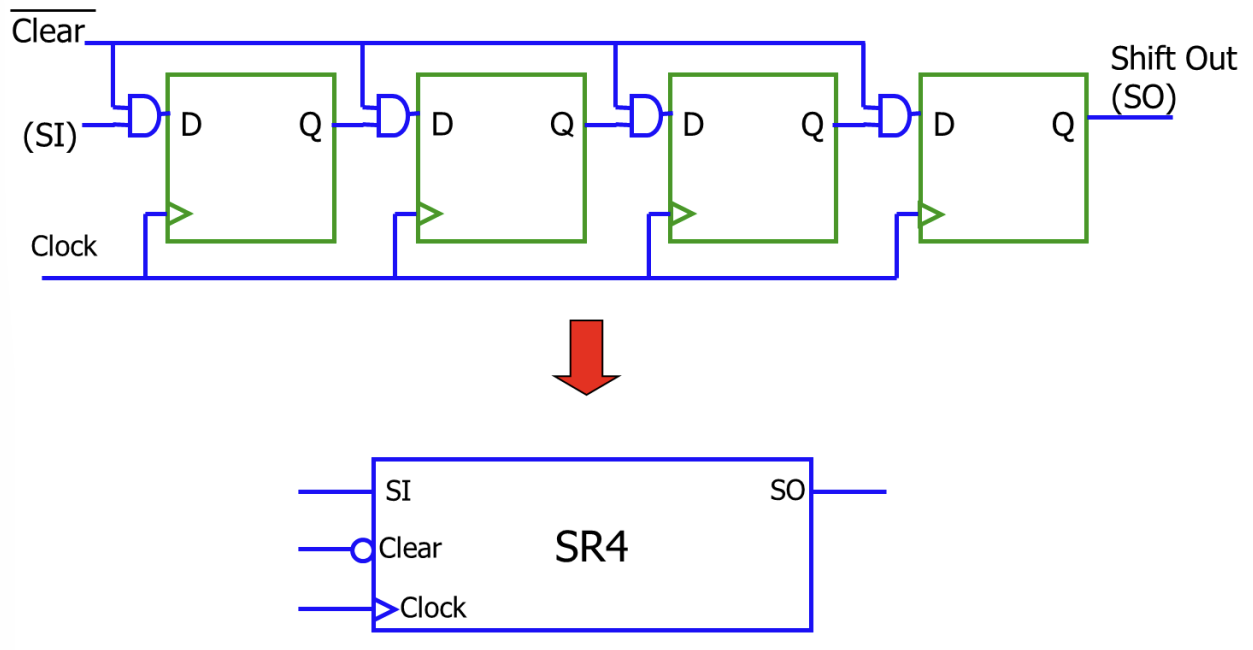
Shift Registers와 Serial Operations
Shift Register는 클럭마다 저장된 비트들을 옆으로 이동시키는 레지스터이다.
- Logical/Arithmetic Shift: 좌우로 비트를 이동시키며, 빈 자리는 0이나 부호 비트로 채운다.
- Serial Transfer: 데이터를 한 비트씩 순차적으로 전송하거나 처리할 때 사용한다.
- Serial Adder: Shift Register와 하나의 Full Adder만을 사용하여 N비트 덧셈을 N 사이클에 걸쳐 수행한다. 하드웨어 면적을 최소화할 수 있지만 속도는 느리다.
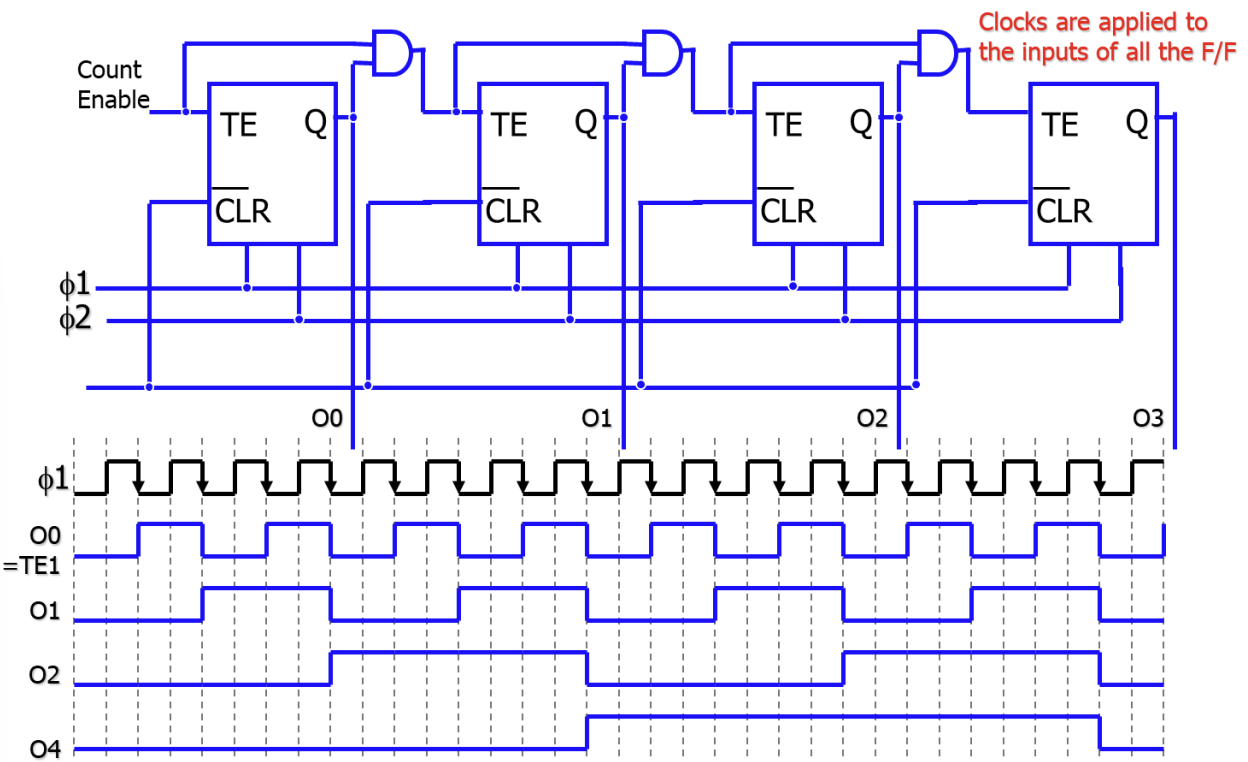
Counters
카운터는 클럭마다 저장된 값을 정해진 순서대로(보통 1씩 증가) 변경하는 순차 회로이다.
- Ripple Counter: 앞단의 Flip-Flop 출력을 다음 단의 클럭으로 사용한다. 구조가 간단하지만 단계별 지연이 누적되어 속도가 느리다.
- Synchronous Counter: 모든 Flip-Flop이 동일한 클럭을 사용한다. 모든 비트가 동시에 업데이트되므로 고속 동작에 유리하다.
- Modulo-N Counter: 0부터 N-1까지 센 후 다시 0으로 초기화되는 카운터이다.
RAM (Random-Access Memory) 개요
RAM은 임의의 데이터에 동일한 시간 내에 접근할 수 있는 메모리이다. 전원이 꺼지면 데이터가 사라지는 휘발성(Volatile) 특성을 가진다. 컴퓨터의 주기억장치(Main Memory)로 주로 사용된다.
RAM은 데이터 저장 방식에 따라 두 가지로 나뉜다.
- SRAM (Static RAM): 플립플롭(Flip-flop) 회로를 사용하여 데이터를 저장한다. 전원이 공급되는 한 데이터를 유지하며, 속도가 빠르지만 비싸고 집적도가 낮다. 주로 캐시 메모리(Cache)로 사용된다.
- DRAM (Dynamic RAM): 커패시터(Capacitor)에 전하를 충전하여 데이터를 저장한다. 시간이 지나면 전하가 누설되므로 주기적인 리프레시(Refresh)가 필요하다. 속도는 상대적으로 느리지만 저렴하고 집적도가 높아 메인 메모리로 사용된다.
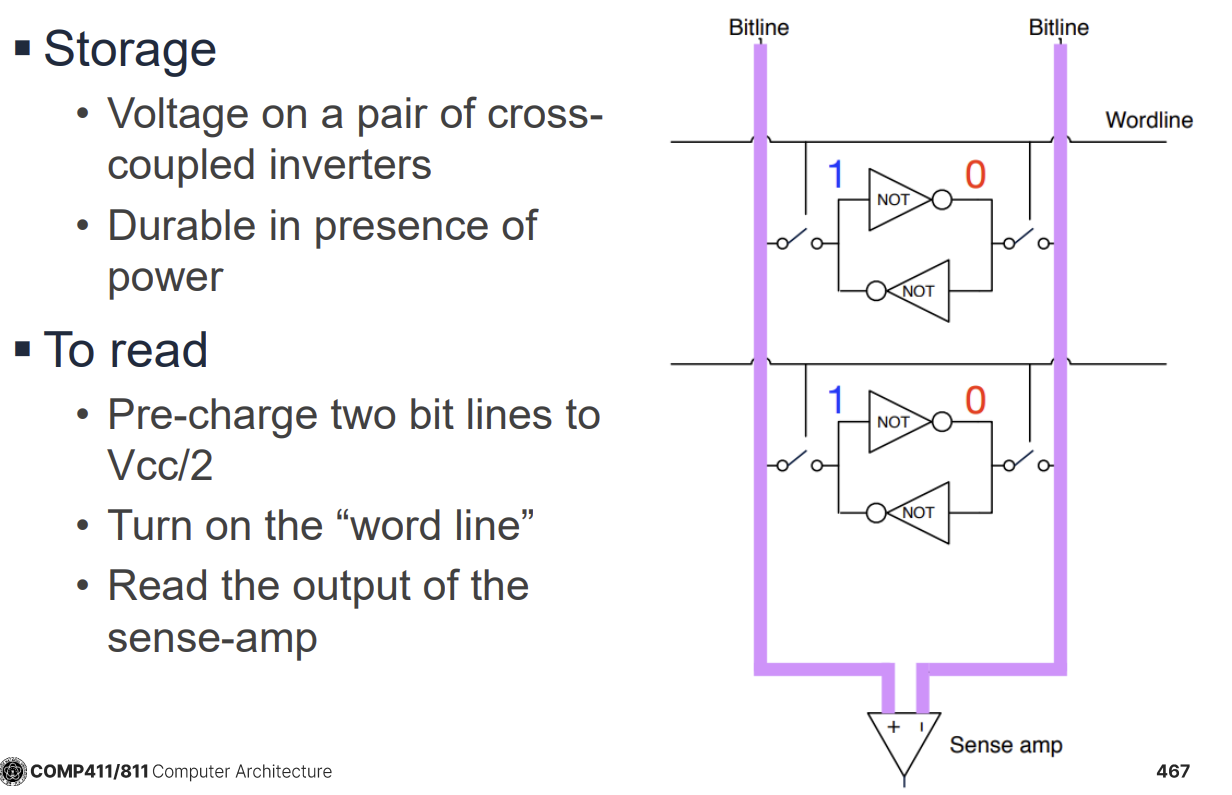
SRAM 구조와 동작
SRAM 셀은 보통 6개의 트랜지스터(6T)로 구성된다. 두 개의 교차 연결된 인버터가 데이터를 저장하고, 두 개의 접근 트랜지스터가 읽기/쓰기를 제어한다.
- Read 동작: 비트라인(Bitline)을 프리차지(Precharge)한 후 워드라인(Wordline)을 활성화한다. 셀의 데이터에 따라 비트라인 중 하나의 전압이 미세하게 떨어지면, 센스 앰프(Sense Amp)가 이를 감지하고 증폭하여 0 또는 1을 판별한다.
- Write 동작: 비트라인에 원하는 데이터(0 또는 1)에 해당하는 전압을 강하게 인가하고 워드라인을 활성화하여 셀 내부의 값을 덮어쓴다.
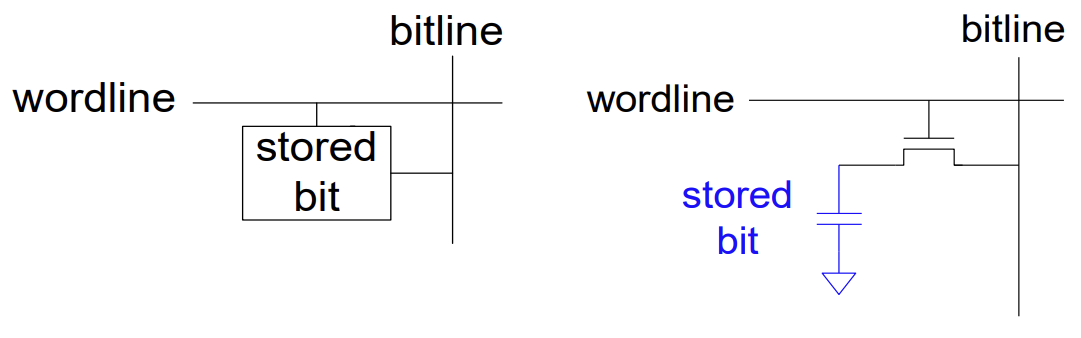
DRAM 구조
DRAM 셀은 1개의 트랜지스터와 1개의 커패시터(1T1C)로 구성된다. 구조가 매우 단순하여 고밀도 집적이 가능하다.
- Read 동작 시 커패시터의 전하가 비트라인으로 공유되면서 전압 변화를 일으키는데, 이 과정에서 저장된 데이터가 파괴되므로(Destructive Read) 다시 써주는 과정(Write-back)이 필요하다.
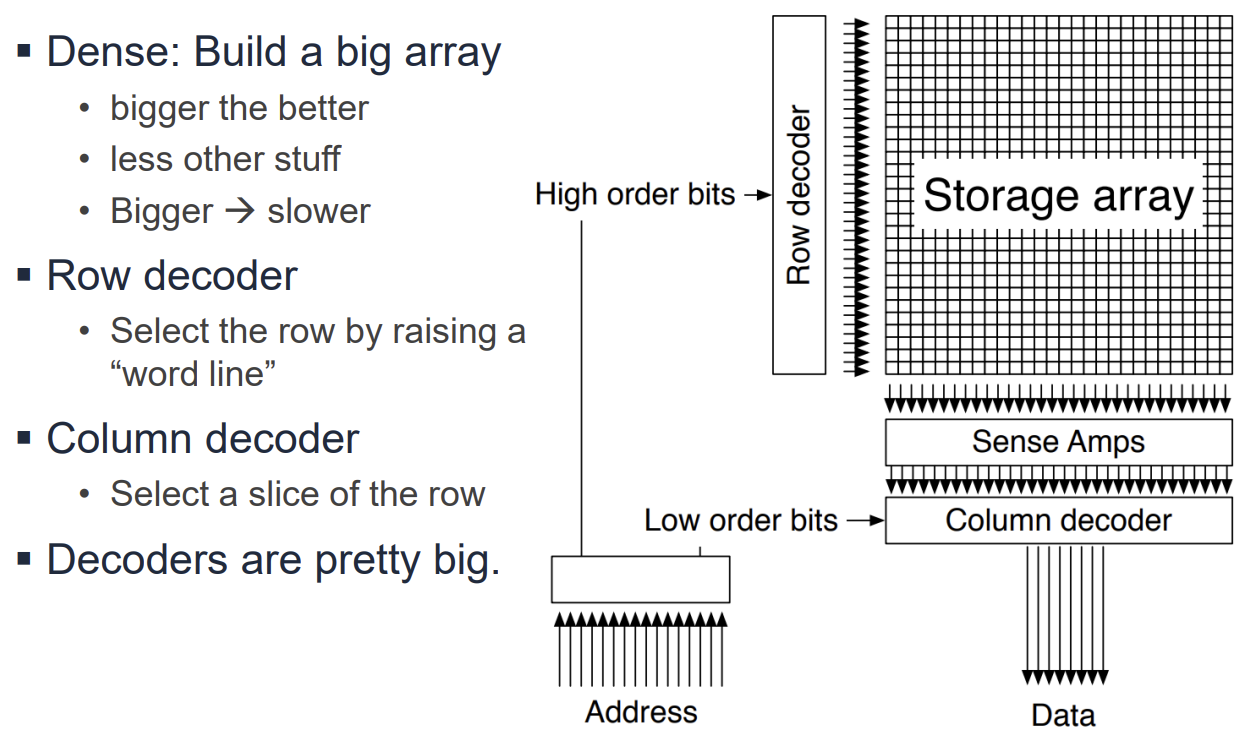
Memory Architecture
메모리는 2차원 배열 구조로 구성된다.
- Row Decoder: 주소의 상위 비트를 사용하여 특정 행(Wordline)을 활성화한다.
- Column Decoder: 주소의 하위 비트를 사용하여 활성화된 행의 데이터 중 필요한 부분(Bitline)을 선택한다.
- 대용량 메모리는 속도와 효율을 위해 여러 개의 작은 서브어레이(Subarray)와 뱅크(Bank)로 나뉘어 구성된다.
Multi-Ported SRAM
여러 개의 읽기/쓰기 포트를 가진 SRAM은 한 사이클에 여러 접근을 동시에 수행할 수 있다.
- 레지스터 파일(Register File) 구현에 필수적이다.
- 포트 수가 늘어날수록 트랜지스터와 배선이 늘어나 면적이 으로 증가한다.
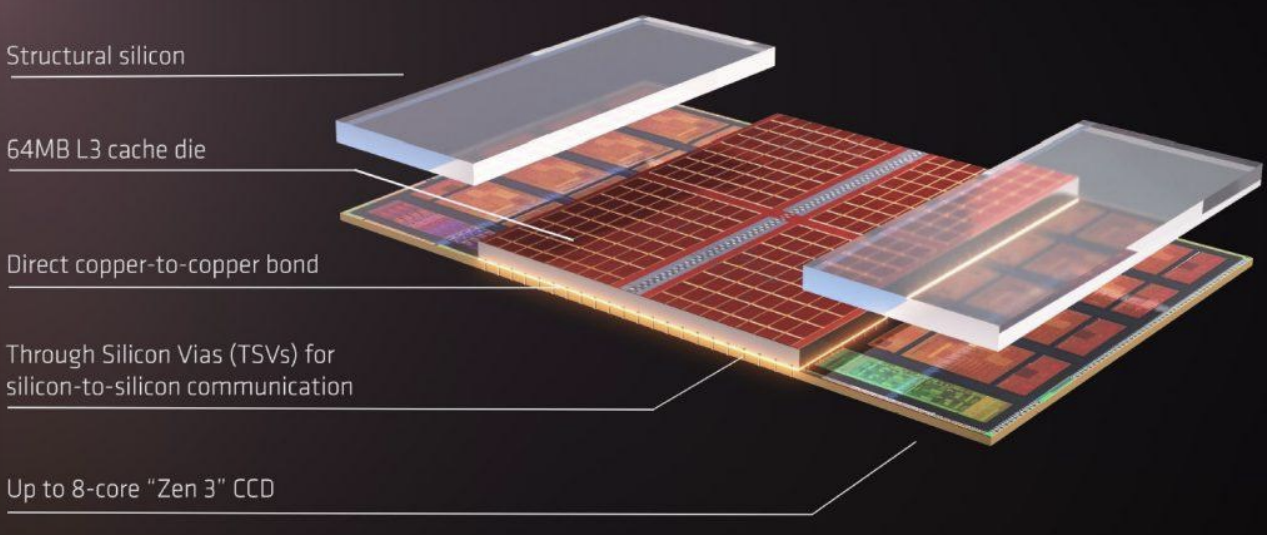
3D Stacking과 V-Cache
반도체 공정의 한계를 극복하기 위해 칩을 수직으로 적층하는 3D Stacking 기술이 도입되었다.
- TSV(Through-Silicon Via): 실리콘 칩을 수직으로 관통하는 전극을 통해 층간 통신을 수행한다. 와이어 길이를 줄여 속도를 높이고 전력 소모를 줄일 수 있다.
- AMD 3D V-Cache: 프로세서 다이 위에 L3 캐시 다이를 적층하여 용량을 대폭 늘린 기술이다(예: 32MB 96MB).
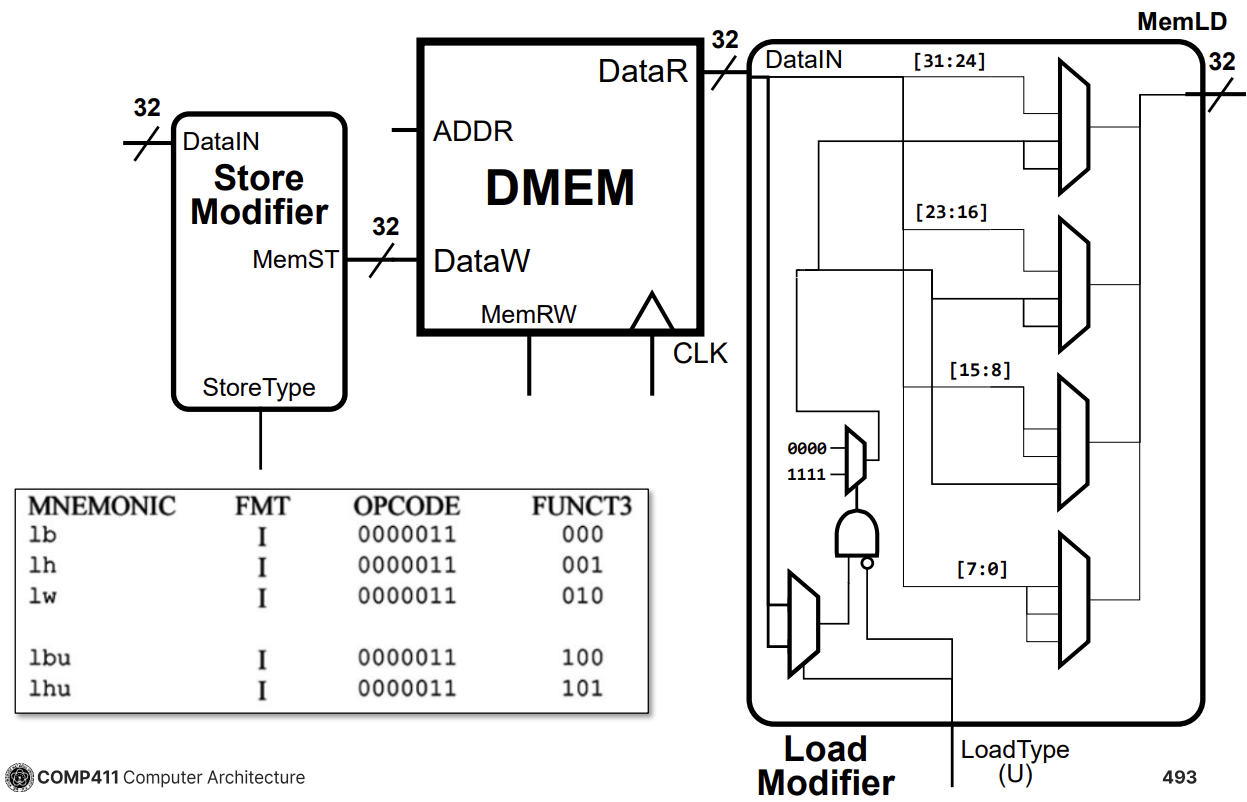
Load/Store Unit (LSU)
LSU는 메모리와 프로세서 간의 데이터 이동을 담당한다.
- Load Modifier: 메모리에서 읽어온 데이터(32비트) 중 필요한 바이트나 하프워드를 추출하고, 부호 확장(Sign Extension) 또는 제로 확장(Zero Extension)을 수행한다.
lb,lh,lw,lbu,lhu명령어 처리를 지원한다. - Store Modifier: 레지스터의 데이터를 메모리에 쓸 때, 바이트나 하프워드 단위 쓰기를 위해 정렬 및 마스킹을 수행한다.
sb,sh,sw명령어 처리를 지원한다.
