데이터 변화율 기반 회귀 체인을 이용한 생분해성 섬유 원사 물성 예측 모델 성능 향상
논문 정보
- 제목 (Title): 데이터 변동률 기반 회귀 체인을 사용한 생분해성 섬유 원사 물성 예측 모델 개선 (Improving Biodegradable Fiber Yarn Property Prediction Model Using Data Change Rate-Based Regression Chain)
- 저자 (Authors) 및 소속 (Affiliations): 김덕엽, 류영교, 강보권, 김태환, 이우진 (경북대학교 IT대학 컴퓨터학부)
- 학회 또는 저널명 (Conference or Journal Name): 2024 한국소프트웨어종합학술대회 (KSC 2024)
- 제출일 또는 발행일 (Submission or Publication Date): 2024년
- 키워드 (Keywords): 생분해성 섬유, 물성 예측, 회귀 체인, 데이터 변동률, 상관 분석, 오류 전파
- 초록 (Abstract): 생분해성 섬유 원사는 다양한 물성을 가지며, 이들 물성 간에 종속성이 존재할 경우 **회귀 체인(Regression Chain)**을 활용하여 예측 모델의 성능을 향상시킬 수 있다. 일반적으로 데이터 간 종속성은 상관 분석으로 평가하지만, 섬유 방사 데이터는 목표 물성에 따라 우선적으로 생산되므로 데이터 수집 및 분포가 불균형하여 상관 분석 결과의 신뢰성이 떨어지는 문제가 있다. 잘못 평가된 종속성을 기반으로 회귀 체인을 적용하면 오류 전파(Error Propagation)가 발생하여 오히려 모델의 예측 성능을 저하시킬 수 있다. 따라서 본 논문에서는 이러한 문제를 해결하기 위해, 원사 물성 데이터의 변동률을 기반으로 물성 간 종속성을 새롭게 평가하고 이를 회귀 체인에 적용하여 물성 예측 모델의 성능을 개선하는 방법을 제안한다. 원사의 물성들은 일정 범위의 연속형 데이터이므로, 특정 공정 변수에 따른 각 물성의 데이터 변동률 패턴이 유사하다면 두 물성 간에 강한 종속성이 있다고 볼 수 있다. 제안된 방법의 효과는 기존 단순 예측 모델과 데이터 변동률 기반 회귀 체인 모델의 성능 비교를 통해 검증한다.
- 주요 연구 내용 (Main Research Content/Methodology):
- 생분해성 섬유 원사 물성 예측을 위한 회귀 체인 기법의 성능 향상 방법을 제안함.
- 기존 상관 분석의 한계를 극복하기 위해 데이터 변동률 기반 종속성 평가 방법을 제안함.
- 물성 간 종속성을 정확하게 파악하여 회귀 체인에서 오류 전파 문제를 해결함.
- 제안 방법의 효과를 기존 단순 예측 모델과 비교하여 검증함.
- 주요 결과 및 결론 (Key Findings and Conclusion):
- 데이터 변동률 기반 종속성 평가가 직접 상관 분석보다 더 신뢰할 수 있는 결과를 제공함.
- 인장신도와 체인을 적용했을 때 MAE 13% 개선, MSE 20% 개선, R² 5% 개선을 달성함.
- 잘못된 종속성 평가로 인한 오류 전파 문제를 효과적으로 해결함.
- 불균형한 산업 데이터에서 변수 간 숨겨진 종속성을 파악하는 새로운 접근법을 제시함.
- 기여점 (Contributions):
- 데이터 분포가 불균형한 섬유 방사 데이터에서 기존 상관 분석의 한계를 극복하는 새로운 종속성 평가 방법을 제안함.
- 데이터 변동률 기반 분석을 통해 물성 간 실제 물리적 종속성을 더 정확하게 파악함.
- 회귀 체인에서 오류 전파 문제를 해결하여 예측 모델의 성능을 효과적으로 향상시킴.
- DOI (Digital Object Identifier): 제공되지 않음.
- 기타 식별 가능한 정보:
- 연구 분야: 인공지능, 기계 학습, 섬유 공학, 데이터 분석
- 대상 공정: 생분해성 섬유(PLA) 방사 공정
- 데이터셋: 총 1,998개의 데이터셋 (PLA 원료 용융지수 1개, 9개 방사 공정 변수, 6개 주요 물성)
요약
서론 (Introduction)
생분해성 섬유 원사의 물성 예측은 방사 공정 최적화 및 공정 역설계를 위해 매우 중요하다. 물성들 간의 종속 관계를 예측 모델에 활용하는 회귀 체인 기법은 성능 향상에 기여할 수 있지만, 데이터 종속성을 정확하게 평가하는 것이 선행되어야 한다. 그러나 섬유 방사 데이터는 생산 목표에 따라 데이터 분포가 불균형한 특성을 가져, 일반적인 상관 분석 결과의 변동성이 크고 신뢰도가 낮다. 만약 종속성이 없거나 낮은 데이터에 회귀 체인을 잘못 적용하면, 이전 단계 모델의 예측 오차가 다음 단계로 전파되어 전체 모델의 성능이 저하되는 심각한 문제가 발생할 수 있다. 따라서 본 연구에서는 기존 상관 분석을 대체할 새로운 종속성 평가 방법을 제안하고자 한다. 시계열 데이터 패턴 분석에 주로 사용되는 데이터 변동률 개념을 도입하여, 방사 공정 변화에 따른 물성 값의 변화 패턴 유사도를 분석함으로써 더 신뢰성 높은 종속성 평가 기준을 마련하고, 이를 통해 회귀 체인 모델의 성능을 효과적으로 향상시키는 방법을 제안한다.