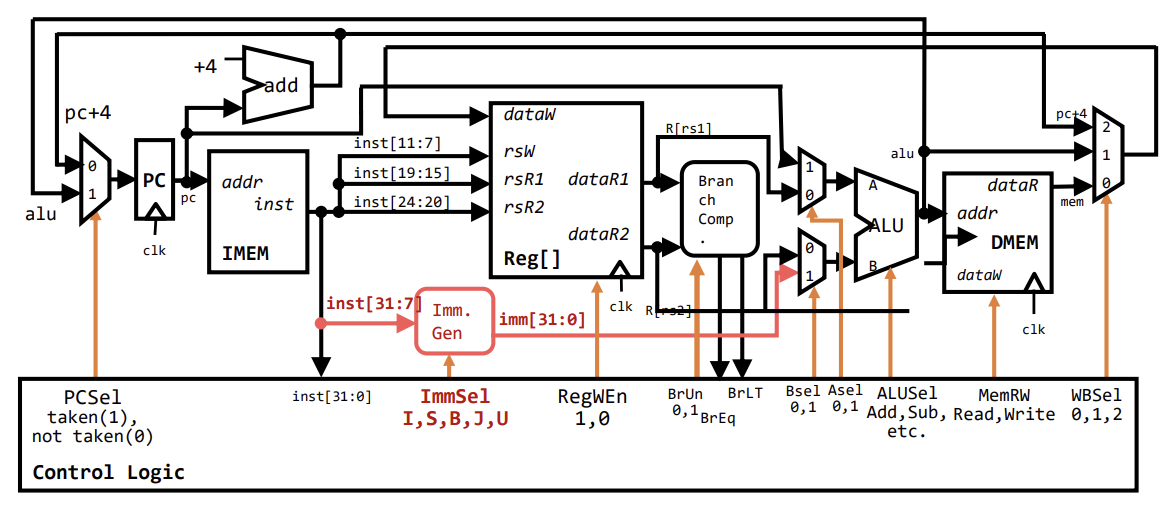
Processor Datapath Design
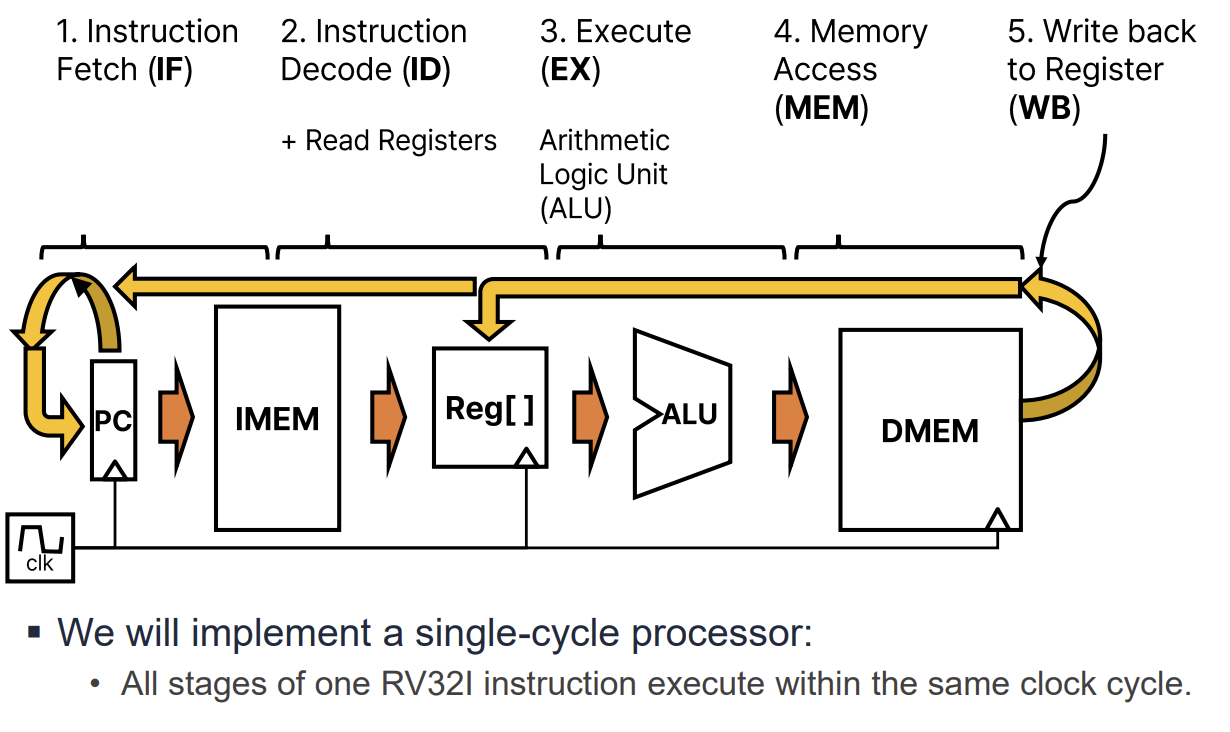
프로세서의 데이터패스는 명령어 실행을 위해 단계적으로 설계된다. 이는 단일 거대 블록으로 설계하는 것보다 관리와 최적화가 쉽기 때문이다. 기본 실행 단계는 다음과 같다.
- Instruction Fetch (IF): PC가 가리키는 주소에서 명령어를 가져온다.
- Instruction Decode (ID): 명령어를 해석하고 필요한 레지스터 값을 읽는다.
- Execute (EX): ALU를 사용하여 연산을 수행하거나 주소를 계산한다.
- Memory Access (MEM): 데이터 메모리에 접근한다.
- Write Back (WB): 결과를 레지스터에 쓴다.
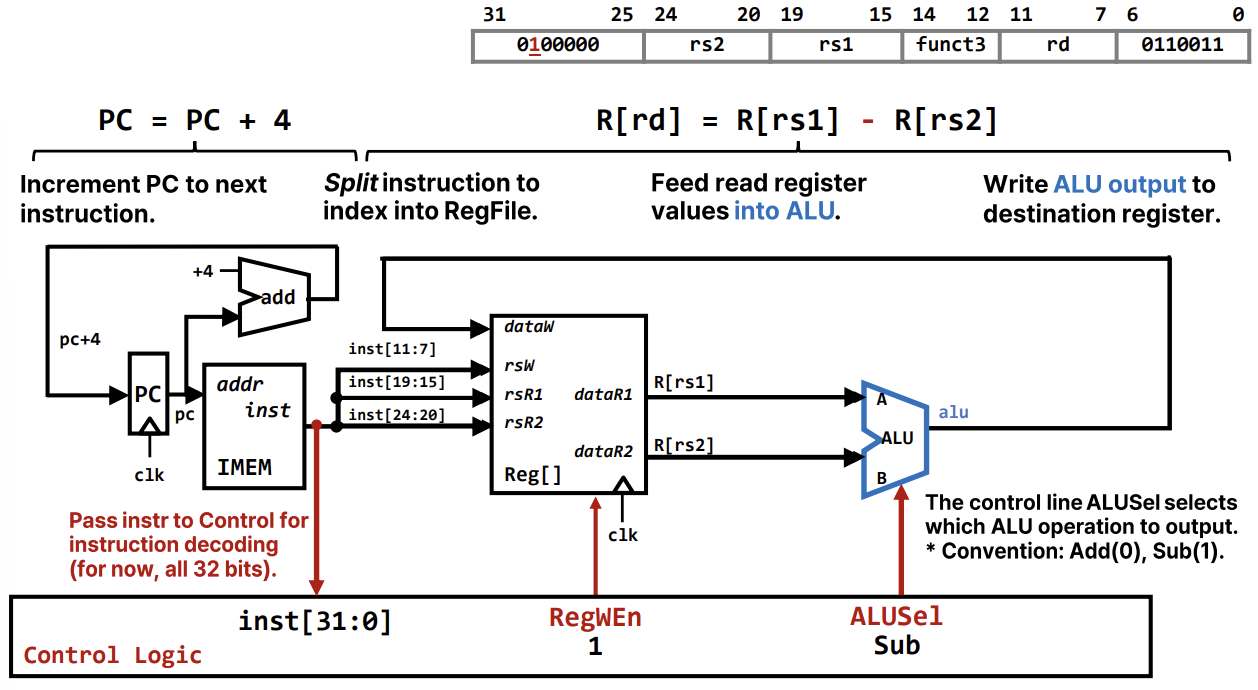
R-Type Instruction Datapath
R-Type 명령어(예: add, sub)는 레지스터 간의 연산을 수행한다.
add rd, rs1, rs2:sub rd, rs1, rs2:- 데이터패스 동작:
- PC가 가리키는 명령어를 Fetch한다.
- 명령어의
rs1,rs2필드를 이용해 레지스터 파일에서 두 값을 읽는다. - ALU가 두 값을 더하거나 뺀다. (ALUSel 제어 신호로 선택)
- 결과를 레지스터 파일의
rd에 쓴다. (RegWEn=1) - PC는 4 증가하여 다음 명령어를 가리킨다.
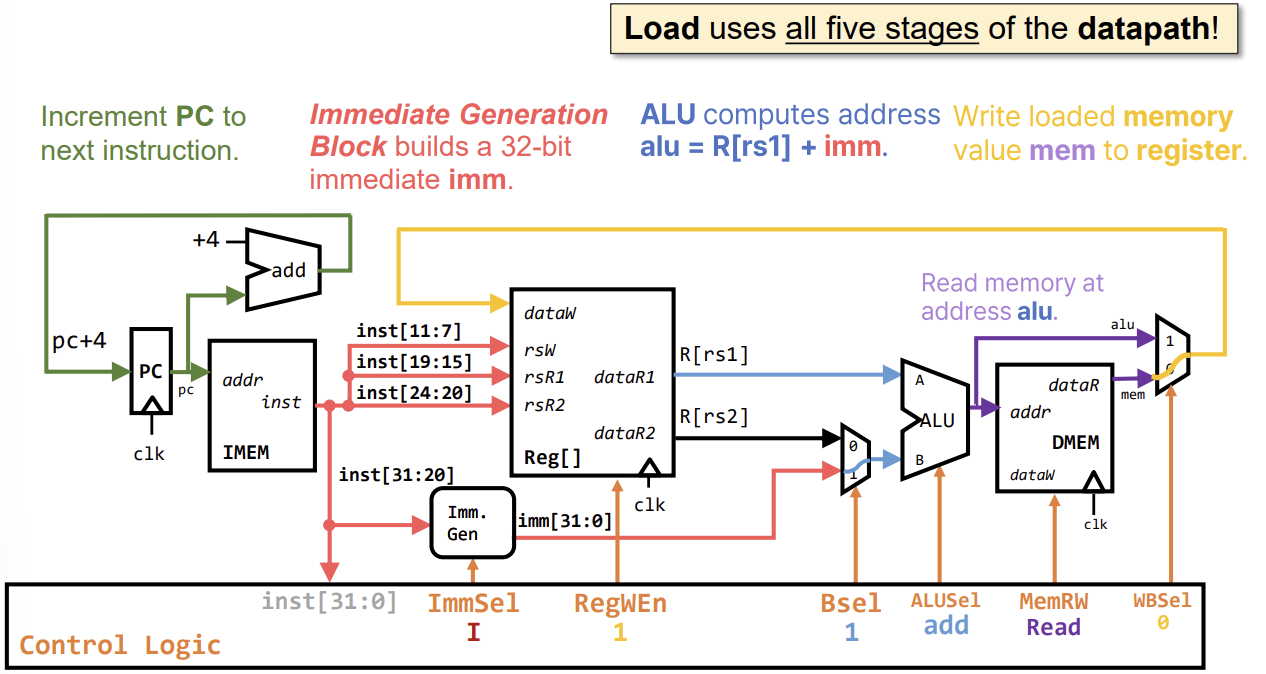
I-Type & S-Type Instruction Datapath
I-Type 명령어(예: addi, lw)는 즉치값(Immediate)을 사용한다.
addi rd, rs1, imm:- Immediate Generation Block: 명령어의 일부 비트를 추출하고 부호 확장(Sign-extend)하여 32비트 즉치값을 생성한다.
- ALU 입력 선택: Mux를 추가하여 ALU의 두 번째 입력으로 레지스터 값(
rs2) 대신 즉치값(imm)을 선택할 수 있게 한다. (Bsel 제어 신호 사용)
Load Instruction (lw)
- ALU는 주소를 계산하고, 그 주소로 데이터 메모리에 접근하여 값을 읽은 후 레지스터에 쓴다.
S-Type Instruction (sw)
sw rs2, imm(rs1):- 레지스터 파일 읽기 포트가 두 개 필요하다(베이스 주소
rs1과 저장할 데이터rs2). - ALU는 주소를 계산하고, 데이터 메모리에
rs2값을 쓴다. 레지스터 쓰기는 발생하지 않는다(RegWEn=0).
Branch & Jump Datapath
B-Type Instruction (beq, bne, blt 등)
- 조건이 참이면 , 거짓이면 .
- 비교를 위해 ALU를 사용하면 주소 계산을 동시에 할 수 없다. 따라서 별도의 Branch Comparator를 추가하여 레지스터 값을 비교한다.
- Control Logic은 비교 결과(BrEq, BrLT)를 바탕으로 PC의 다음 값을 선택한다(PCSel).
J-Type Instruction (jal)
jal rd, imm: , .- PC+4를 레지스터에 저장해야 하므로, 레지스터 쓰기 데이터 선택 Mux(WBSel)를 확장하여 PC+4 경로를 추가한다.
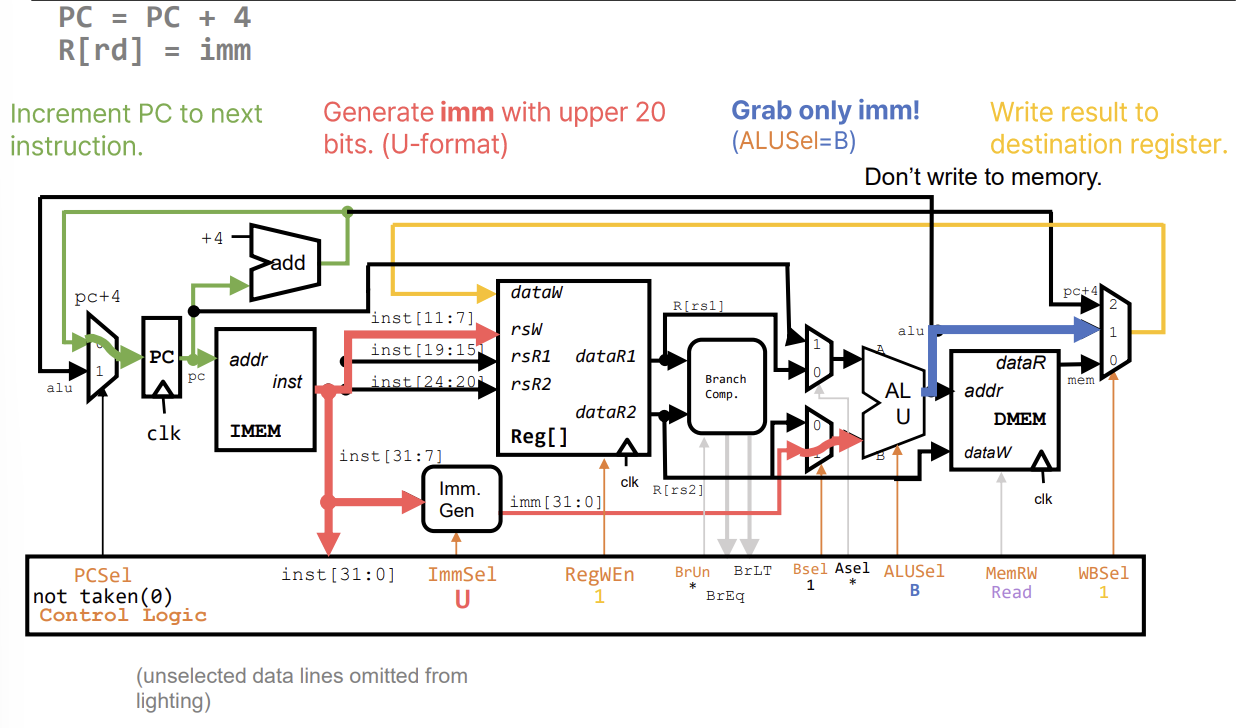
U-Type Instruction (lui, auipc)
- 상위 20비트 즉치값을 사용한다. Immediate Generator가 이를 처리한다.
auipc: . PC와 상위 즉치값을 더한다.lui: . ALU의 첫 번째 입력을 0으로 하거나 별도 경로를 통해 처리한다.
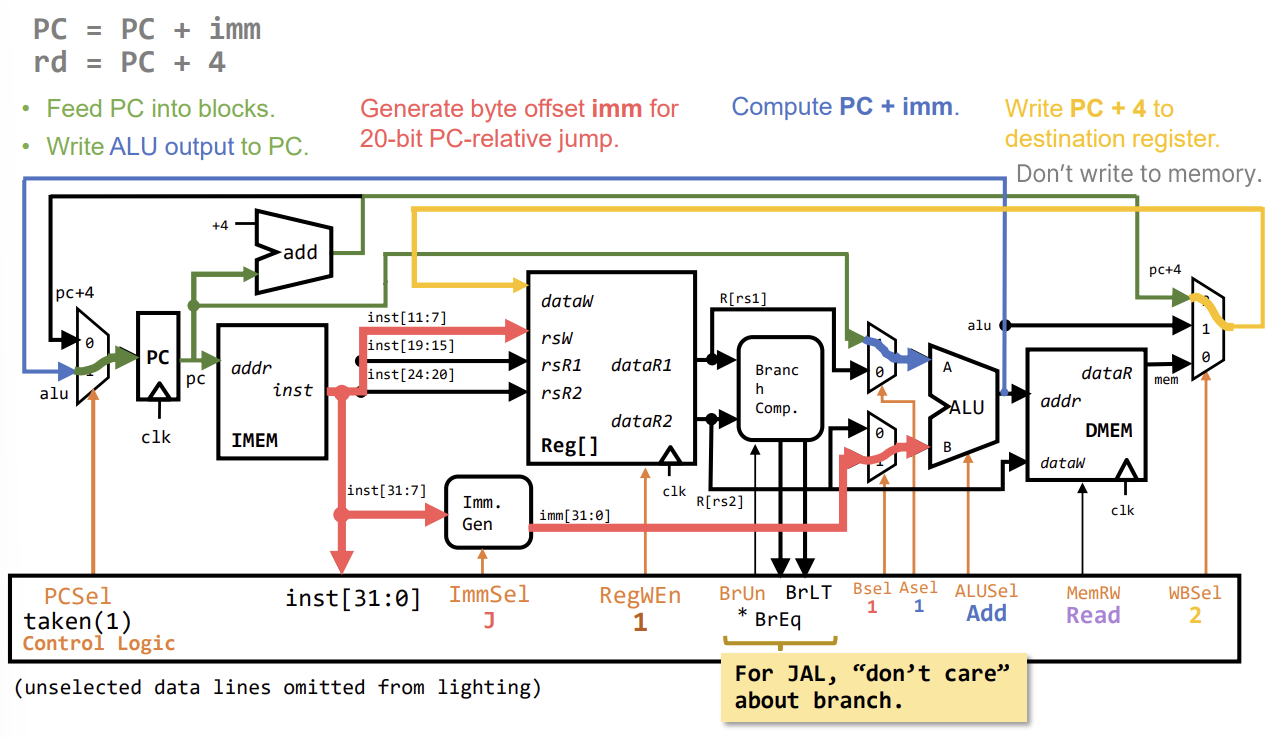
Control Logic Summary
Control Logic은 현재 명령어(Opcode, Funct3, Funct7)를 입력받아 데이터패스의 각 요소를 제어하는 신호들을 생성한다.
ImmSel: Immediate Generator가 어떤 형식(I, S, B, U, J)으로 즉치값을 만들지 결정.RegWEn: 레지스터 파일 쓰기 활성화 여부.Bsel: ALU의 두 번째 입력 선택 (레지스터 vs 즉치값).ALUSel: ALU가 수행할 연산 (Add, Sub, And, Or 등).MemRW: 메모리 쓰기 활성화 여부.WBSel: 레지스터에 쓸 데이터 선택 (ALU 결과, 메모리 값, PC+4 등).PCSel: 다음 PC 값 선택 (PC+4 vs 분기/점프 타겟).
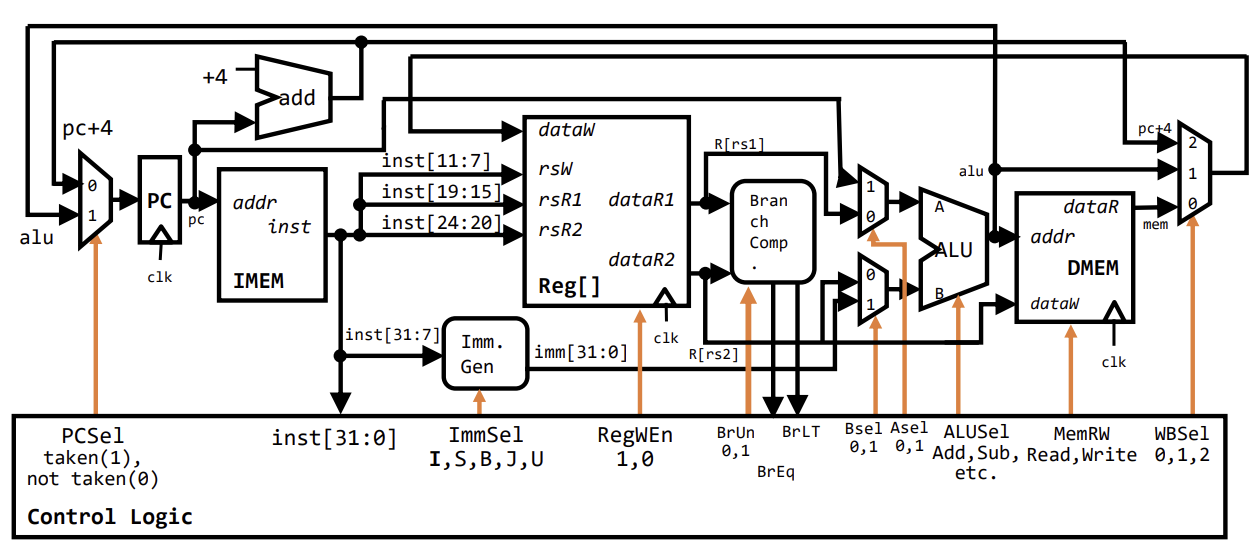
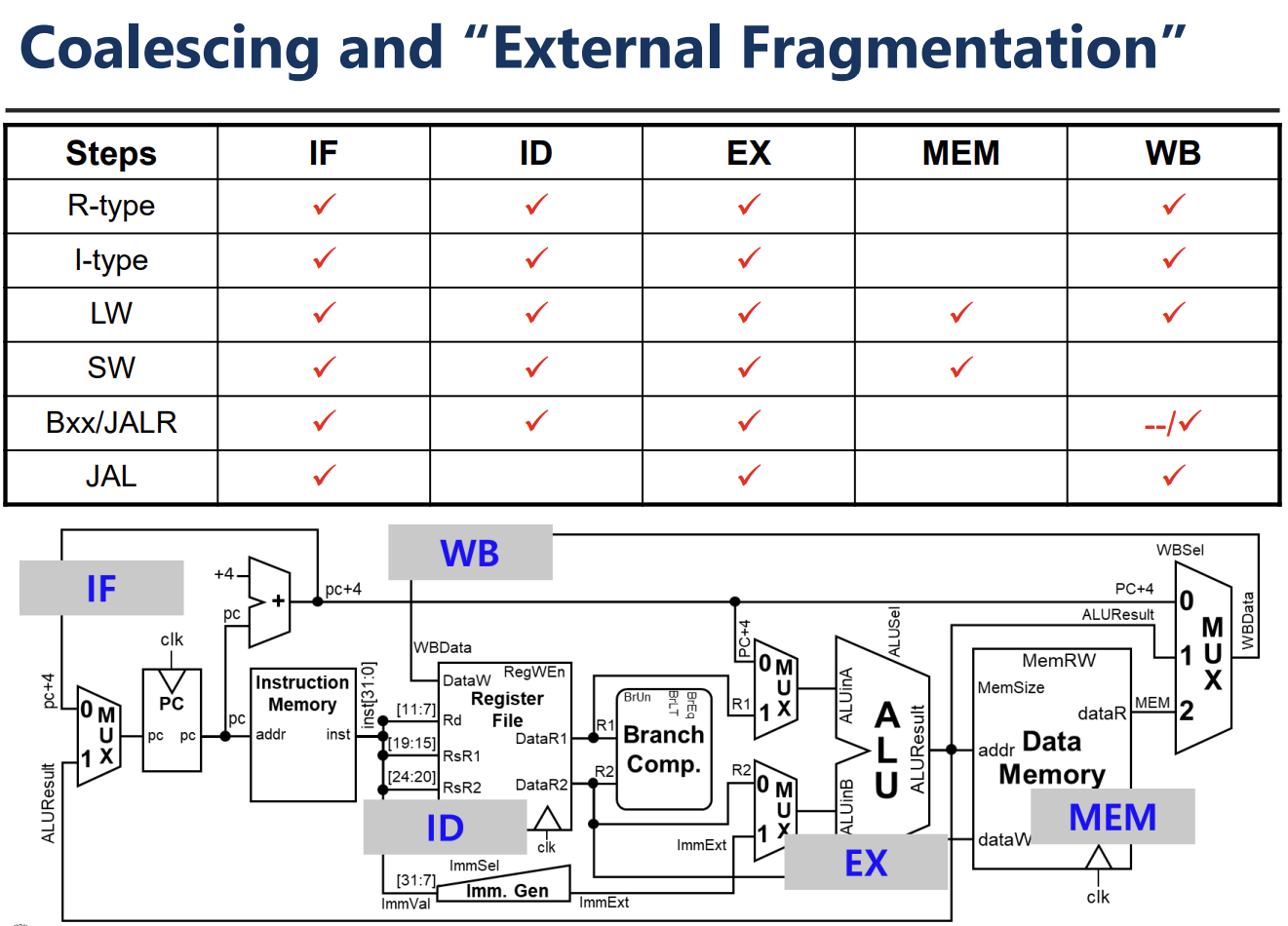
Complete RV32I Datapath와 Control Logic
단일 사이클 프로세서(Single-Cycle Processor) 설계의 마지막 단계는 데이터패스(Datapath)와 제어 로직(Control Logic)을 통합하는 것이다. 완성된 RV32I 데이터패스는 명령어 인출(IF), 해독(ID), 실행(EX), 메모리 접근(MEM), 레지스터 쓰기(WB)의 5단계를 모두 포함하며, 각 단계는 제어 신호에 의해 조율된다.
![PDF p.570: Complete RV32I Datapath diagram connecting all stages and control logic]
Control Logic은 명령어의 Opcode, Funct3, Funct7 필드를 입력으로 받아 데이터패스를 제어하는 신호를 생성한다.
- PCSel: 다음 PC 값을 선택한다(순차 실행 또는 분기).
- ImmSel: Immediate Generator의 동작 방식을 결정한다.
- RegWEn: 레지스터 파일에 값을 쓸지 결정한다.
- BrUn, BrLT, BrEq: 분기 비교기(Branch Comparator)의 동작을 제어한다.
- Bsel, Asel: ALU의 입력 피연산자를 선택한다.
- ALUSel: ALU가 수행할 연산 종류를 지정한다.
- MemRW: 데이터 메모리의 읽기/쓰기 모드를 제어한다.
- WBSel: 레지스터에 기록할 데이터를 선택한다(ALU 결과, 메모리 값, PC+4 등).
Single-Cycle Processor의 성능 분석
프로세서의 성능은 다음 공식을 따른다. Execution Time = Instruction Count * CPI * Cycle Time
단일 사이클 프로세서의 특징
- CPI (Cycles Per Instruction): 모든 명령어는 1 사이클에 실행되므로 CPI는 1이다.
- Cycle Time: 클럭 주기는 가장 실행 시간이 긴 명령어(Critical Path)에 의해 결정된다. 모든 명령어의 실행 시간이 동일하게 고정되어야 하기 때문이다.
Critical Path(임계 경로) 분석
가장 긴 지연 시간을 가지는 명령어는 주로 Load 명령어(lw)이다.
Critical Path = + (IMEM) + + + (DMEM) + +
![PDF p.592: Performance Analysis showing the critical path delay components]
단일 사이클 설계의 한계
- 비효율성: 덧셈(
add)과 같이 빨리 끝날 수 있는 명령어도 가장 느린lw명령어에 맞춰진 긴 클럭 주기를 사용해야 한다. 이는 "Make the common case fast"라는 설계 원칙에 위배된다. - 하드웨어 중복: 덧셈기와 ALU가 별도로 필요하고, 데이터 메모리와 명령어 메모리가 분리되어야 하는 등 자원 효율이 낮다.
Control Logic 구현 방식
제어 로직을 구현하는 방법에는 크게 세 가지가 있다.
Hardwired Control
- 조합 논리 회로(Combinational Logic)를 사용하여 제어 신호를 생성한다.
- 장점: 속도가 빠르고 지연 시간이 적다.
- 단점: 설계가 복잡하고 수정이 어려우며, ISA가 복잡해질수록 구현 난이도가 급격히 상승한다. RISC 프로세서에서 주로 사용된다.

Microprogrammed Control
- 제어 신호들을 마이크로프로그램(Microprogram)이라는 작은 소프트웨어 루틴으로 저장하여 관리한다.
- Control Memory(ROM)에 마이크로명령어(Microinstruction)들이 저장되며, 각 기계어 명령어는 일련의 마이크로명령어 주소로 매핑되어 실행된다.
- 장점: 설계가 유연하고 수정이 쉽다. 복잡한 명령어(CISC)를 구현하기 용이하다.
- 단점: 하드와이어드 방식보다 느리다.
FSM-Based Control
- 유한 상태 머신(Finite State Machine)을 사용하여 제어 신호를 생성한다.
- 다중 사이클(Multi-cycle) 프로세서에서 각 단계(State)별로 다른 제어 신호를 출력하는 데 적합하다.
Microarchitecture Overview
[cite_start]Microarchitecture는 특정 Architecture를 하드웨어로 구현하는 방법을 의미한다[cite: 5, 7]. [cite_start]Processor는 크게 기능적 블록인 Datapath와 제어 신호를 생성하는 Control로 구성된다[cite: 8, 9, 10]. [cite_start]하나의 Architecture에 대해 다양한 구현 방식이 존재할 수 있다[cite: 14].
- [cite_start]Single-cycle: 각 명령어가 하나의 Cycle에서 실행된다[cite: 15, 16].
- [cite_start]Multicycle: 각 명령어가 일련의 짧은 단계들로 나누어 실행된다[cite: 17, 18].
- [cite_start]Pipelined: 각 명령어가 단계별로 나뉘고 여러 명령어가 동시에 실행된다[cite: 19, 20].
RISC-V Single-Cycle Processor Design
Single-cycle 구현에서는 모든 명령어가 한 클럭 사이클 내에 완료되어야 한다. 이를 위해 Datapath와 Control Unit이 유기적으로 연결된다.
![PDF p.607: RISC-V Single-Cycle Processor Schematic including Instruction Memory, Register File, ALU, and Data Memory]
주요 구성 요소는 다음과 같다.
- [cite_start]Instruction Memory: PC(Program Counter) 주소에 따라 명령어를 인출한다[cite: 46].
- [cite_start]Register File: 명령어의 필드(rs1, rs2, rd)에 따라 레지스터를 읽거나 쓴다[cite: 55, 56].
- [cite_start]ALU (Arithmetic Logic Unit): 연산 및 주소 계산을 수행한다[cite: 84].
- [cite_start]Data Memory: Load/Store 명령어 실행 시 데이터에 접근한다[cite: 95].
- [cite_start]Immediate Generator: 명령어 내의 상수 값을 32비트로 확장한다[cite: 76].
[cite_start]Control Unit은 명령어의 Opcode와 Funct 필드를 해석하여 Datapath의 Multiplexer(MUX)와 Write Enable 신호들을 제어한다[cite: 26, 30].
![PDF p.612: Single-Cycle Control Logic High-Level and Low-Level View]
[cite_start]Control Unit은 Main Decoder와 ALU Decoder로 구성된다[cite: 339, 355]. [cite_start]Main Decoder는 Opcode를 입력받아 Branch, MemWrite, RegWrite 등의 제어 신호와 2비트 ALUOp를 생성한다[cite: 339, 345, 350]. [cite_start]ALU Decoder는 ALUOp와 instruction의 funct3, funct7 필드를 사용하여 최종적인 ALUControl 신호를 생성한다[cite: 354, 356].
ALU Design Details
[cite_start]ALU는 덧셈, 뺄셈, 논리 연산, 시프트, 비교 연산 등 다양한 기능을 수행해야 한다[cite: 362].
![PDF p.614: Internal Architecture of ALU showing Logic, Arithmetic, Shifter, and Comparator blocks]
ALU 내부 구현의 세부 사항은 다음과 같다.
- [cite_start]Adder/Subtractor: 덧셈과 뺄셈을 수행하며, 뺄셈은 2의 보수를 이용해 덧셈으로 처리한다[cite: 517]. [cite_start]속도 향상을 위해 Carry-Lookahead Adder (CLA)를 사용하기도 한다[cite: 528, 562].
- [cite_start]Shifter: Barrel Shifter 구조를 사용하여 여러 비트의 이동을 효율적으로 처리한다[cite: 585]. [cite_start]여러 단계의 MUX를 통해 지정된 shift amount만큼 이동시킨다[cite: 589, 591].
- [cite_start]Comparator: 두 입력값의 크기를 비교한다[cite: 610]. [cite_start]Magnitude Comparator는 XOR 게이트 등을 사용하여 같다(Equal), 작다(Less Than) 등의 상태를 판별한다[cite: 613]. [cite_start]32비트 비교를 위해 4비트 비교기를 직렬로 연결(Cascading)하는 방식을 사용한다[cite: 655].
Immediate Generator
[cite_start]RISC-V 명령어 형식(I, S, B, U, J type)에 따라 Immediate 필드의 위치가 다르다[cite: 676]. [cite_start]Immediate Generator는 이를 32비트 부호 있는 정수로 확장하는 역할을 한다[cite: 751].
![PDF p.625: Immediate Generator Logic for I, S, B types showing bit shuffling]
- [cite_start]I-Type: 12비트 값을 그대로 부호 확장한다[cite: 756].
- [cite_start]S-Type: 명령어의 두 부분에 나뉜 비트를 합쳐 12비트 값을 만든다[cite: 756].
- [cite_start]B-Type (Branch): S-Type과 유사하지만 1비트 좌측 시프트된 값을 생성하며, 0번 비트는 항상 0이다[cite: 771, 784]. [cite_start]RISC-V는 분기 오프셋을 2바이트(Half-word) 단위로 처리하기 때문이다[cite: 791].
- [cite_start]U/J-Type: 상위 20비트 혹은 점프 오프셋을 처리하며 다른 확장 로직을 요구한다[cite: 884].
[cite_start]명령어 인코딩에서 Immediate 비트들이 섞여 있는 이유는 하드웨어 MUX의 복잡도를 줄이고 입력 비트의 위치를 최대한 고정하기 위함이다[cite: 955, 956].
Single-Cycle Hardwired Control
Single-cycle 프로세서의 클럭 주기는 명령어 실행에 필요한 모든 단계가 완료될 수 있을 만큼 충분히 길어야 한다. 가장 긴 지연 시간을 가지는 경로(Critical Path)가 클럭 주기()를 결정한다. 일반적인 실행 단계는 다음과 같다.
- Instruction Fetch
- Decode and Register Fetch
- ALU Operation
- Data Fetch (필요 시)
- Register Write-back.
주요 제어 신호(Control Signals)는 다음과 같이 정의된다.
- PCSel: 다음 PC 값을 PC+4로 할지 분기 목표 주소로 할지 결정한다.
- RegWE: 레지스터 파일에 값을 쓸지 여부를 결정한다.
- BrUn: 비교 연산 시 부호 없는 정수로 처리할지 결정한다.
- ASel/BSel: ALU의 입력으로 레지스터 값을 사용할지, PC나 Immediate 값을 사용할지 선택한다.
- MemRW: 메모리 읽기/쓰기를 제어한다.
- WBSel: 레지스터에 기록할 데이터를 메모리, ALU 결과, PC+4 중 무엇으로 할지 선택한다.
Performance and Tradeoffs
CPU 설계에는 성능, 비용, 전력 소모 간의 상충 관계(Tradeoff)가 존재한다. 성능에 관한 Iron Law는 다음과 같다: .
Single-Cycle Datapath 설계의 특징은 다음과 같다.
- CPI (Cycles Per Instruction)는 1이다.
- 클럭 주기()는 가장 느린 명령어(주로 Load 명령어)의 경로에 맞춰야 하므로 길어진다.
- 빠른 명령어도 느린 클럭 주기에 맞춰 실행되므로 비효율적이고 유연성이 떨어진다.
이러한 단점을 극복하고 클럭 주기를 줄이기 위해 Pipelining 기법이 사용된다. Pipelining은 Datapath를 여러 단계로 나누어 동시에 여러 명령어를 처리함으로써 전체적인 처리량(Throughput)을 높인다.
Other Architectures
강의에서는 RISC-V 외에도 다른 ISA의 구현을 간략히 다룬다.
- ARMv4: Single-cycle 및 Multi-cycle 구현이 존재하며, PC가 R15 레지스터로 취급되는 등의 차이가 있다.
- MIPS: RISC-V와 매우 유사한 구조를 가지며 Single-cycle 구현 예시가 제시되었다.
L5
Course Overview and Processor Design Context
이번 강의는 Advanced Processor Technologies의 첫 번째 파트로, Pipelining을 다루기 위한 기초 단계이다. 강의의 전체 흐름은 컴퓨터 구조 기초, 성능 분석, ISA 설계를 거쳐 Single-Cycle Processor Design을 완료한 후, 현재 Pipelining과 Pipeline Hazard, Instruction Level Parallelism으로 나아가는 단계에 있다.
최신 프로세서(예: AMD EPYC)는 수많은 Core와 Cache, Memory Controller 등이 집적된 복잡한 구조를 가지지만, 기본적으로 명령어 처리의 핵심 원리는 Fetch, Decode, Execute, Memory Access, Write Back의 5단계를 따른다.
Clocking Methodology and Sequential Logic
Digital System에서 Clock은 상태 업데이트를 동기화하는 주기적인 신호이다. 프로세서는 상태 요소(State Elements, 레지스터 등)와 조합 논리(Combinational Logic)로 구성된다. Single-clock Synchronous Discipline에 따르면, 모든 클럭 소자는 단일 클럭 신호를 공유하며, 조합 논리의 루프(Cycle)는 허용되지 않는다. 클럭 주기는 회로 내의 가장 긴 지연 시간(Longest Delay)에 의해 결정된다.
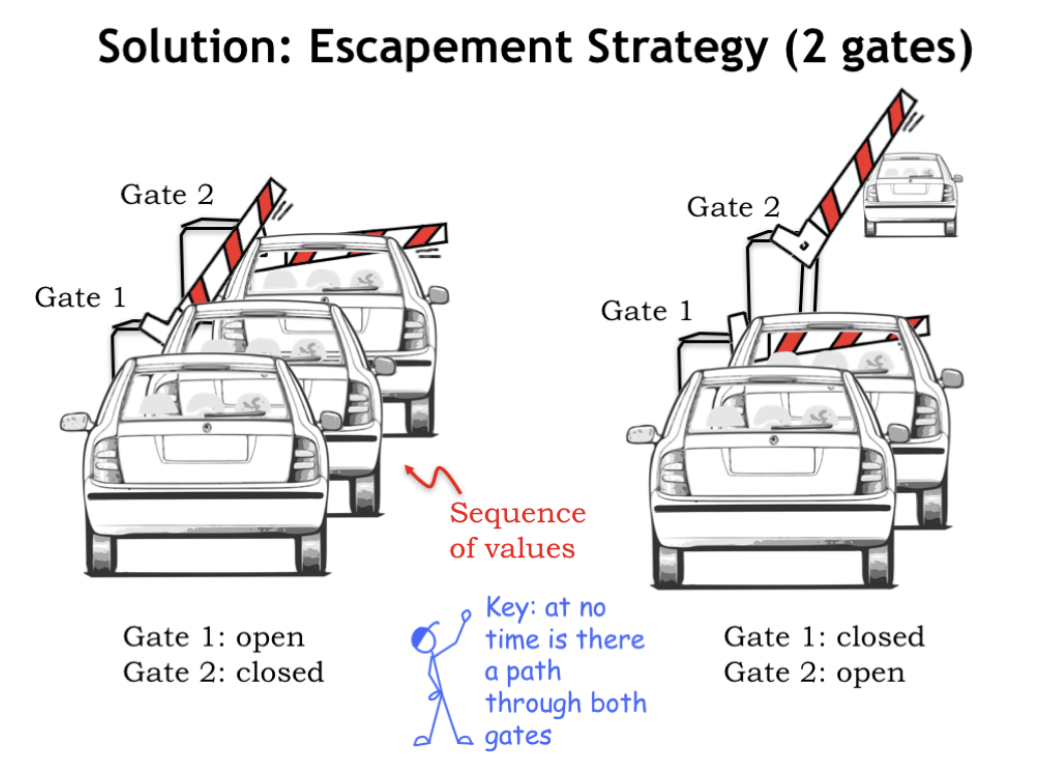 데이터의 흐름을 제어하기 위해 Escapement Strategy를 사용한다. 이는 두 개의 게이트를 사용하여 한 번에 하나의 데이터만 통과하도록 제어하는 방식이다.
데이터의 흐름을 제어하기 위해 Escapement Strategy를 사용한다. 이는 두 개의 게이트를 사용하여 한 번에 하나의 데이터만 통과하도록 제어하는 방식이다.
Timing Constraints and Analysis
순차 회로가 올바르게 동작하기 위해서는 엄격한 타이밍 제약 조건을 만족해야 한다.
- Setup Time (): 클럭 엣지(Rising Edge)가 발생하기 전, 데이터가 안정적으로 유지되어야 하는 최소 시간이다.
- Hold Time (): 클럭 엣지가 발생한 후, 데이터가 안정적으로 유지되어야 하는 최소 시간이다.
- Propagation Delay (): 클럭 엣지 후 출력이 안정화되기까지 걸리는 최대 시간이다.
- Contamination Delay (): 클럭 엣지 후 출력이 변하기 시작하는(불안정해지는) 최소 시간이다.
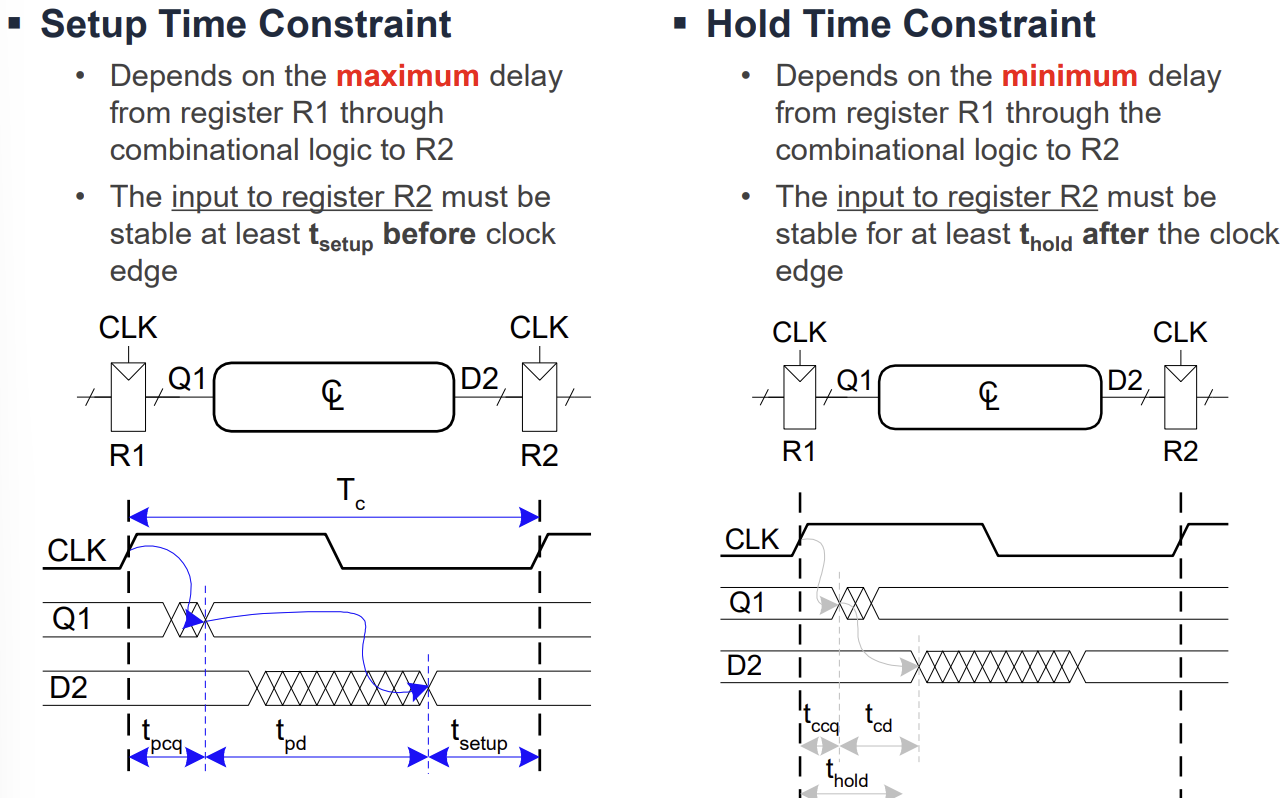
Setup Time Constraint는 클럭 주기()의 하한선을 결정한다. 여기서 는 조합 논리의 지연 시간이다. 이 조건이 만족되지 않으면 주파수를 낮춰야 한다.
Hold Time Constraint는 회로의 기능적 오류를 방지하기 위한 조건이다. 여기서 는 조합 논리의 최소 지연 시간이다. 만약 이 조건이 만족되지 않으면 주파수와 관계없이 회로가 오작동한다. 이를 해결하기 위해서는 짧은 경로에 버퍼(Buffer)를 추가하여 지연 시간을 늘려야 한다.
Single-Cycle Processor Limitations
Single-Cycle 구현은 모든 명령어를 한 사이클에 실행한다. 이는 설계가 간단하고 CPI(Cycles Per Instruction)가 1이라는 장점이 있다. 그러나 클럭 주기()가 가장 실행 시간이 긴 명령어(Critical Path, 주로 Load 명령어)에 맞춰 결정된다는 치명적인 단점이 있다.
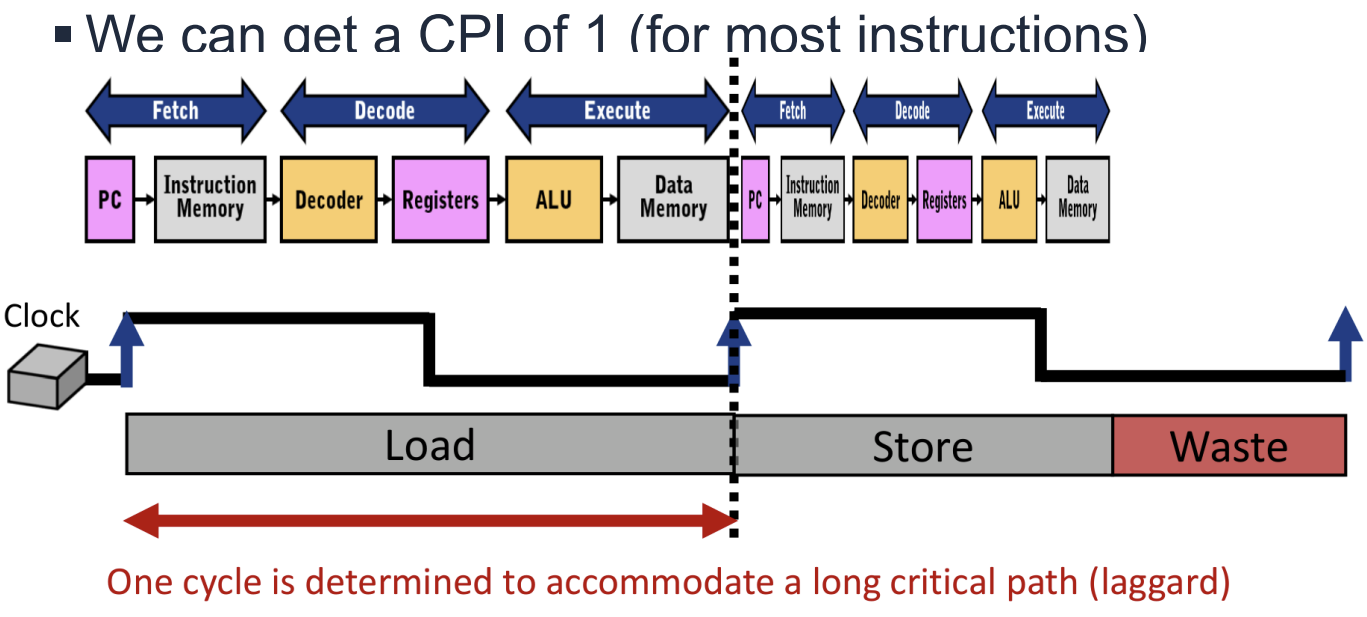
따라서 실행 시간이 짧은 명령어들도 불필요하게 긴 클럭 주기를 기다려야 하므로 시간 낭비(Waste)가 발생한다. 또한, Adder와 같은 하드웨어 자원을 명령어 실행 중 한 번만 사용할 수 있어 중복된 자원이 필요할 수 있다.
Multi-Cycle Datapath Approach
Single-Cycle의 비효율성을 극복하기 위해 Multi-Cycle 접근 방식이 도입되었다. 명령어를 더 작은 단계(Step)로 나누고, 각 단계가 한 클럭 사이클을 차지하도록 한다.
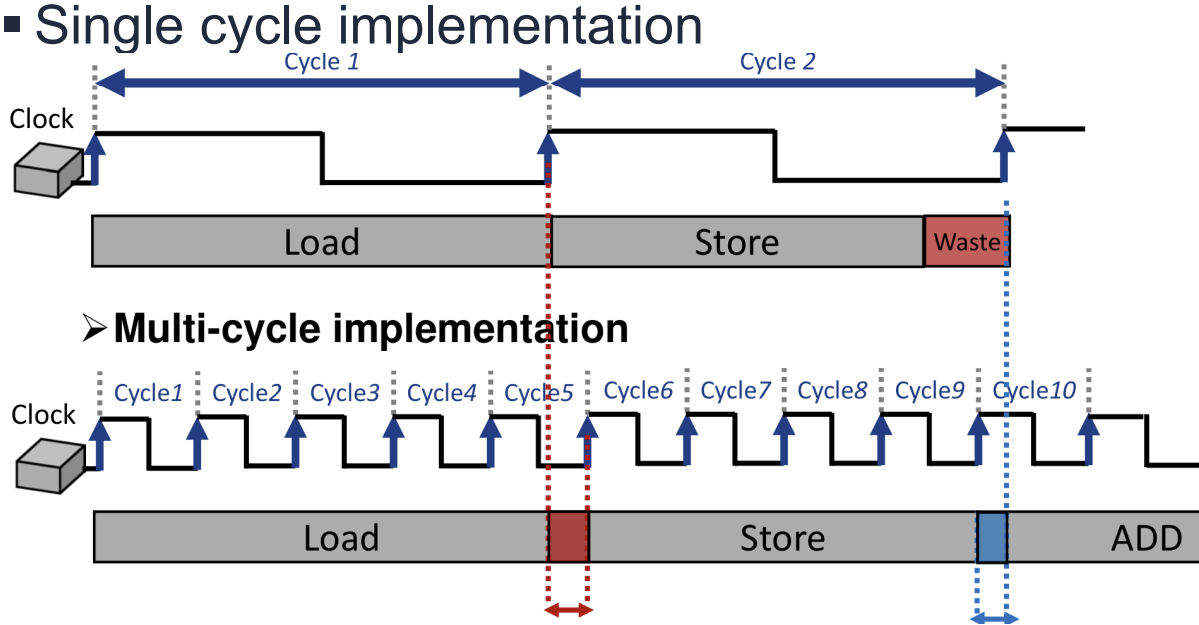
Multi-Cycle Datapath의 설계 원칙은 다음과 같다.
- 명령어를 IFetch, Decode, Execute, Memory, WriteBack 등의 작은 단계로 분할한다.
- 기능 유닛(Functional Unit)을 여러 사이클에 걸쳐 재사용함으로써 자원 중복을 줄인다.
- Control 신호는 FSM(Finite State Machine)을 사용하여 생성한다.
이 방식은 명령어마다 필요한 사이클 수가 다르므로(예: Load는 5사이클, Store는 4사이클), 짧은 명령어는 더 빨리 끝낼 수 있다. 하지만 FSM 기반의 제어 로직이 복잡해지는 단점이 있다.
Pipelining Concept
프로세서 성능을 나타내는 Iron Law는 다음과 같다.
성능을 높이기 위해서는 실행 명령어 수를 줄이거나, CPI를 낮추거나, 클럭 주파수를 높여야 한다. Pipelining은 Datapath를 여러 단계로 나누어 클럭 주기()를 줄이면서도, 여러 명령어를 중첩 실행(Overlap)하여 처리량(Throughput)을 높이는 기술이다. 이상적인 파이프라인 프로세서는 CPI를 1에 근접하게 유지하면서, Single-Cycle보다 훨씬 높은 클럭 주파수로 동작하는 것을 목표로 한다.
Timing Issues in Sequential Circuits
현대 프로세서 설계에서 Memory는 칩 면적의 상당 부분을 차지하며 매우 중요한 역할을 한다. Apple Silicon M4나 AMD Ryzen 5000 시리즈의 다이(Die) 사진을 보면 Cache와 같은 메모리 구조가 차지하는 비중이 매우 큼을 알 수 있다.

Sequential Circuit은 현재의 입력뿐만 아니라 과거의 입력 값(State)에도 의존하여 출력을 생성하는 회로이다. 정보를 저장하기 위한 Storage Elements로는 다음과 같은 것들이 있다.
- Flip-flops: 속도가 빠르고 데이터가 항상 가용하지만, 면적을 많이 차지하고 비싸다.
- SRAM (Static RAM): DRAM보다 빠르지만 비싸다. (1비트당 6개의 트랜지스터 소모)
- DRAM (Dynamic RAM): 가장 느리고 주기적인 Refresh가 필요하지만, 집적도가 높고 저렴하다.
Timing Constraints and Clocking
Digital System에서는 상태 업데이트를 동기화하기 위해 주기적인 Clock 신호를 사용한다. Sequential Circuit이 올바르게 동작하기 위해서는 엄격한 타이밍 제약 조건을 준수해야 한다.
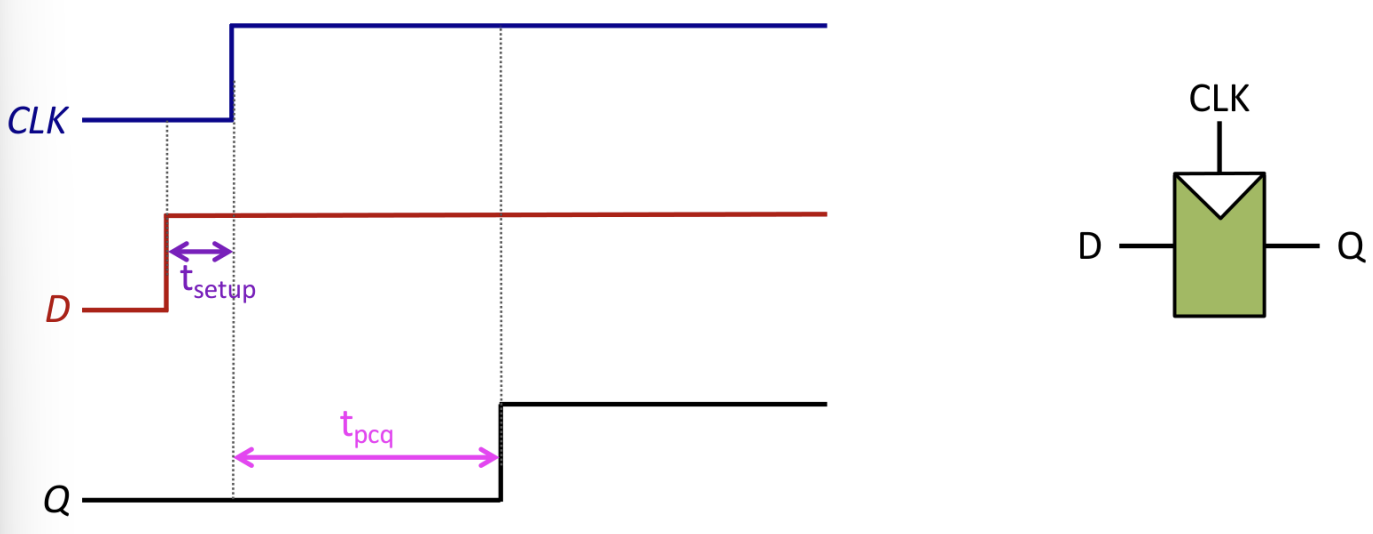
주요 타이밍 파라미터는 다음과 같다.
- Setup Time (): Clock의 Rising Edge 이전에 데이터가 안정화되어야 하는 최소 시간이다.
- Hold Time (): Clock의 Rising Edge 이후에도 데이터가 유지되어야 하는 최소 시간이다.
- Propagation Delay (): Clock Edge 이후 출력이 안정화되기까지 걸리는 시간이다.
- Aperture Time: Setup Time과 Hold Time의 합으로, 입력이 안정적으로 유지되어야 하는 전체 윈도우를 의미한다.
현대 공정에서는 Hold Time이 거의 0에 가깝다고 가정한다. 회로가 정상 동작하기 위한 최소 Clock Period ()는 다음과 같이 계산된다. 여기서 는 Combinational Logic의 지연 시간이다. 은 플립플롭에 의한 Sequencing Overhead로, 유용한 연산을 수행하는 시간이 아니라 상태를 저장하고 전달하는 데 소모되는 비용이다.
Finite State Machine (FSM)
FSM은 유한한 개수의 상태(State)를 가지며, 현재 상태와 입력에 따라 다음 상태와 출력을 결정하는 모델이다. CPU의 Control Unit 등 많은 논리 회로가 FSM으로 모델링된다. FSM은 매 클럭 엣지마다 Next State Logic을 통해 계산된 다음 상태로 전이한다.
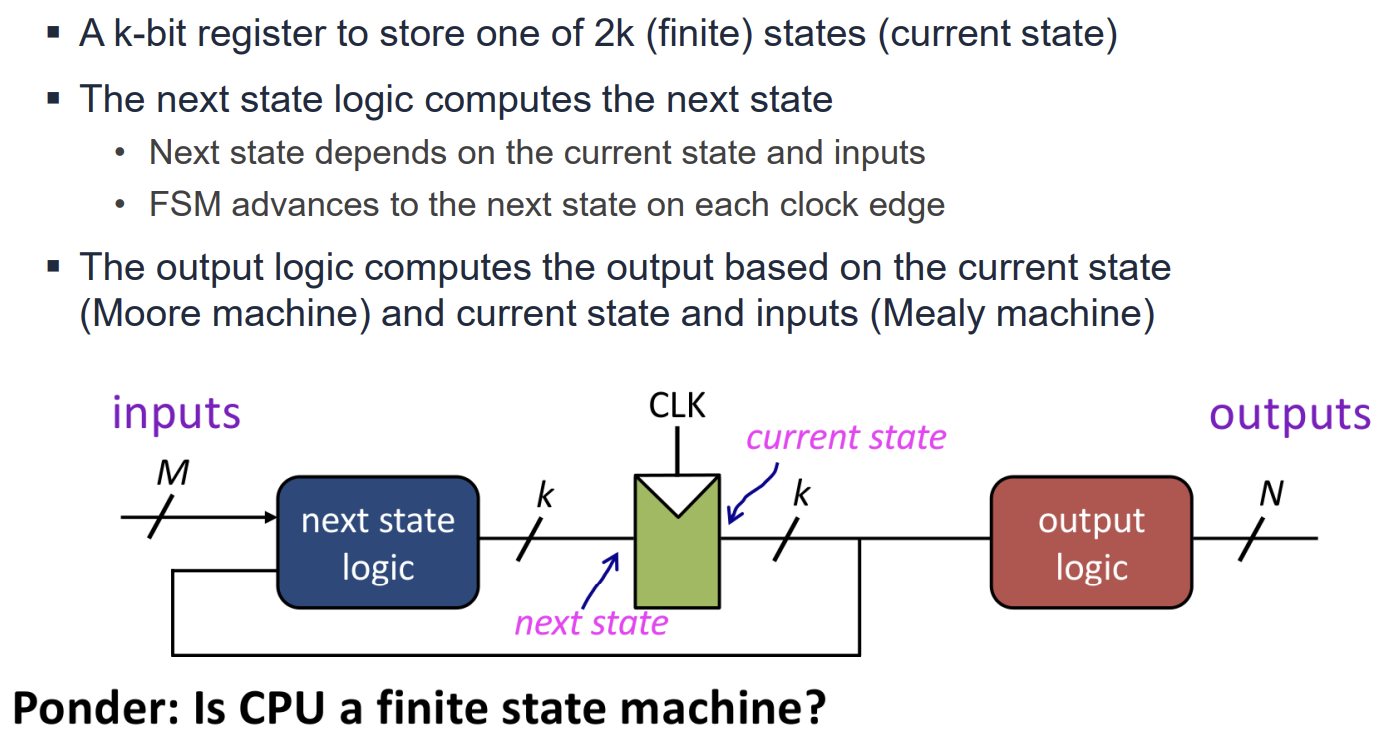
Performance Metrics and Analysis
컴퓨터 구조에서 성능(Performance)은 실행 시간의 역수로 정의된다. 성능을 분석할 때 Latency와 Throughput을 구별하는 것이 중요하다.
- Latency: 하나의 작업이 시작해서 끝날 때까지 걸리는 시간이다.
- Throughput: 단위 시간당 처리되는 작업의 수이다.
Little's Law는 시스템의 상태가 안정적일 때 다음 관계가 성립함을 보여준다. 여기서 L은 시스템 내의 작업 수, 는 도착률(Throughput), W는 대기 시간(Latency)이다.
프로세서 성능의 Iron Law는 다음과 같다. 성능을 향상시키기 위해서는 명령어 수를 줄이거나, CPI(Cycles Per Instruction)를 낮추거나, Clock Cycle Time을 줄여야 한다.
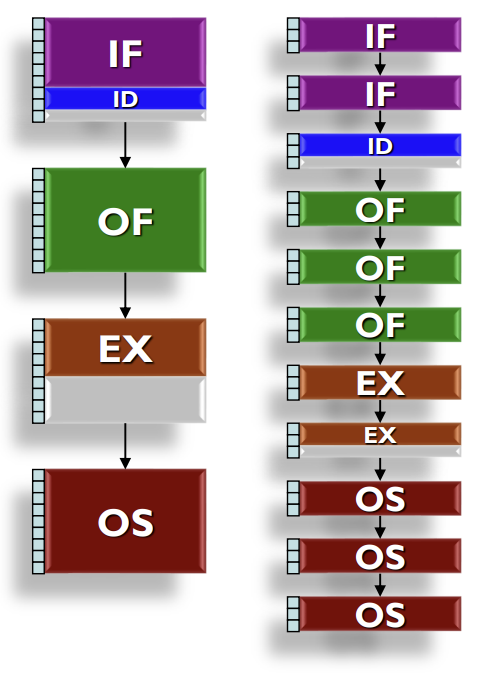
Pipelining Principles
Pipelining은 Throughput을 높이기 위해 사용하는 Temporal Parallelism 기법이다. 전체 작업을 균일한 지연 시간을 가진 여러 단계(Stage)로 나누고, 각 단계가 동시에 서로 다른 작업을 처리하도록 한다.
이상적인 파이프라인에서 개의 스테이지가 있을 때 Speedup은 에 근접한다. 하지만 실제로는 레지스터 추가에 따른 지연()과 비용()이 발생한다. Cost/Performance Trade-off 분석에 따르면, 비용 대비 성능을 최적화하는 최적의 파이프라인 깊이()는 다음과 같이 유도된다. (G: Logic Gate Cost, T: Logic Delay, L: Latch Cost, S: Latch Delay)
RISC Instruction Pipelining
RISC 프로세서는 일반적으로 5단계 파이프라인을 사용한다.
- Instruction Fetch (IF)
- Instruction Decode (ID)
- Operand Fetch / Register Read (OF/RF)
- Execution / ALU (EX)
- Operand Store / Write Back (OS/WB)
파이프라인을 적용하면 각 명령어의 실행 시간(Latency)은 늘어날 수 있지만(Overhead 때문), 전체적인 명령어 처리량(Throughput)은 크게 증가한다. 명령어의 종류(R-type, Load, Store 등)에 따라 사용하는 스테이지가 다르며, 사용하지 않는 스테이지는 유휴 상태가 된다. 이를 External Fragmentation이라 한다.
결론적으로 프로세서의 성능이 향상되는 이유는 세 가지로 요약된다.
- Wider: 병렬 처리를 통해 사이클당 더 많은 명령어를 처리한다 (Instruction Level Parallelism).
- Deeper: 파이프라인 깊이를 늘려 클럭 주파수를 높인다.
- Faster: 트랜지스터 성능 향상(Moore's Law)으로 스위칭 속도가 빨라진다.
General Idea of Pipelining and Performance Metrics
Digital Circuit의 속도와 성능을 평가하기 위해 Latency와 Throughput이라는 두 가지 주요 지표를 사용한다. Latency는 입력이 도착한 후 출력이 생성되기까지 걸리는 시간(Propagation delay)을 의미하며, Throughput은 단위 시간당 처리되는 입력 그룹(Task)의 수를 의미한다. Throughput을 높이기 위한 핵심 기술은 Parallelism이다.
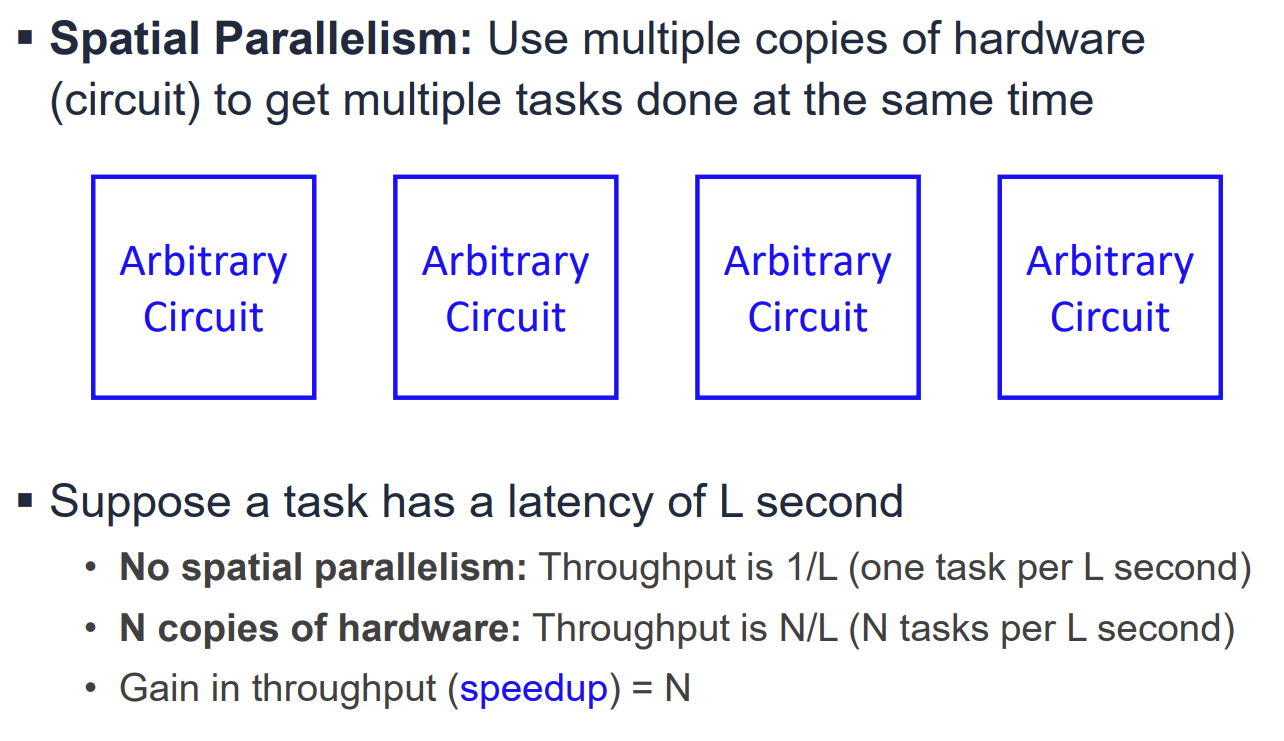
Parallelism은 크게 두 가지로 나뉜다.
- Spatial Parallelism: 하드웨어의 복사본을 여러 개 사용하여 동시에 여러 작업을 수행한다. Throughput은 하드웨어 수(N)만큼 증가하지만, Latency는 줄어들지 않는다.
- Temporal Parallelism (Pipelining): 하나의 회로를 여러 Stage로 나누어 각 작업이 순차적으로 모든 Stage를 통과하게 한다. 여러 작업이 서로 다른 Stage에 동시에 존재함으로써 Throughput을 높인다.
Pipelining Performance and Cost Models
이상적인 Pipelining에서는 전체 Latency 을 개의 Stage로 나누면 Throughput은 이 된다. 하지만 실제 하드웨어에서는 Stage 간에 데이터를 저장하기 위한 Latch(Pipeline Register)가 필요하며, 이에 따른 지연 시간()과 비용()이 발생한다.
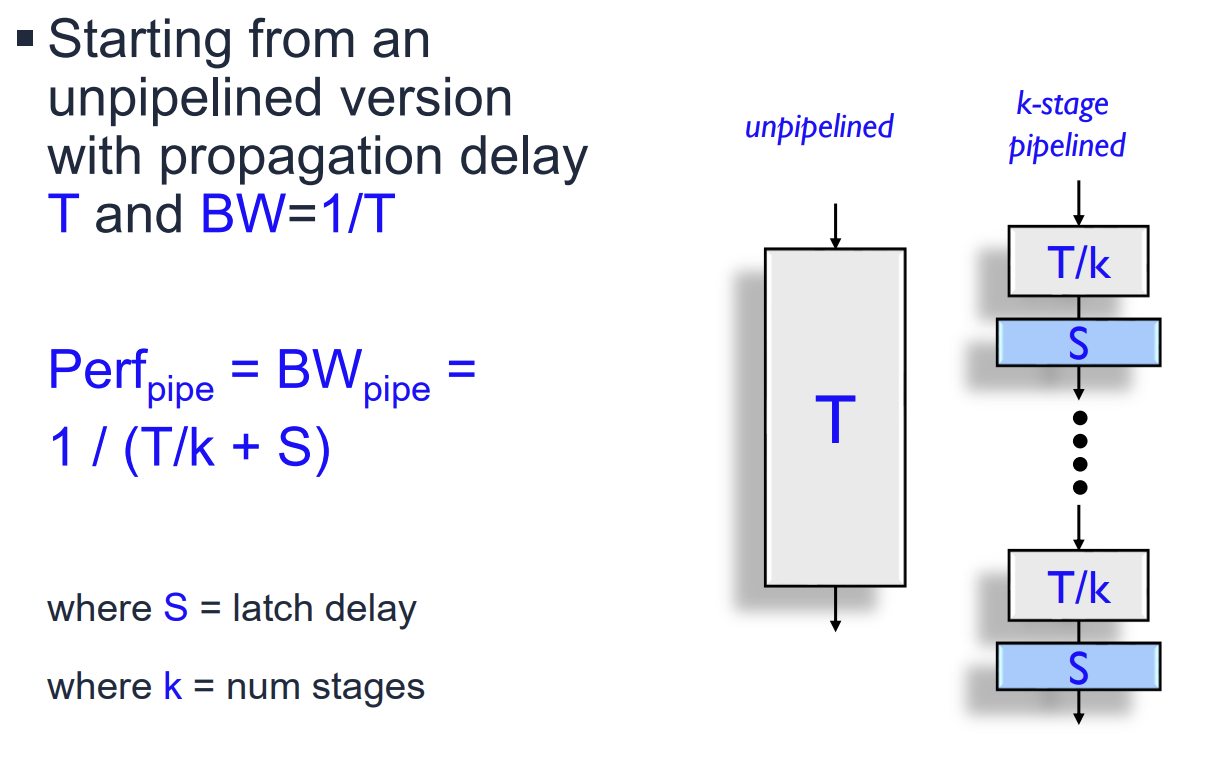
Pipelined Performance Model은 다음과 같다. 여기서 는 Non-pipelined delay, 는 Stage 수, 는 Latch delay이다.
Hardware Cost Model은 다음과 같다. 여기서 는 Non-pipelined gate cost, 은 Latch cost이다.
Cost/Performance Trade-off and Optimal Depth
파이프라인의 깊이()가 깊어질수록 Throughput은 증가하지만 비용(Cost)과 Latch Overhead도 증가한다. 따라서 비용 대비 성능(Cost/Performance Ratio, C/P)을 최적화하는 지점을 찾아야 한다.
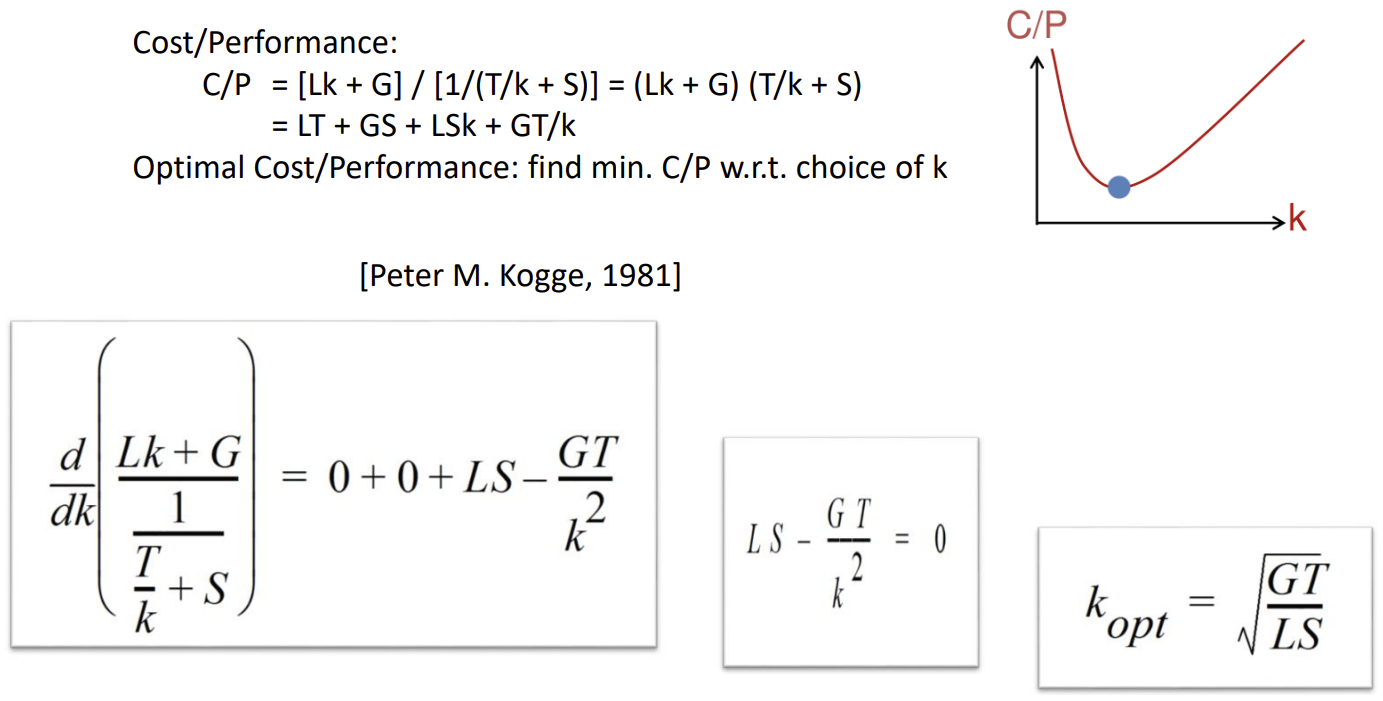
C/P Ratio를 에 대해 미분하여 0이 되는 지점을 찾으면 최적의 파이프라인 깊이 를 구할 수 있다. 이 식은 Logic Gate의 비용()과 지연()이 클수록, 그리고 Latch의 비용()과 지연()이 작을수록 더 깊은 파이프라인이 유리함을 보여준다.
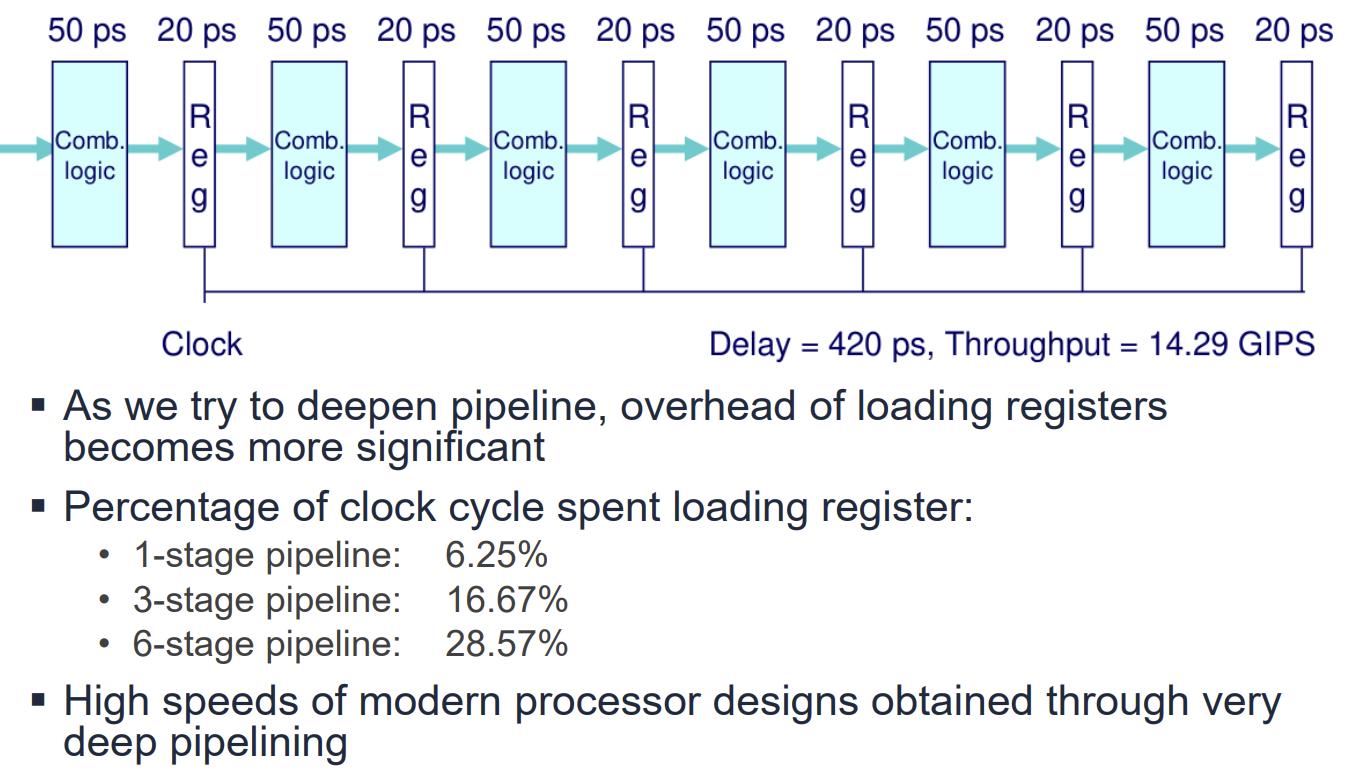
Limitations and Real-world Examples
파이프라인 깊이를 무한정 늘릴 수는 없다. 파이프라인이 깊어질수록 클럭 주기 내에서 유용한 연산을 수행하는 시간 대비 레지스터 로딩(Overhead)이 차지하는 비중이 커지기 때문이다. Integer Multiplier 설계 예시를 보면, Stage 수가 늘어날수록 Delay는 감소하고 Throughput은 증가하지만, 면적(Area)은 급격히 증가함을 알 수 있다.
Instruction Dependencies and Hazards
파이프라인 프로세서에서는 여러 명령어가 동시에 실행되므로 명령어 간의 의존성(Dependencies)이 문제가 된다. 주요 의존성 유형은 다음과 같다.
- True Data Dependency (RAW: Read-After-Write): 이전 명령어의 결과를 다음 명령어가 읽어야 하는 경우.
- Anti-dependency (WAR: Write-After-Read): 이전 명령어가 값을 읽기 전에 다음 명령어가 값을 써버리는 경우.
- Output Dependency (WAW: Write-After-Write): 명령어들의 쓰기 순서가 바뀌어 최종 결과가 잘못되는 경우.
이러한 의존성으로 인해 프로그램의 실행 순서가 위배될 가능성을 Pipeline Hazard라고 한다. Hazard를 해결하기 위해 Static Method(컴파일 타임 소프트웨어 해결)와 Dynamic Method(런타임 하드웨어 해결, Interlock)가 사용된다.
Pipeline Register Modes
하드웨어적으로 Hazard를 해결하기 위해 Pipeline Register는 다음과 같은 동작 모드를 가진다.
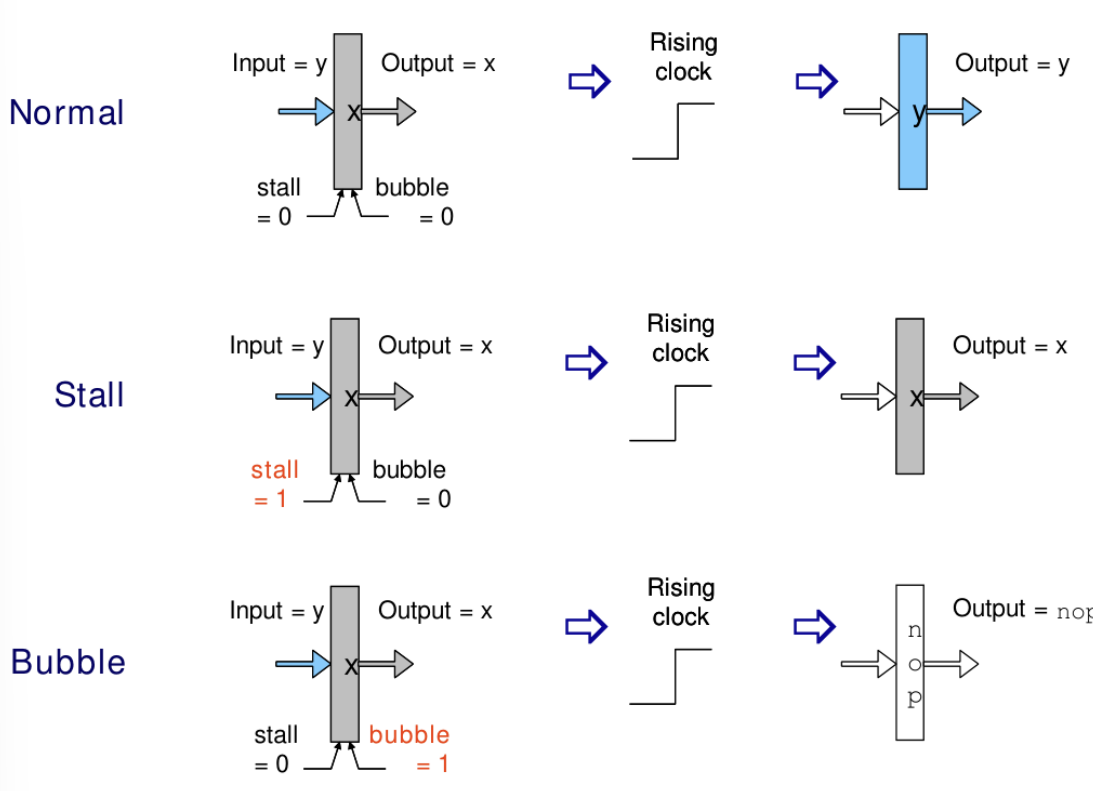
- Normal: 입력을 출력으로 전달한다.
- Stall: 출력을 유지(Hold)하여 파이프라인의 흐름을 멈춘다. 이전 단계의 값은 보존된다.
- Bubble: 출력으로 NOP(No Operation)을 내보내어 파이프라인에 빈 공간을 만든다.
Instruction Timing and Performance Analysis
RISC-V Single-Cycle 프로세서의 성능을 분석하기 위해 각 단계별 지연 시간을 고려한다. 예를 들어 Instruction Fetch(IF) 200ps, Decode(ID) 100ps, Execution(EX) 200ps, Memory(MEM) 200ps, Write-Back(WB) 100ps라고 가정할 때, 가장 긴 경로를 가진 명령어(Load Word, lw)는 총 800ps가 소요된다. 이는 프로세서의 최대 클럭 주파수를 1.25GHz ()로 제한한다.
성능을 향상시킨다는 것은 단순히 하나의 작업(Job)을 빨리 끝내는 것(Latency 개선)뿐만 아니라, 단위 시간당 더 많은 작업을 처리하는 것(Throughput 개선)을 의미할 수 있다.
Performance Evaluation Analogies
성능 지표인 Latency와 Throughput의 차이를 설명하기 위해 운송 수단과 빨래의 비유를 사용한다.
- Transportation Analogy: 스포츠카는 승객 용량은 적지만 이동 속도가 빨라 Latency가 낮다. 반면 버스는 이동 속도는 느리지만 승객 용량이 커서 Throughput이 높다. 컴퓨터 시스템에서 프로그램 실행 시간은 이동 시간(Trip Time)에, 처리량은 승객 수송 능력에 해당한다. 전력(Power)보다는 작업당 에너지(Energy per task)가 더 적절한 효율성 지표이다.
- Laundry Analogy: 세탁(30분)과 건조(60분) 작업을 순차적으로 수행하면 2회 분량에 3시간이 걸린다. 하지만 파이프라이닝을 적용하여 세탁기가 돌아가는 동안 건조기를 동시에 사용하면 전체 소요 시간을 단축할 수 있다.
Sandwich Shop Analogy for Pipelining
KNU 샌드위치 가게 예시를 통해 Sequential 처리와 Pipelined 처리의 차이를 명확히 보여준다. 샌드위치 제조 과정을 4단계(A, B, C, D)로 나누고 각 단계가 1분씩 걸린다고 가정한다.
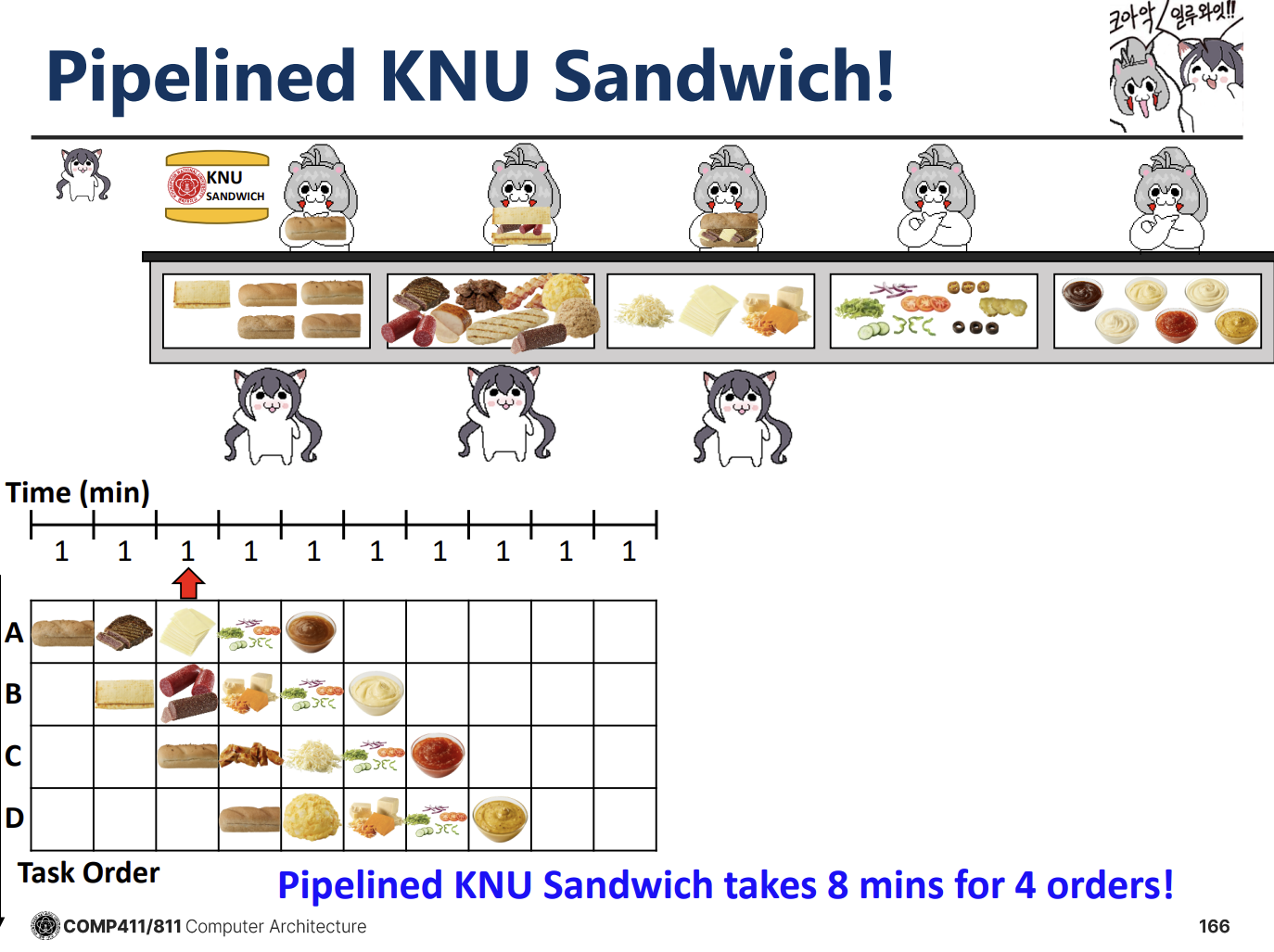 (ㅋㅋㅋ 유쾌하시네)
(ㅋㅋㅋ 유쾌하시네)
- Single-Cycle Sequential: 한 명의 직원이 샌드위치 하나를 처음부터 끝까지 만든 후 다음 주문을 받는다. 4개의 샌드위치를 만드는 데 16분이 소요된다. 자원 활용도가 매우 낮다.
- Pipelined Execution: 각 단계별로 전담 직원을 두고, 하나의 단계가 끝나면 즉시 다음 주문의 해당 단계를 처리한다. 첫 번째 샌드위치는 4분(Latency)이 걸리지만, 그 이후에는 1분마다 하나씩 완성된다. 결과적으로 4개의 샌드위치를 만드는 데 8분이 소요된다.
Throughput vs. Latency Trade-off
파이프라이닝은 개별 작업의 Latency를 줄여주지는 않는다. 오히려 단계 간 오버헤드나 파이프라인을 채우는 시간 때문에 개별 작업의 Latency는 Single-Cycle보다 약간 늘어날 수 있다 (예: 4분 -> 5분). 하지만 전체 시스템의 Throughput(Bandwidth)은 비약적으로 상승한다. 샌드위치 예시에서 Single-Cycle의 대역폭은 분당 0.25개였으나, Pipelined 방식에서는 분당 1개(Peak Bandwidth)로 증가한다.
Limitations and Advanced Concepts
파이프라인의 속도는 가장 느린 단계(Bottleneck)에 의해 제한된다. 만약 특정 단계의 소요 시간이 길어지면 전체 파이프라인의 속도가 그에 맞춰 느려진다. 성능을 더 높이기 위해 Superscalar 방식(Multi-core 비유)을 사용할 수 있다. 이는 여러 개의 파이프라인을 병렬로 가동하여 Throughput을 배로 늘리는 방식이다
RISC-V 5-Stage Pipelined Datapath
RISC-V 아키텍처의 5단계 파이프라인(5-Stage Pipeline)은 명령어 처리 과정을 5개의 독립적인 단계로 나누어 동시에 여러 명령어를 처리하는 기법이다. Single-Cycle Datapath에서는 모든 명령어가 한 클럭 사이클 내에 완료되어야 하므로 클럭 주기가 가장 느린 명령어에 맞춰져야 하는 비효율성이 있었다. Pipelined Datapath는 각 단계를 분리하여 클럭 주기를 단축하고 처리량(Throughput)을 높인다.
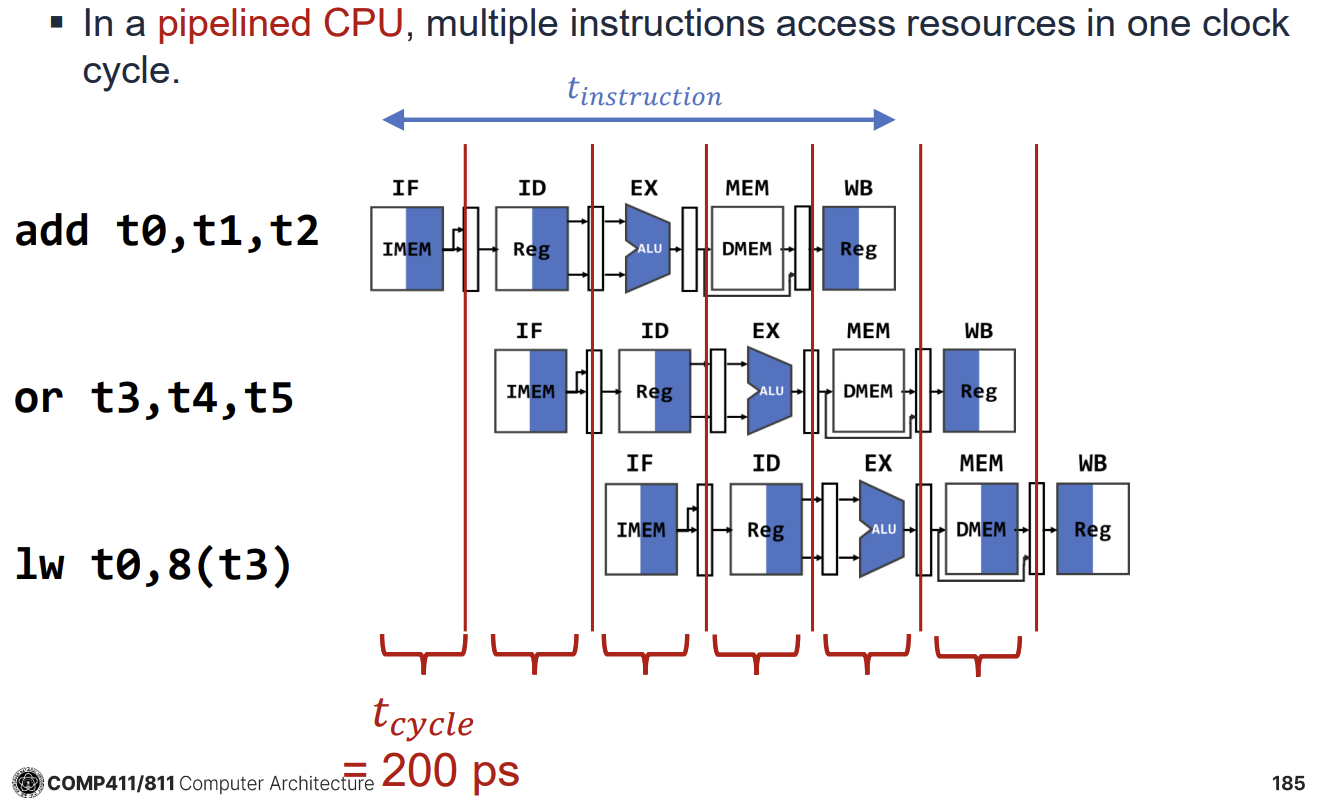
5개의 단계는 다음과 같다.
- IF (Instruction Fetch): 메모리에서 명령어를 가져온다.
- ID (Instruction Decode): 명령어를 해석하고 레지스터 값을 읽는다.
- EX (Execute): ALU 연산을 수행하거나 주소를 계산한다.
- MEM (Memory Access): 데이터 메모리에 접근한다(Load/Store).
- WB (Write Back): 결과를 레지스터에 기록한다.
Single-Cycle에서는 라면 클럭 주기()도 800ps여야 하지만, Pipelined 방식에서는 가장 느린 단계의 지연 시간(예: 200ps)에 맞춰 클럭 주기를 200ps로 줄일 수 있다. 결과적으로 처리량은 최대 4배까지 증가할 수 있다.
Pipeline Registers
각 단계 사이에는 파이프라인 레지스터(Pipeline Registers)가 존재하여 이전 단계의 결과와 제어 신호(Control Signals)를 다음 단계로 전달한다. 이는 각 단계가 독립적으로 동작하도록 하며, 동시에 서로 다른 명령어의 데이터를 처리할 수 있게 한다.
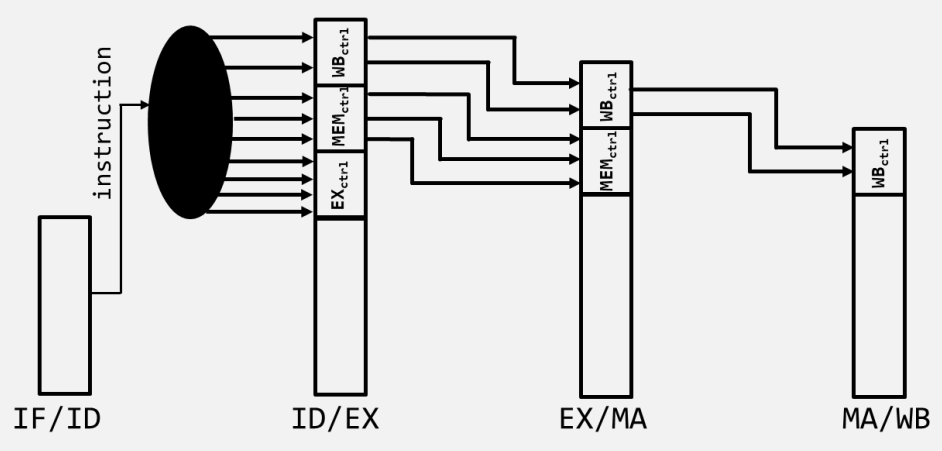
주요 파이프라인 레지스터는 다음과 같다.
- IF/ID: PC 값과 인출된 명령어(Instruction)를 저장한다.
- ID/EX: 읽어온 레지스터 값(rs1, rs2), 확장된 즉시값(Immediate), 제어 신호 등을 저장한다.
- EX/MEM: ALU 연산 결과, 메모리에 쓸 데이터(rs2), 목적지 레지스터 번호(rd) 등을 저장한다.
- MEM/WB: 메모리에서 읽은 데이터, ALU 결과, 목적지 레지스터 번호 등을 저장한다.
파이프라인 레지스터는 데이터뿐만 아니라 해당 명령어가 이후 단계에서 사용할 제어 신호(Control Signals)들도 함께 전달해야 한다. 예를 들어 MemWrite 신호는 MEM 단계에서 필요하므로 ID 단계에서 생성되어 EX 단계를 거쳐 MEM 단계까지 전달되어야 한다.
Performance Analysis and Limitations
Pipelining을 통해 이상적으로는 를 달성할 수 있다. 5단계 파이프라인의 경우 최대 5배의 속도 향상이 가능하지만, 실제로는 다음과 같은 이유로 그보다 낮다.
- Pipeline Register Overhead: 파이프라인 레지스터 자체의 지연 시간(Setup time, Propagation delay)이 추가된다.
- Unbalanced Stages: 각 단계의 소요 시간이 균일하지 않으면 가장 느린 단계가 클럭 주기를 결정하므로 효율이 떨어진다.
- Hazards: 명령어 간의 의존성(Dependency)으로 인해 파이프라인이 멈추는(Stall) 상황이 발생하여 CPI(Cycles Per Instruction)가 1보다 커진다.
Pipeline CPI는 다음과 같이 계산된다. 이상적인 CPI는 1이지만, 각종 Hazard로 인한 Stall 때문에 실제 CPI는 1보다 커지게 된다.
Upcoming Topics: Hazards
강의의 다음 부분에서는 파이프라인의 성능을 저하시키는 주요 요인인 Hazard에 대해 다룰 예정이다.
- Structural Hazards: 하드웨어 자원 충돌로 인한 문제.
- Data Hazards: 데이터 의존성으로 인한 문제 (Forwarding으로 해결 가능).
- Control Hazards: 분기 명령어 등으로 인한 흐름 제어 문제.
Pipeline Hazards Overview
파이프라인 프로세서에서 Hazard는 예정된 명령어가 적절한 클럭 사이클에 실행되지 못하는 상황을 말한다. Hazard는 크게 세 가지 유형으로 분류된다.
- Structural Hazard: 하드웨어 자원이 부족하여 여러 명령어가 동시에 같은 자원에 접근하려 할 때 발생한다. (Resource Conflict)
- Data Hazard: 명령어 간의 데이터 의존성(Data Dependency)으로 인해, 이전 명령어의 데이터 읽기/쓰기가 완료될 때까지 기다려야 하는 상황이다.
- Control Hazard: 분기(Branch) 명령어 등으로 인해 실행 흐름이 변경되어, 다음에 실행할 명령어가 결정되지 않은 상태에서 발생한다.
Structural Hazards and Solutions
Structural Hazard는 물리적 자원(메모리, 레지스터 포트 등)이 부족할 때 발생한다. 예를 들어, Instruction Fetch(IF) 단계와 Memory Access(MEM) 단계에서 동시에 메모리에 접근하려고 할 때, 메모리가 하나뿐이라면 충돌이 발생한다.
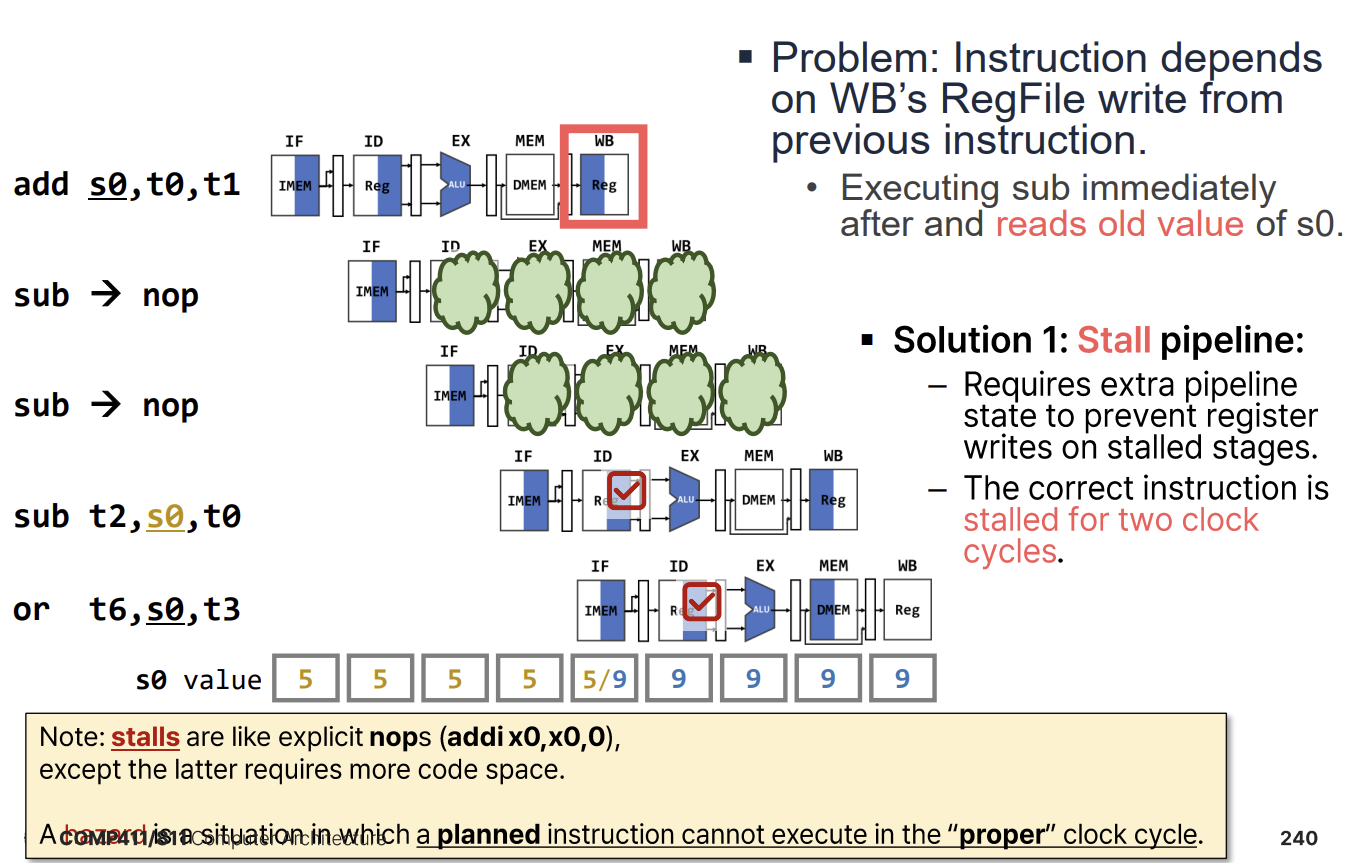
- Solution 1: Stalling (Interlock) 하드웨어적으로 Hazard를 감지하여 파이프라인을 멈춘다(Stall). 제어 신호를 조작하여 PC와 IF/ID 레지스터 업데이트를 막고, ID/EX 단계에 NOP(No Operation)을 삽입한다. 이는 소프트웨어 호환성을 유지하지만 성능 저하를 일으킨다.
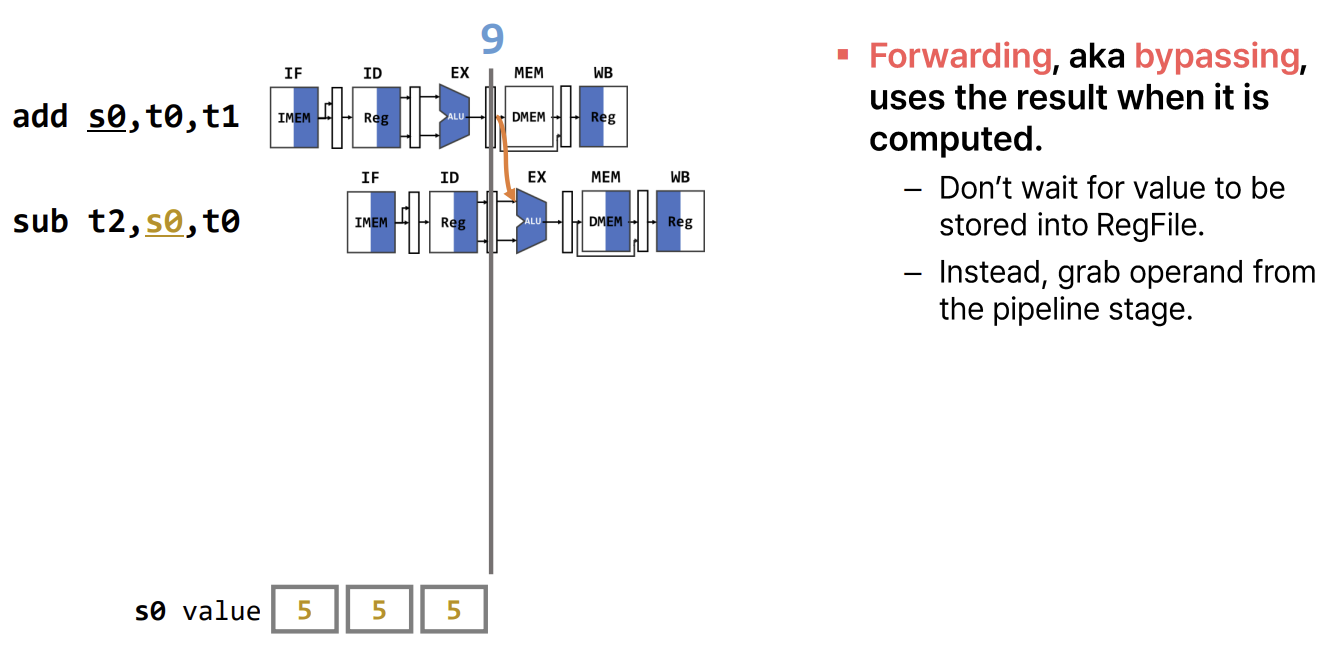
- Solution 2: Forwarding (Bypassing)
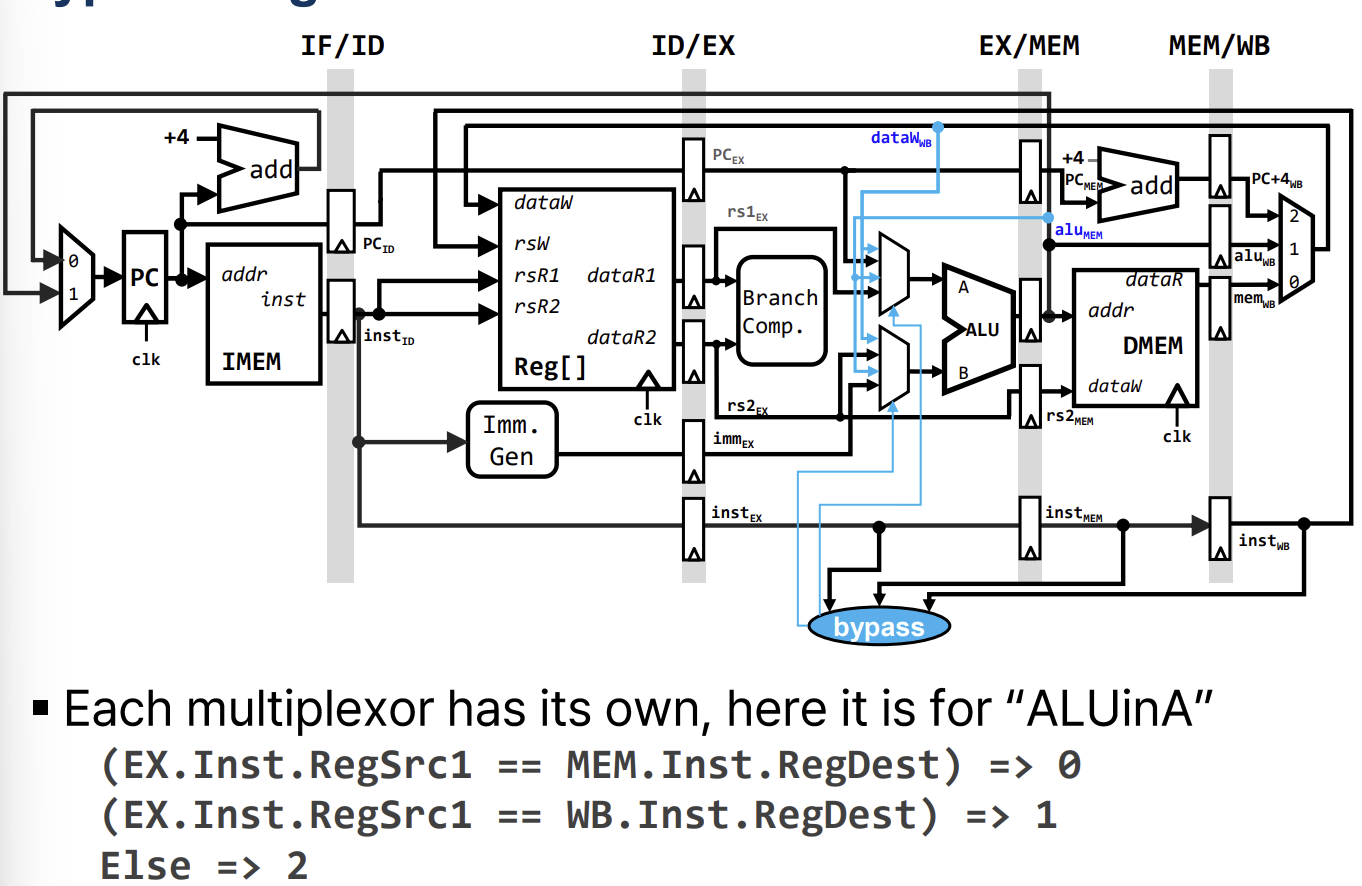
데이터가 레지스터 파일에 기록될 때까지 기다리지 않고, 파이프라인 내부의 중간 결과(Pipeline Register에 저장된 값)를 직접 필요한 단계로 전달한다.
- EX to EX Forwarding (MX Bypass): 직전 명령어의 ALU 결과를 현재 명령어의 ALU 입력으로 전달한다.
- MEM to EX Forwarding (WX Bypass): 2사이클 전 명령어의 결과(현재 WB 단계)를 현재 명령어의 ALU 입력으로 전달한다.
3. Load Data Hazard (Load-Use Hazard) Load 명령어는 MEM 단계가 끝나야 데이터가 준비되므로, 바로 다음 명령어가 그 데이터를 필요로 하면 Forwarding만으로는 해결할 수 없다. (이 부분은 다음 강의 주제인 Data Hazard III에서 다룸)
Pipeline Control and Stall Logic
Stall과 Bypass는 상호보완적이다. Bypass가 가능한 경우에는 Bypass를 통해 성능 저하 없이 Hazard를 해결하고, Bypass가 불가능한 경우(예: Load-Use Hazard)에는 Stall을 사용하여 파이프라인을 멈춰야 한다. Stall Logic은 Hazard Detection Unit에 의해 제어되며, 파이프라인 레지스터의 쓰기 신호(WE)와 제어 신호 멀티플렉서를 조작하여 NOP을 삽입한다.
Incomplete Hazard Prevention
지금까지 다룬 Bypass(Forwarding)와 Load-Use Stall만으로는 모든 Data Hazard를 해결할 수 없다. load 명령어 바로 뒤에 의존성이 있는 store 명령어가 오는 경우가 대표적이다.
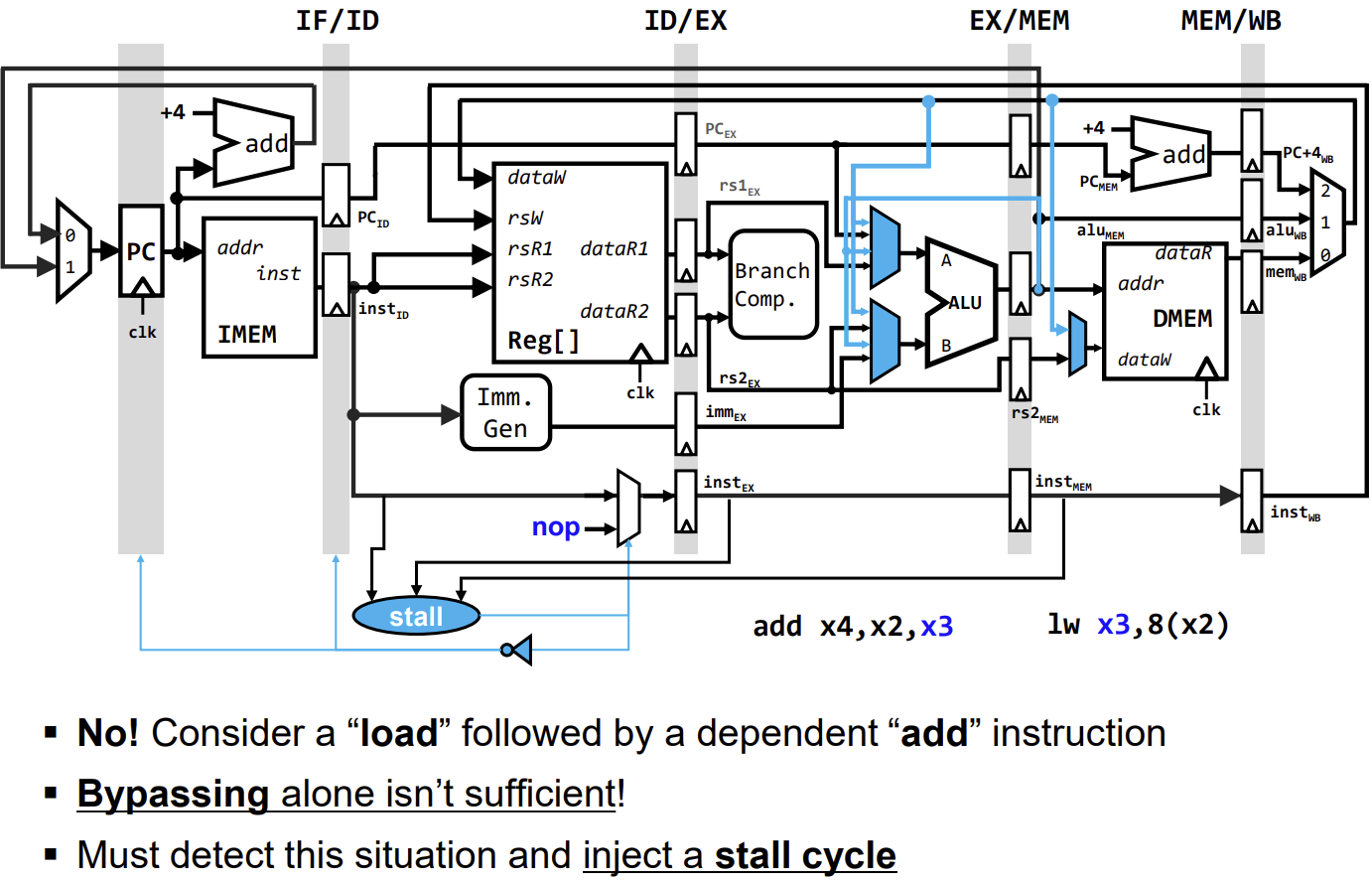 예를 들어,
예를 들어, lw x3, 8(x2) 다음에 add x4, x2, x3가 오는 경우, lw는 MEM 단계가 끝나야 x3 값을 사용할 수 있지만, add는 EX 단계에서 x3 값을 필요로 한다. Forwarding은 시간을 거슬러 데이터를 보낼 수 없으므로, 이 경우에는 반드시 Stall을 사용하여 파이프라인을 멈춰야 한다.
Forwarding Limitations
Forwarding은 데이터가 계산된 시점(Producer)이 데이터를 필요로 하는 시점(Consumer)보다 앞서거나 같을 때만 가능하다.
- Forwarding 가능: EX 단계의 결과(ALU Output)를 다음 명령어의 EX 단계 입력으로 전달하는 경우.
- Forwarding 불가능: MEM 단계에서 데이터를 읽어오는 Load 명령어의 결과를 바로 다음 명령어의 EX 단계 입력으로 전달해야 하는 경우 (Load-Use Hazard). 이 경우 데이터가 준비되는 시점이 필요한 시점보다 늦기 때문에 Forwarding만으로는 해결이 불가능하다.
Load-Use Data Hazard Solutions
Load 명령어 직후에 의존성이 있는 명령어(ALU 연산 등)가 오는 경우를 Load-Use Hazard라고 한다. 이를 해결하기 위해 두 가지 방법이 있다.
-
Hardware Interlock (Stall): 하드웨어가 Hazard를 감지하고 파이프라인을 1사이클 멈춘다(Stall).
- Hazard Detection Unit이 ID 단계에 있는 명령어의 소스 레지스터와 EX 단계에 있는 Load 명령어의 목적지 레지스터를 비교한다.
- 일치할 경우, PC와 IF/ID 파이프라인 레지스터의 업데이트를 막고(Disable Write), ID/EX 레지스터에 NOP(No Operation)을 삽입하여 뒷 명령어의 진행을 1사이클 늦춘다.
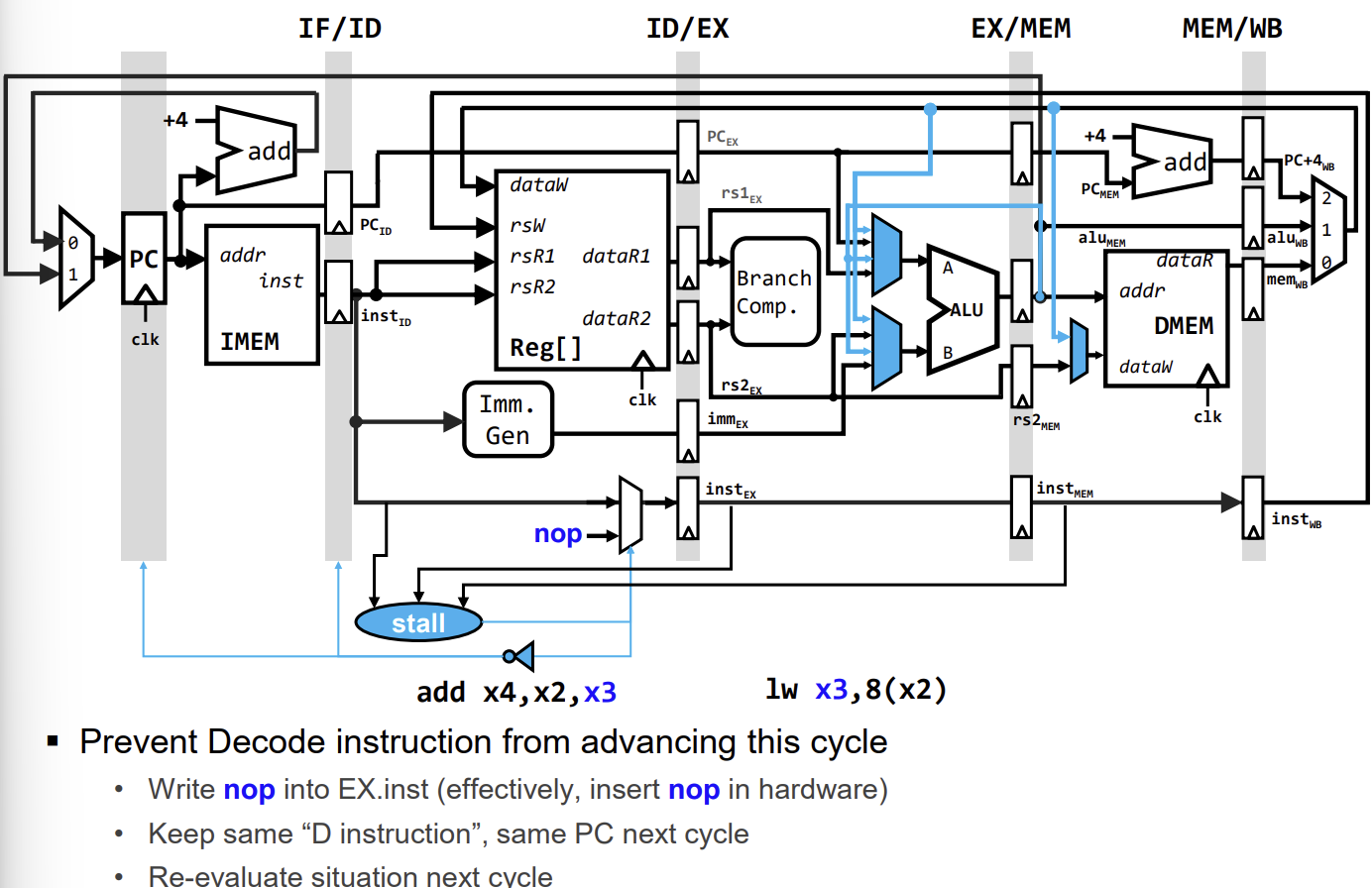
-
Code Scheduling (Software Solution): 컴파일러가 명령어 순서를 재배치하여 Hazard를 피한다.
- Load 명령어와 이를 사용하는 명령어 사이에 의존성이 없는 다른 명령어를 삽입하여 거리를 둔다.
- NOP을 삽입하는 것보다 유용한 명령어를 채워 넣는 것이 성능상 유리하다.

Control Hazards
Control Hazard는 분기(Branch)나 점프(Jump) 명령어에 의해 발생한다. 파이프라인 프로세서는 분기 여부(Taken/Not Taken)와 목적지 주소(Target Address)가 결정되기 전에 미리 다음 명령어를 인출(Fetch)하기 때문이다.
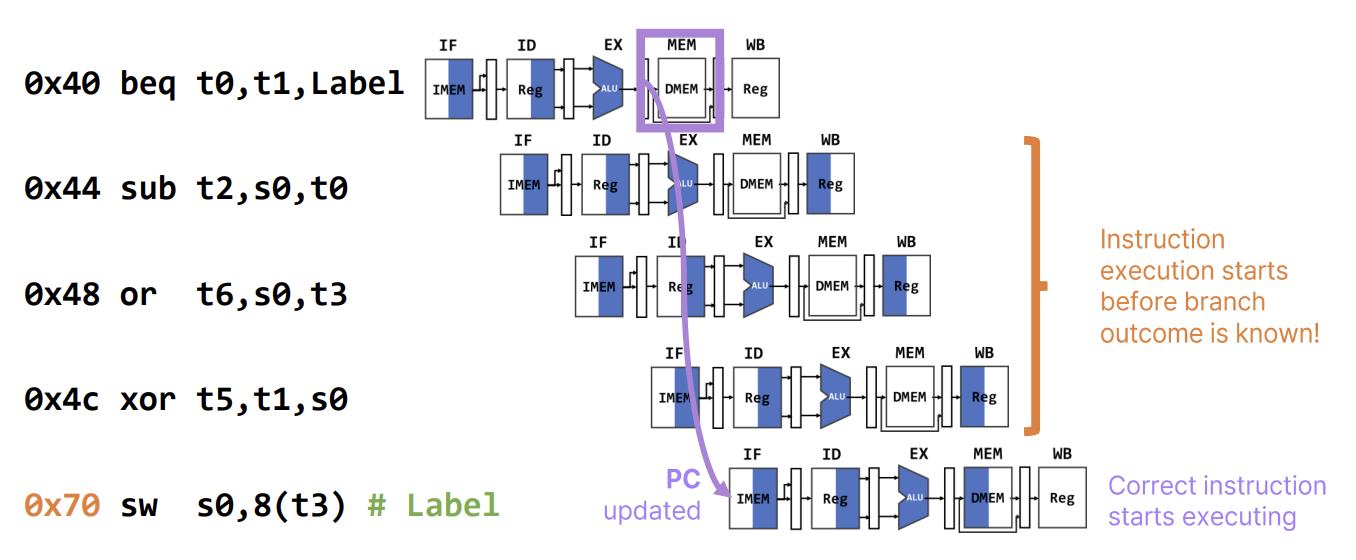
- 문제점: 분기가 발생하면(Taken), 이미 파이프라인에 들어온 다음 명령어들은 잘못된 명령어들이므로 실행해서는 안 된다.
- 해결책 1 (Flush): 분기가 확정되는 순간(EX 또는 MEM 단계), 파이프라인에 있는 잘못된 명령어들을 NOP으로 바꾸어 제거(Flush)한다. RISC-V 5단계 파이프라인에서는 분기 확인이 MEM 단계에서 이루어진다면 3사이클의 페널티가 발생한다.
- 해결책 2 (Branch Prediction): 분기 여부를 미리 예측하여 파이프라인을 채운다.
- Static Prediction: 무조건 "분기하지 않음(Not Taken)"으로 가정하고 순차적으로 명령어를 인출한다. 예측이 틀리면 Flush한다.
- Dynamic Prediction: 과거의 실행 이력을 바탕으로 분기 여부를 동적으로 예측한다 (BHT, BTB 등 사용).
Branch Prediction Strategy
분기 예측의 정확도를 높이는 것은 파이프라인 성능에 매우 중요하다.
- Naive Predictor: 항상 분기가 일어나지 않는다고 가정한다. (Always Not Taken)
- Speculative Execution: 예측된 경로의 명령어를 미리 실행한다. 예측이 맞으면 성능 이득을 얻고, 틀리면 실행을 취소(Rollback)하고 올바른 경로로 다시 실행한다.
파이프라인이 깊어질수록(Deep Pipeline), 분기 페널티(Misprediction Penalty)가 커지므로 정교한 분기 예측 기술이 더욱 중요해진다.
Pipelining: Clock Frequency vs. IPC
Pipelining의 단계(Stage) 수를 늘리는 것에는 장단점이 있다.
- 장점: Clock Frequency가 증가한다 (Clock Period 감소).
- 단점:
- Register Overhead와 Imbalanced Stages로 인해 Frequency가 정확히 비례해서 증가하지 않는다.
- CPI가 증가한다 (Hazard 증가, Branch Penalty 증가).
- 메모리 Latency가 상대적으로 높아진다.
결과적으로 일정 수준 이상 깊은 파이프라이닝은 성능을 저하시킬 수 있다. 최적의 파이프라인 깊이는 프로그램과 기술에 따라 다르다.
Summary: Pipeline Hazards
파이프라인 성능을 저해하는 Hazard는 다음과 같다.
- Structural Hazards: 하드웨어 자원 충돌.
- Data Hazards: 데이터 의존성 문제.
- 해결책: Stalling, Forwarding, Scheduling.
- Control Hazards: 분기 명령어로 인한 흐름 제어 문제.
- 해결책: Branch Prediction.
Superscalar Processors
Superscalar 프로세서는 한 사이클에 여러 명령어를 동시에 실행(Issue)하여 CPI < 1 (IPC > 1)을 달성하는 기술이다.
- In-Order Superscalar: 명령어를 순서대로 실행한다. 하드웨어 복잡도가 낮지만 ILP(Instruction-Level Parallelism) 활용에 한계가 있다.
- Dynamic "Out-of-Order" Execution: 하드웨어가 런타임에 명령어 실행 순서를 재배치하여 Hazard를 줄이고 병렬성을 높인다.
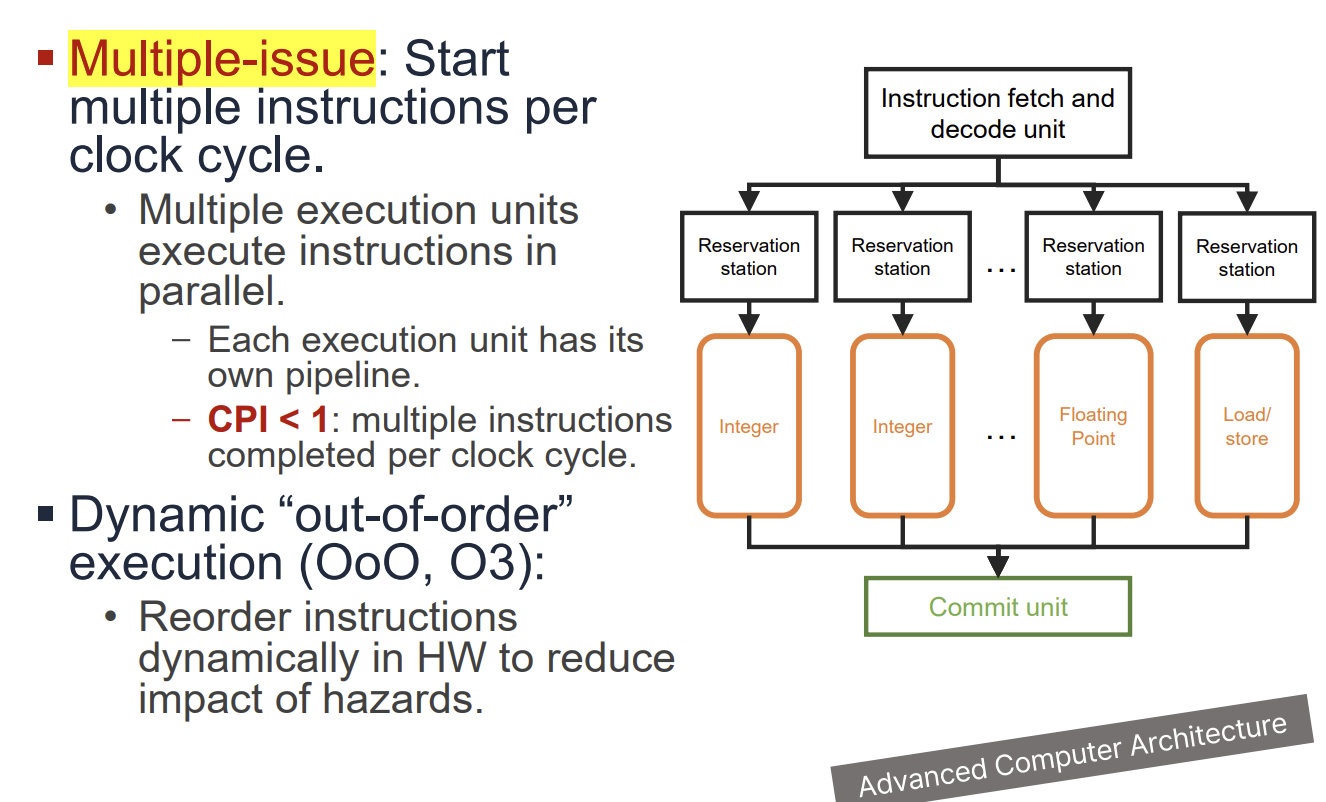
Superscalar 프로세서는 여러 개의 실행 유닛(Integer, Floating Point, Load/Store 등)을 갖추고 있다.
Computing CPI
CPI는 벤치마크 프로그램을 통해 측정한다.
ARM Cortex-A53 (Dual-issue)의 경우 Peak CPI는 0.5이지만, 실제로는 의존성과 파이프라인 스톨로 인해 0.5보다 높게 나타난다.
In-Order Dual-Issue Superscalar TinyRV1 Processor
In-Order Dual-Issue 프로세서는 한 사이클에 두 개의 명령어를 Fetch하고 Decode한다.
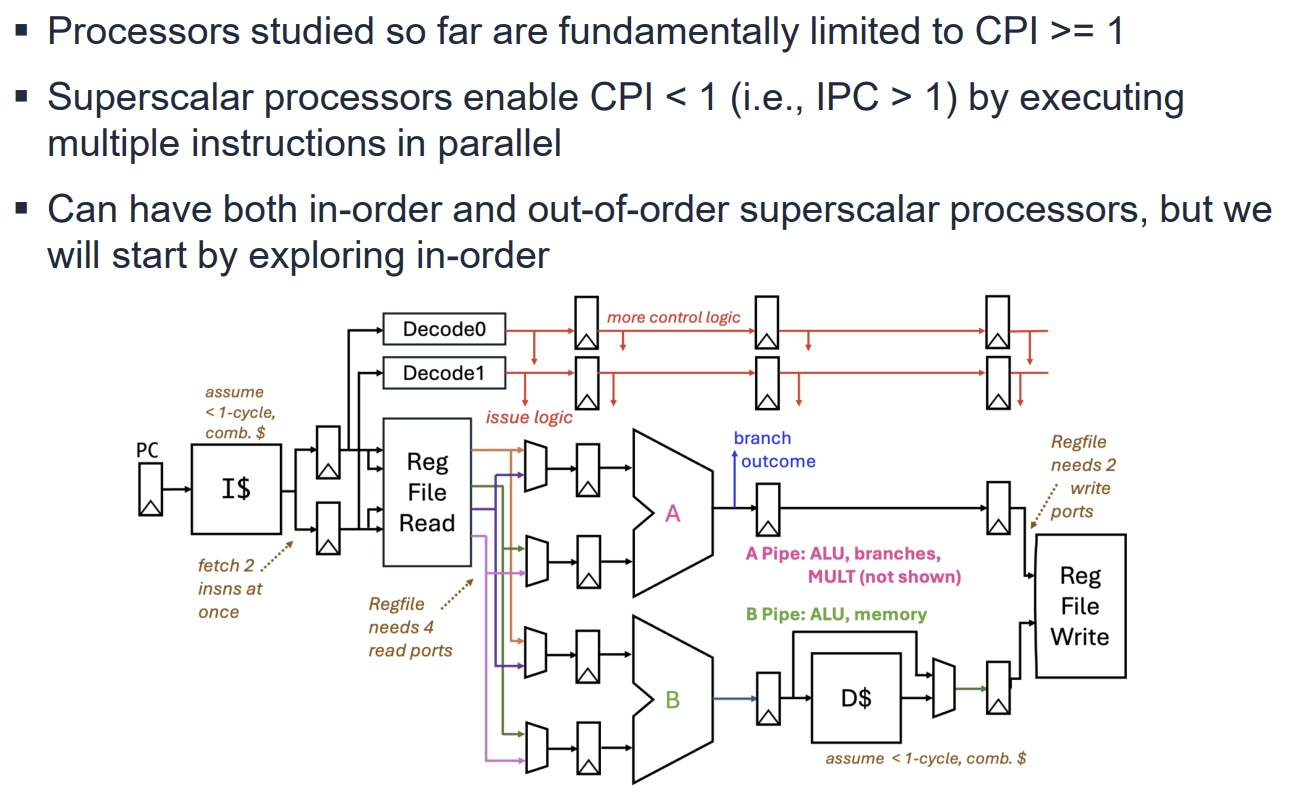
- Datapath: A-Pipe와 B-Pipe 두 개의 파이프라인을 병렬로 배치한다.
- Resource Requirement: 2개의 명령어를 동시에 처리하기 위해 레지스터 파일은 4개의 읽기 포트와 2개의 쓰기 포트가 필요하다.
- Execution: 명령어 유형에 따라 실행 가능한 파이프가 정해져 있다. 예를 들어 Load/Store는 B-Pipe에서만 실행 가능하다.
Superscalar Implementation Challenges
Superscalar 구현에는 여러 가지 어려움이 있다.
- Fetch: 한 번에 여러 명령어를 Fetch해야 한다. 캐시 블록 경계에 걸쳐 있는 경우(Unaligned Fetch) 복잡해진다.
- 해결책: Instruction Queue, Loop Stream Detector 등을 사용한다.
- Decode: 여러 개의 Decoder가 필요하다.
- Issue: 명령어 간의 의존성을 확인하고 동시에 실행 가능한지 판단해야 한다. (복잡도는 에 비례)
- Register Read: 포트 수가 늘어나면 레지스터 파일의 크기와 접근 시간이 증가한다.
- Bypass: 개의 Bypass 경로가 필요하여 배선이 복잡해지고 지연 시간이 증가한다.
- 해결책: Clustering을 통해 ALU와 레지스터 파일을 그룹화하여 Bypass 경로를 줄인다.
Control Hazards in Superscalar
Superscalar에서는 분기 예측이 더욱 중요하다. 분기 예측 실패 시 파이프라인에 있는 더 많은 명령어를 취소(Flush)해야 하므로 페널티가 커진다.
Analyzing Performance
Superscalar 프로세서의 성능은 프로그램의 ILP에 크게 의존한다. 예를 들어 벡터 덧셈 루프의 경우, 의존성이 없는 명령어들을 동시에 실행할 수 있어 CPI를 낮출 수 있다. 하지만 Load-Use Hazard나 Control Hazard가 발생하면 여전히 Stall이 발생하여 성능이 저하된다.
Instruction-Level Parallelism (ILP) and Instruction Scheduling
Instruction-Level Parallelism (ILP)은 명령어들의 실행을 중첩시켜 성능을 향상시키는 기법이다. 앞서 배운 Scalar Pipeline (부분 중첩)이나 Superscalar Pipeline (전체 중첩)이 이에 해당한다. ILP를 극대화하기 위해서는 명령어 스케줄링이 필수적이다.
- Static Scheduling: 컴파일 타임에 컴파일러가 수행한다. 하드웨어 복잡도가 낮지만, 보수적인 스케줄링을 할 수밖에 없다.
- Dynamic Scheduling: 런타임에 하드웨어가 수행한다. 구현 복잡도가 높지만, 실제 실행 상황에 맞춰 더 공격적인 스케줄링이 가능하다.
Dependencies and Hazards Revisited
프로그램의 속성인 의존성(Dependence)과 마이크로아키텍처의 속성인 해저드(Hazard)를 구분해야 한다.
- True Dependence (Data Dependence): 명령어 2가 명령어 1의 결과를 필요로 하는 경우 (Read-After-Write). 이는 데이터 흐름을 나타내는 진짜 의존성이다.
- Anti-Dependence: 명령어 2가 쓸 레지스터를 명령어 1이 아직 읽고 있는 경우 (Write-After-Read). 레지스터 이름을 바꾸면(Renaming) 해결되는 가짜 의존성(False Dependence)이다.
- Output Dependence: 명령어 1과 2가 같은 레지스터에 쓰려고 하는 경우 (Write-After-Write). 이 또한 Renaming으로 해결 가능한 가짜 의존성이다.
Single-Cycle 프로세서에서는 동시 실행이 없으므로 이러한 의존성이 해저드로 이어지지 않지만, 파이프라인이나 Out-of-Order 프로세서에서는 각각 RAW, WAR, WAW 해저드를 유발한다.
Limitation of In-Order Pipelines
In-Order Pipeline은 명령어를 프로그램 순서대로 인출(Fetch), 디코드(Decode), 실행(Execute)한다. Cache Miss나 긴 지연 시간의 연산(Floating Point 등)이 발생하면 파이프라인 전체가 멈추는(Stall) 문제가 있다. 특히 Execute 단계가 하나뿐이거나 Blocking 방식이라면 Structural Hazard가 발생하여 성능 저하가 심각해진다.
이를 개선하기 위해 Non-blocking Execute Stage와 더 공격적인 Issue 정책을 도입할 수 있다.
Stall-on-Miss vs. Stall-on-Use
In-Order Pipeline의 Issue 정책은 두 가지로 나뉜다.
- Stall-on-Miss (Simple Issue Policy): Cache Miss와 같은 긴 지연 이벤트가 발생하면 파이프라인 전체를 즉시 멈춘다. 구현이 간단하고 전력 소모가 적지만 성능이 낮다. (예: MIPS 5-stage pipeline)
- Stall-on-Use (Aggressive Issue Policy): 데이터가 실제로 필요할 때(Use)까지 Stall을 늦춘다. Register Read 단계에서 RAW 해저드를 감지하고 Stall을 건다. 이를 위해서는 Scoreboard와 같은 추가적인 하드웨어와 복잡한 제어 로직이 필요하다.
Performance Impact of Stall Policies
Stall-on-Use 방식은 Stall-on-Miss보다 더 높은 성능을 낼 수 있다. 예를 들어, Load Miss가 발생하더라도 그 데이터에 의존하지 않는 독립적인 명령어들은 계속해서 실행될 수 있다(Memory-Level Parallelism 활용).
그러나 In-Order Issue 정책 자체의 한계는 여전히 존재한다. 앞선 명령어(i2)가 RAW 해저드로 인해 Stall 되면, 그 뒤에 있는 명령어들(i3, i4)이 i2와 전혀 상관없는 독립적인 명령어라 할지라도 Issue 단계(Register Read Stage)가 막혀있어 실행되지 못한다. 즉, In-Order Issue는 RAW 해저드를 Structural Hazard로 변환시켜 버리는 셈이다.
이 문제를 근본적으로 해결하기 위해서는 Out-of-Order Execution이 필요하다.
Nature of Out-of-Order Execution
Out-of-Order (OoO) 실행은 파이프라인의 효율성을 극대화하기 위한 기술이다. 핵심 원리는 다음과 같다.
- Dynamic Scheduling: 하드웨어가 런타임에 명령어 실행 순서를 재배치한다. RAW 해저드가 있는 명령어만 Stall 시키고, 뒤따르는 독립적인 명령어들은 먼저 실행(Issue)한다.
- Issue Queue (Reservation Station): 데이터 의존성 때문에 Stall 된 명령어들을 임시 저장하는 버퍼이다. 이곳에 대기 중인 명령어들은 자신의 피연산자(Operand)가 준비되는 즉시 실행 유닛으로 보내진다.
이러한 구조를 통해 Cache Miss나 Floating Point 연산과 같은 긴 지연 시간을 가진 작업이 발생해도 파이프라인 전체가 멈추지 않고 유용한 작업을 계속할 수 있게 된다 (Latency Tolerance).
Code Scheduling: Static vs. Dynamic
명령어 스케줄링은 의존성이 없는 독립적인 명령어들을 찾아 실행 순서를 재배치하는 과정이다.
-
Static Scheduling (Compiler): 컴파일 타임에 수행된다. Load-Use 지연 슬롯(Delay Slot)을 채우거나 Superscalar의 병렬 실행 슬롯을 채우기 위해 코드를 재배치한다.
- 장점: 추가 하드웨어 비용이 없다.
- 한계: 분기(Branch)로 인한 기본 블록(Basic Block) 내의 제한된 스케줄링 범위, 제한된 레지스터 수, 메모리 에일리어싱(Aliasing)의 모호함, 런타임 이벤트(Cache Miss 등) 예측 불가 등의 문제가 있다. Loop Unrolling이나 Function Inlining으로 범위를 넓힐 수는 있지만 한계가 있다.
-
Dynamic Scheduling (Hardware): 런타임에 수행된다. 명령어 윈도우(Sliding Window) 내에서 실행 가능한 명령어를 찾아낸다.
- 장점: 런타임 정보를 활용하여 더 공격적인 스케줄링이 가능하며, Register Renaming을 통해 가짜 의존성(WAR, WAW)을 제거할 수 있다. Loop Unrolling도 하드웨어적으로 투명하게 수행된다.
Register Renaming
Register Renaming은 OoO 실행을 가능하게 하는 핵심 기술 중 하나이다.
- 목적: 아키텍처 레지스터(Architectural Register, 예: r1, r2)의 이름 재사용으로 인해 발생하는 가짜 의존성(WAR, WAW)을 제거한다.
- 방법: 아키텍처 레지스터를 더 많은 수의 물리 레지스터(Physical Register, 예: p1, p2...)로 매핑한다.
- Map Table: 현재 아키텍처 레지스터가 어떤 물리 레지스터에 매핑되어 있는지 추적한다.
- Free List: 사용 가능한 물리 레지스터의 목록을 관리한다.
- 동작: 명령어가 Decode 될 때, 목적지 레지스터(Destination Register)에 새로운 물리 레지스터를 할당한다. 이를 통해 같은 레지스터 이름을 쓰더라도 실제로는 서로 다른 물리적 공간을 사용하게 되어 독립적인 실행이 가능해진다. (Single Assignment Form과 유사)
Out-of-Order Pipeline Stages
OoO 프로세서의 파이프라인은 크게 세 부분으로 나뉜다.
- In-Order Front-End: Fetch -> Decode -> Rename -> Dispatch. 명령어를 순서대로 가져와 디코딩하고 리네이밍한 후 Issue Queue로 보낸다.
- Out-of-Order Execution Core: Issue -> Register Read -> Execute -> Writeback. 피연산자가 준비된 명령어부터 순서에 상관없이 실행하고 결과를 쓴다.
- In-Order Retirement (Commit): 실행이 완료된 명령어들을 프로그램 순서대로 확정(Commit)한다. 이는 예외 처리나 인터럽트 발생 시 정확한 상태(Precise State)를 보장하기 위함이다.
Dynamic Scheduling Mechanisms
Out-of-Order (OoO) 프로세서의 핵심은 명령어가 프로그램 순서대로 인출(Fetch)되고 디코드(Decode)되지만, 실행은 피연산자(Operand)가 준비되는 대로 순서 없이(Out-of-Order) 이루어진다는 점이다. 이를 가능하게 하는 메커니즘을 다룬다.
1. Issue Queue (Reservation Station)
- 데이터 의존성으로 인해 Stall 된 명령어들을 임시 저장하는 버퍼이다.
- 명령어 윈도우(Instruction Window)라고도 하며, 파이프라인의 병목을 해소하고 ILP를 높이는 역할을 한다.
- Ready Table: 각 물리 레지스터의 데이터 준비 여부(Yes/No)를 추적하는 테이블이다. Issue Queue의 명령어들은 이 테이블을 참조하여 자신의 모든 소스 레지스터가 준비되었는지 확인한다.
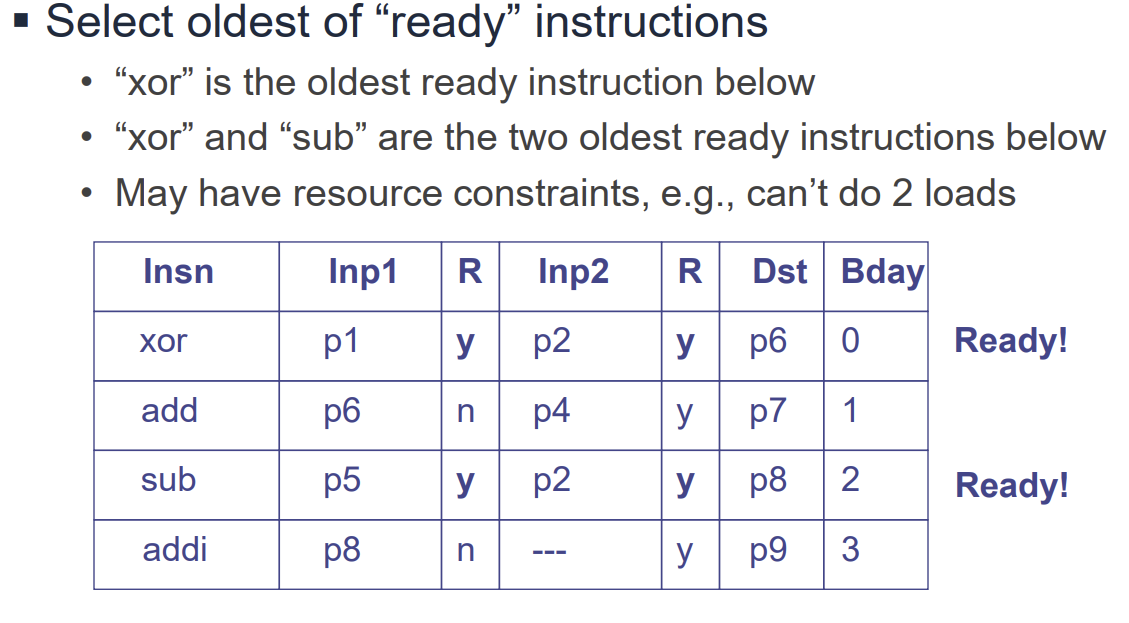
2. Dispatch
- Renaming된 명령어를 Issue Queue와 Re-order Buffer (ROB)에 할당하는 단계이다.
- 입력 레지스터의 Ready 비트를 읽고, 출력 레지스터의 Ready 비트를 지운다(Clear).
3. Issue Algorithm (Select + Wakeup)
- Select: 모든 피연산자가 준비된(Ready) 명령어 중 가장 오래된 것을 선택하여 실행 유닛으로 보낸다.
- Wakeup: 실행이 완료된 명령어의 결과가 생성되면, 이를 기다리던(Dependent) 명령어들에게 알린다(Broadcast). CAM(Content Addressable Memory)을 사용하여 Issue Queue 내의 대기 중인 명령어들의 소스 레지스터 태그와 비교하고 Ready 비트를 업데이트한다.
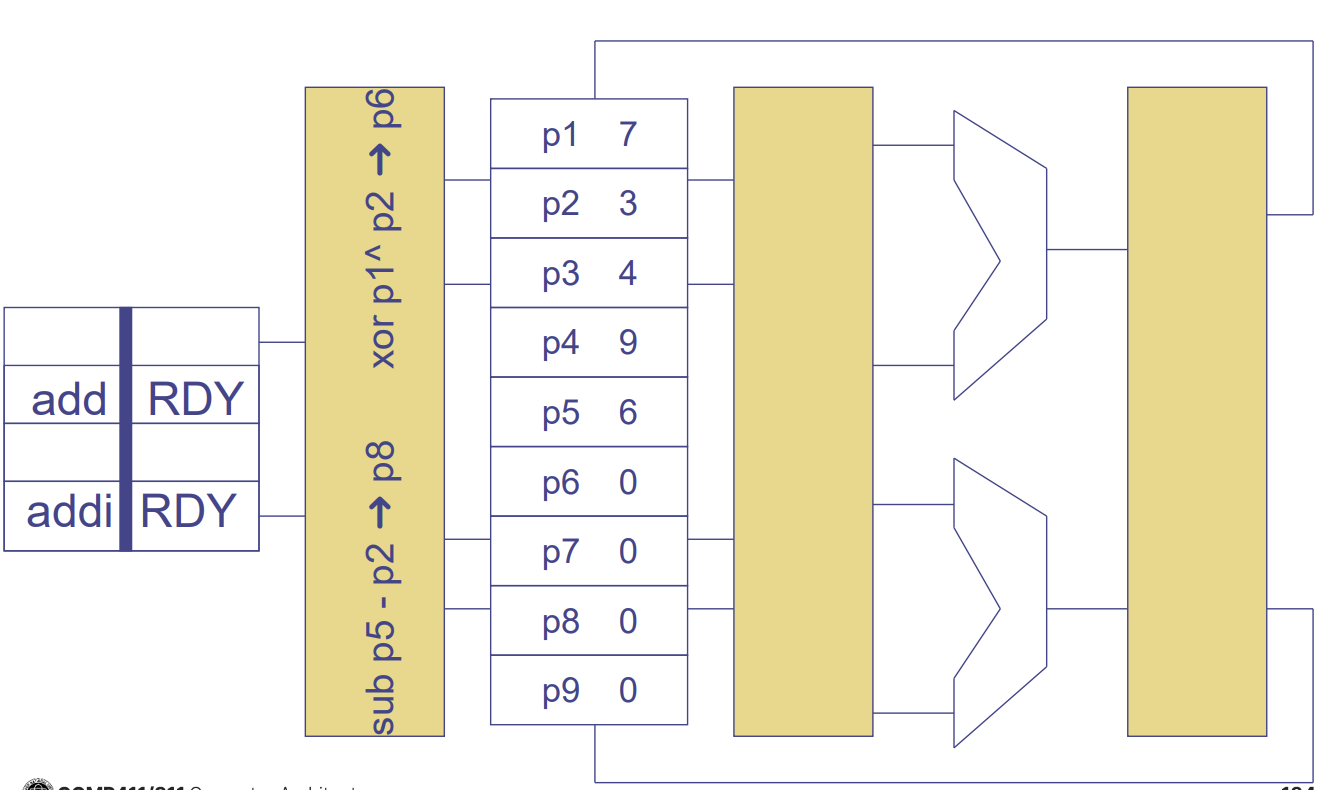
4. Re-order Buffer (ROB)
- 명령어의 순차적 완료(In-order Commit)를 보장하기 위한 구조이다.
- Fetch 단계부터 Commit 단계까지 모든 명령어를 프로그램 순서대로 유지한다.
- 예외 처리(Exception)나 분기 예측 실패(Branch Misprediction) 시 정확한 상태 복구(Precise State Recovery)를 지원한다.
Register Renaming Algorithm (Full)
Register Renaming은 가짜 의존성(WAW, WAR)을 제거하기 위해 아키텍처 레지스터를 물리 레지스터로 매핑하는 과정이다.
- Data Structures:
- Map Table: 현재 아키텍처 레지스터가 매핑된 물리 레지스터를 저장한다.
- Free List: 할당 가능한 빈 물리 레지스터들의 리스트이다.
- Decode Stage:
- 소스 레지스터는 Map Table을 참조하여 현재 매핑된 물리 레지스터로 변환한다.
- 목적지 레지스터는 Free List에서 새로운 물리 레지스터를 할당받아 매핑하고, Map Table을 갱신한다. 이때 기존에 매핑되어 있던 물리 레지스터(Overwritten Register) 정보는 ROB에 기록하여 나중에 해제(Free)할 수 있도록 한다.
Recovery and Commit
Recovery (복구) 분기 예측이 틀렸을 때(Misprediction), 잘못된 경로의 명령어들을 취소하고 프로세서 상태를 복구해야 한다.
- Flush: Issue Queue와 ROB에서 잘못된 명령어들을 제거한다.
- Map Table Restore: Map Table을 분기 이전 시점의 상태로 되돌려야 한다. 이를 위해 Log-based(느림) 또는 Checkpoint-based(빠름, 하드웨어 비용 큼) 방식을 사용한다.
Commit (은퇴) 명령어 실행이 완전히 끝나고, 더 이상 취소될 가능성이 없을 때 결과를 영구적으로 반영한다.
- In-Order: 반드시 프로그램 순서대로 Commit한다.
- Freeing Registers: 해당 명령어가 덮어쓴(Overwrite) 이전 물리 레지스터는 더 이상 필요하지 않으므로 Free List로 반환하여 재사용할 수 있게 한다.
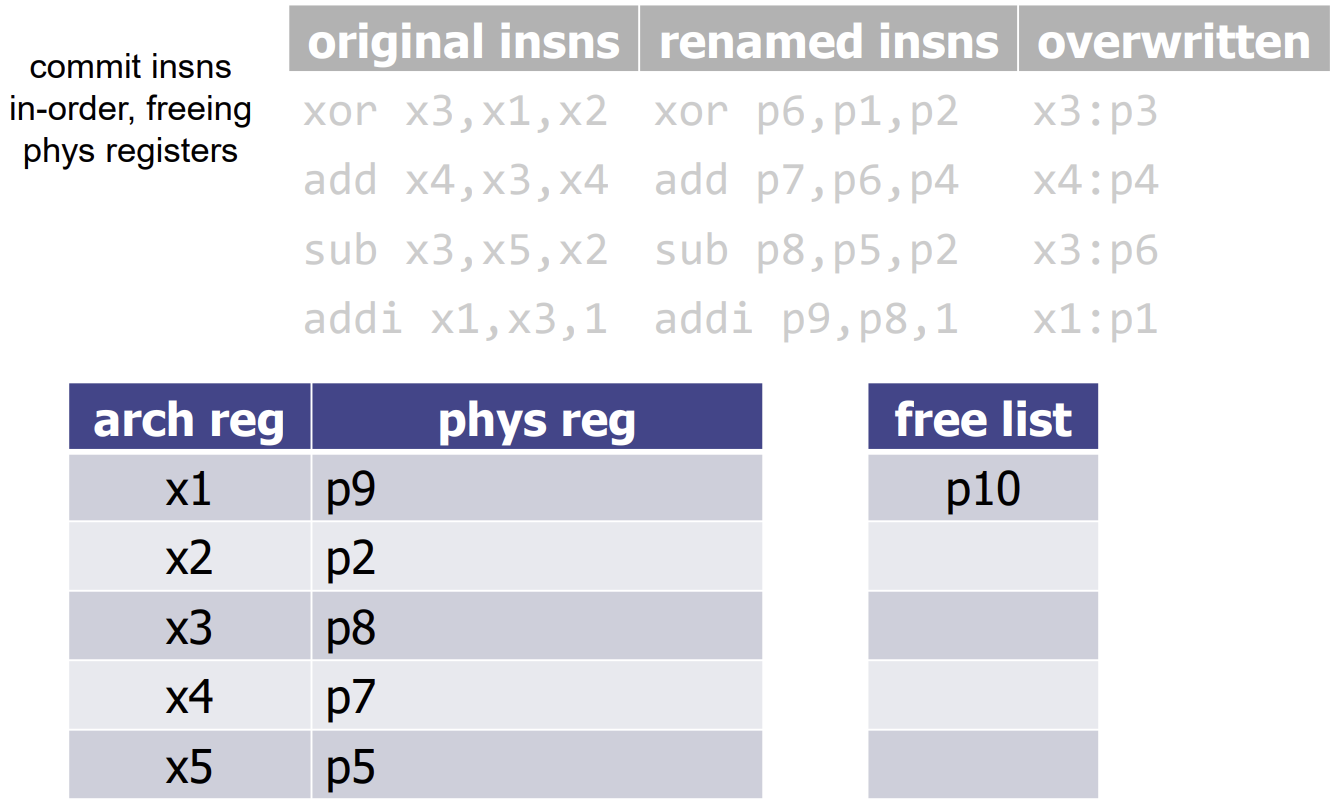
Handling Memory Operations in OoO Execution
Out-of-Order (OoO) 실행에서 메모리 접근(Load/Store)은 특별한 주의가 필요하다. Load는 메모리 값을 읽어 레지스터에 쓰고, Store는 레지스터 값을 메모리에 쓴다. 여기서 발생하는 문제는 주소가 계산되기 전까지는 의존성을 확실히 알 수 없다는 점이다.
1. Load/Store Queue (LSQ)
- 메모리 명령어들의 순서와 의존성을 관리하기 위한 하드웨어 구조이다.
- Load Queue: Load 명령어들이 프로그램 순서대로 할당된다.
- Store Queue: Store 명령어들이 프로그램 순서대로 할당된다. Store는 Commit 시점에만 메모리에 실제로 쓸 수 있다 (Speculative Execution 때문).
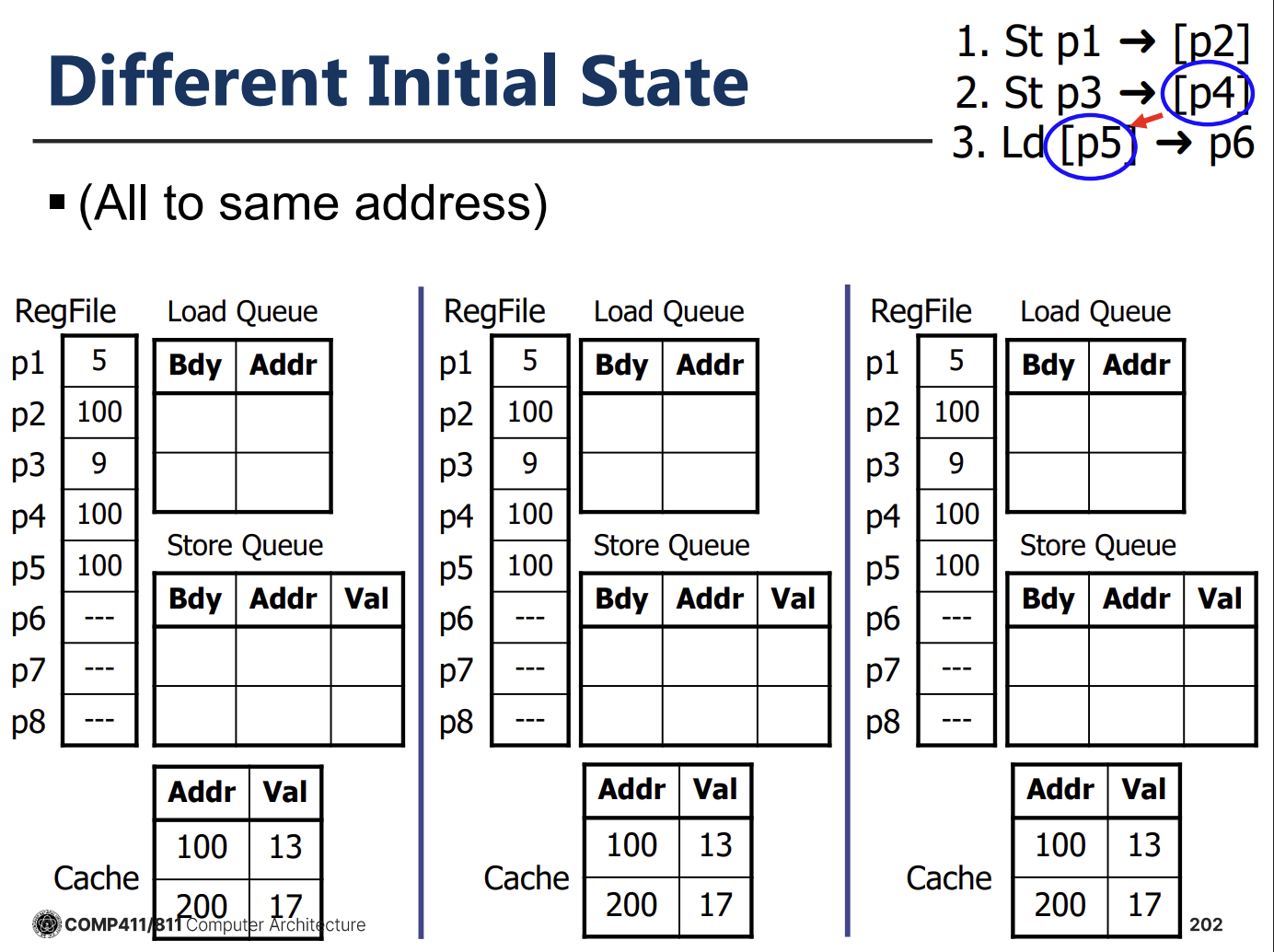
2. Store-to-Load Forwarding
- 만약 Load 명령어가 이전 Store 명령어와 같은 주소에 접근한다면, 메모리까지 가지 않고 Store Queue에 있는 데이터를 직접 가져와야 한다.
- 절차: Load 명령어가 실행될 때, Store Queue를 검색하여 자신보다 오래된 Store 중 주소가 겹치는 것이 있는지 확인한다. 있다면 해당 데이터를 Forwarding 받는다.
![PDF p.202: Example of good interleaving where Load gets value from Store via forwarding]
3. Memory Disambiguation (Address Check)
- Load와 Store의 주소가 계산되기 전에는 이들이 서로 겹치는지 알 수 없다.
- Conservative Approach: 모든 이전 Store의 주소가 결정될 때까지 Load를 실행하지 않는다. (성능 저하 심함)
- Speculative Approach: 주소가 겹치지 않을 것이라고 예측하고 Load를 미리 실행한다. 나중에 주소가 겹치는 것이 확인되면(Bad Interleaving), Load와 그 이후의 명령어들을 취소하고 재실행(Recover)한다.
OoO Execution in Modern Processors
현대 고성능 프로세서들은 대부분 OoO 실행 방식을 채택하고 있다.
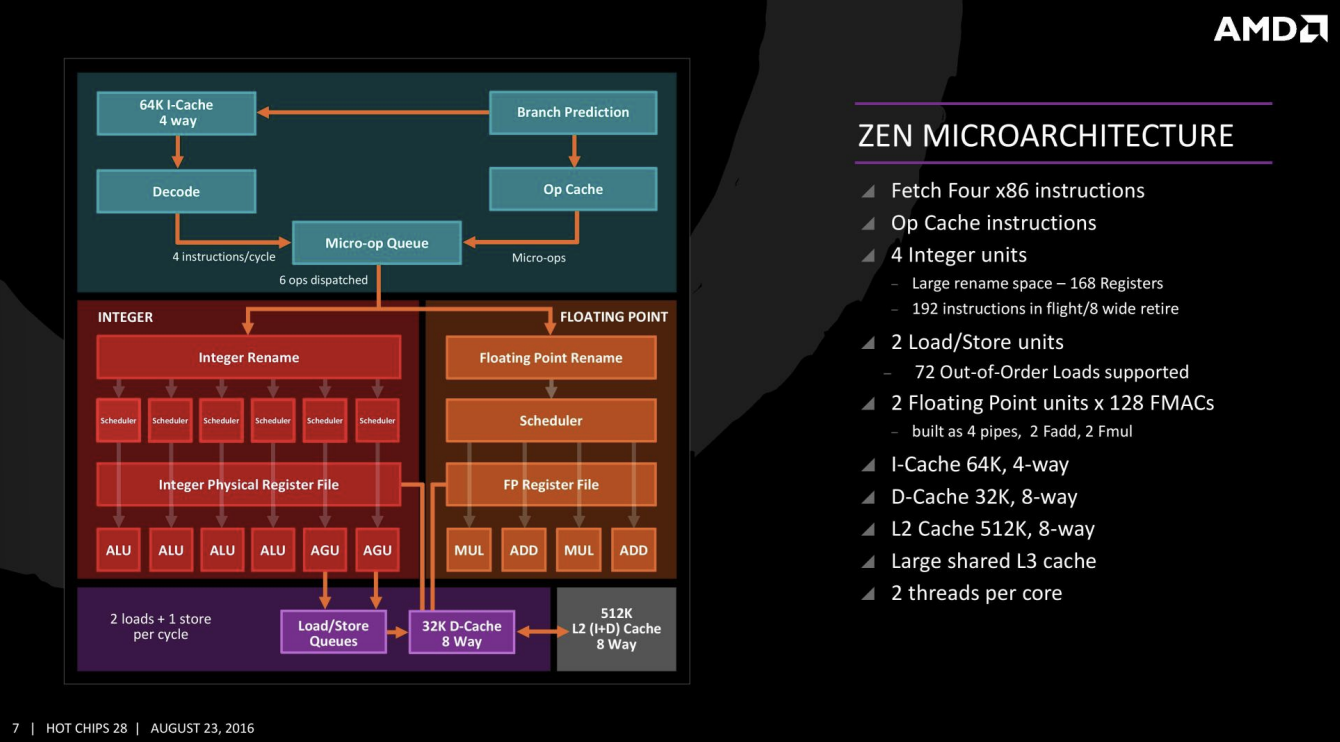
- Apple Cyclone (A7): 6-wide issue, 192-entry ROB를 갖춘 강력한 모바일 프로세서이다.
- AMD Zen Microarchitecture: 4-wide fetch/decode, 6-wide dispatch, 대규모 스케줄러와 실행 유닛, L1/L2/L3 캐시 계층 구조를 갖춘 고성능 데스크탑/서버 프로세서이다.
- Micro-op Queue: 디코딩된 명령어(Micro-op)를 저장하여 프론트엔드 병목을 줄인다.
- Separate Integer/FP Pipelines: 정수 연산과 부동 소수점 연산을 위한 별도의 리네이밍 및 스케줄링 로직을 가진다.
- Stack Engine: 스택 포인터 조작을 최적화한다.
- Neural Net Branch Prediction: 퍼셉트론 기반의 고성능 분기 예측기를 사용한다.
Summary: Advanced Scheduling Techniques
프로세서 성능을 높이기 위한 스케줄링 기법은 크게 두 가지로 요약된다.
- Code Scheduling (Static): 컴파일러가 수행한다. Pipeline stall을 줄이고 ILP를 높이기 위해 명령어 순서를 바꾼다. 하지만 분기, 레지스터 부족, 메모리 에일리어싱 등의 한계가 있다.
- Dynamic Scheduling (Hardware): 하드웨어가 런타임에 수행한다. Register Renaming으로 가짜 의존성을 제거하고, Issue Queue와 ROB를 이용해 명령어들을 Out-of-Order로 실행하며, Load/Store Queue로 메모리 접근을 최적화한다. 하드웨어 복잡도는 높지만 런타임 정보를 활용하여 최적의 성능을 이끌어낸다.
Precise Interrupts and Exceptions
프로세서에서 예외(Exception)나 인터럽트(Interrupt)가 발생했을 때, 시스템의 상태가 순차적 실행 모델(Sequential Programming Model)과 일치해야 한다. 이를 Precise Exception이라고 한다.
- 조건:
- 예외를 발생시킨 명령어 이전의 모든 명령어는 완료되어야 한다.
- 예외를 발생시킨 명령어와 그 이후의 명령어들은 완료되지 않아야 하며(아무런 상태 변경도 없어야 함), 예외 처리 후 재실행 가능해야 한다.
In-Order Pipeline에서는 Precise Exception을 구현하기 비교적 쉽지만, Out-of-Order Pipeline에서는 명령어들이 순서 없이 실행되고 완료되기 때문에 이를 보장하기 어렵다. 예를 들어, 나중에 실행된 명령어가 먼저 완료되어 레지스터를 업데이트한 상태에서 이전 명령어에서 예외가 발생하면, 이미 업데이트된 상태를 되돌리기 어렵다 (Imprecise Exception).
Hardware Speculation and Reorder Buffer (ROB)
Out-of-Order 프로세서에서 Precise Exception과 분기 예측 실패 시의 복구(Recovery)를 지원하기 위해 Hardware Speculation 기법과 **Reorder Buffer (ROB)**를 사용한다.
Reorder Buffer (ROB)
- 명령어의 순차적 완료(In-Order Commit)를 보장하기 위한 원형 버퍼(Circular Buffer)이다.
- Fetch된 명령어는 ROB의 Tail에 순서대로 할당되고, 실행이 완료된 명령어는 ROB의 Head에서 순서대로 제거(Commit/Retire)된다.
- ROB는 각 명령어의 실행 상태(완료 여부, 예외 발생 여부 등)와 결과값(Speculative Result)을 저장한다.
- Speculative Execution: 명령어는 실행이 완료되더라도 즉시 Architectural Register File (ARF)에 쓰지 않고, ROB에 결과를 임시 저장한다.
- Commit: 명령어가 ROB의 Head에 도달하고 예외나 분기 예측 실패가 없음이 확인되면, 그제서야 ROB에 저장된 결과를 ARF에 쓰고 명령어를 제거한다.
Expanded Register File: ARF + ROB
Register Renaming을 위해 레지스터 파일의 개념을 확장한다.
- Architectural Register File (ARF): 커밋된(Committed), 즉 영구적인 상태의 레지스터 값들을 저장한다.
- ROB: 실행 중이거나 완료되었지만 아직 커밋되지 않은 투기적(Speculative) 상태의 레지스터 값들을 저장한다.
Updated Renaming and Execution Flow
ROB를 도입한 Out-of-Order 파이프라인의 동작은 다음과 같이 수정된다.
- Rename Stage:
- 명령어가 할당될 ROB 엔트리 번호가 해당 명령어의 물리 레지스터 태그(ROB Tag)가 된다.
- Rename Map Table (RMT)은 아키텍처 레지스터가 어떤 ROB 엔트리(최신 값)를 가리키는지 저장한다.
- Register Read Stage:
- 소스 레지스터의 값을 찾을 때 RMT를 참조한다.
- 값이 ARF에 있으면 읽어오고, ROB에 있으면 ROB에서 읽어온다(아직 계산 중이면 태그만 가져옴).
- Execution Stage:
- 연산이 완료되면 결과를 CDB를 통해 브로드캐스트한다.
- 결과값은 ROB의 해당 엔트리에 저장되고, Issue Queue에서 대기 중인 의존 명령어들에게 전달된다.
- Commit Stage (Retire):
- 명령어가 ROB Head에 도달하면 완료 여부를 확인한다.
- 정상 완료 시 결과를 ARF에 쓰고 ROB에서 제거한다.
- 예외 발생 시 파이프라인을 비우고(Flush) 예외 처리 루틴으로 이동한다.
Handling Branch Misprediction
분기 예측이 실패한 경우(Branch Misprediction), 잘못된 경로로 실행된 모든 명령어들을 취소해야 한다.
- 분기 명령어가 ROB Head에 도달했을 때 예측 실패가 확인되면, ROB에 있는 이후의 모든 명령어들을 플러시(Flush)하고, RMT를 복구하여 정확한 상태로 되돌린다.
- 이는 Precise Exception 처리와 동일한 메커니즘을 사용하므로 별도의 복잡한 하드웨어 추가 없이 구현 가능하다.