관련 연구 (Related Work)
생분해성 섬유 원사 물성 예측 모델
물성 예측 모델은 PLA(PolyLactic Acid) 원료의 용융지수 1개와 9개의 방사 공정 데이터(데니어, 스핀빔 온도, 고뎃 롤러 속도/온도 등)를 입력 변수로 사용하여 6개의 주요 물성(인장강도, 인장신도, 열응력 특성 등)을 각각 예측한다. 모델 학습에는 총 1,998개의 데이터셋이 사용되었으며, 결측치나 이상치는 없다.
회귀 체인 (Regression Chain)
회귀 체인은 다수의 회귀 모델을 사전에 정의된 순서에 따라 체인 형태로 연결하는 다중 레이블 예측 기법이다. 각 모델은 독립 변수(X_train)와 더불어, 체인상에서 자신보다 앞 순서에 있는 모델들의 실제 레이블(y)을 추가적인 학습 데이터로 활용한다. 예측 시에는 앞선 모델의 예측값(y')이 다음 모델의 입력으로 순차적으로 전달된다. 따라서 체인의 순서가 매우 중요하며, 잘못된 순서는 오류 전파를 유발할 수 있다.
데이터 변동률 (Data Change Rate)
데이터 변동률은 특정 기준 대비 데이터의 변화량을 비율로 나타낸 것으로, 주로 시계열 데이터의 패턴이나 유사도를 분석하는 데 사용된다. 이전 데이터 대비 변동률은 다음 수식으로 계산된다:
제안 방법 및 분석
본 연구에서는 두 가지 방법으로 물성 간 종속성을 분석하고 그 결과를 비교했다.
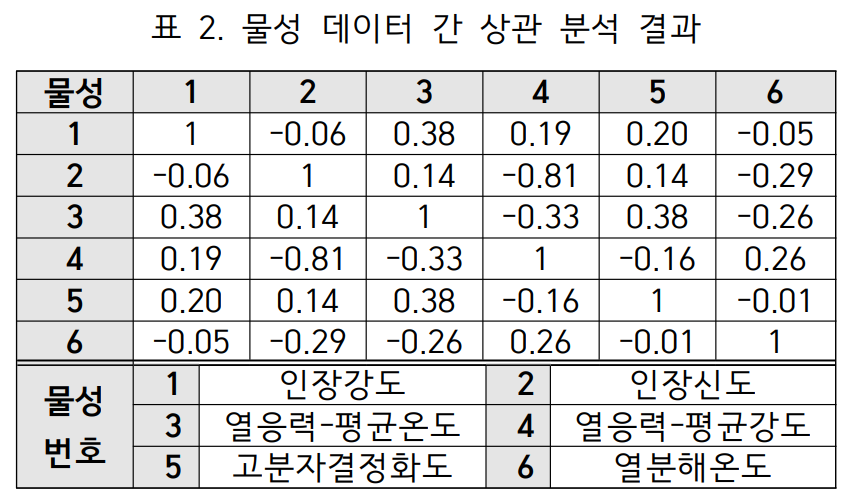
- 물성 데이터 간 직접 상관 분석: 6개 물성 데이터 간의 피어슨 상관계수를 직접 계산했다(표 2). 그 결과, 주요 물성인 인장강도는 열응력-평균온도와 0.38의 약한 양의 상관관계를 보였으나, 인장신도와는 -0.06으로 거의 독립적인 관계를 보였다.
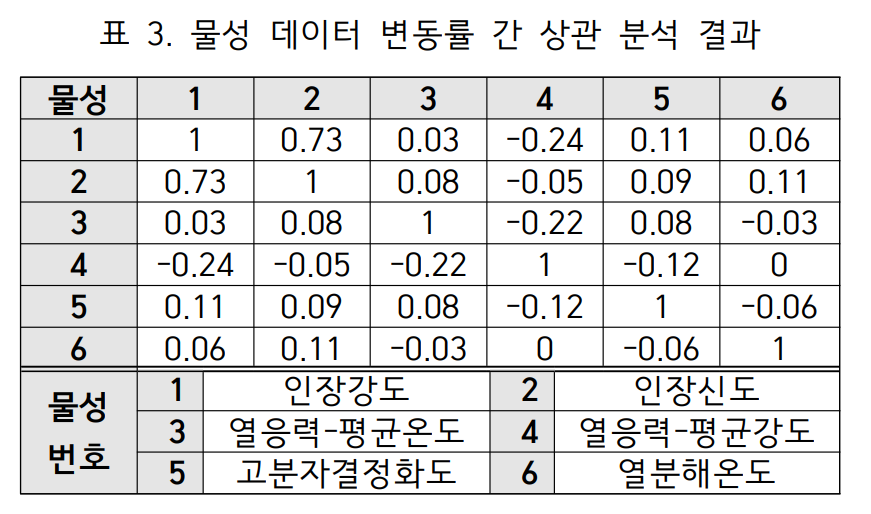
- 물성 데이터 변동률 간 상관 분석 (제안 방법): 데이터 분포가 가장 균형 잡힌 '고뎃 롤러1 속도'를 기준으로 각 물성 데이터의 변동률을 계산한 뒤, 이 변동률 데이터들 간의 피어슨 상관계수를 계산했다(표 3). 분석 결과, 인장강도의 변동률은 인장신도의 변동률과 0.73이라는 매우 강한 양의 상관관계를 보였으며, 이는 직접 상관 분석 결과와 크게 다른 양상이다.
이 두 분석 결과의 차이는 데이터 불균형으로 인해 직접적인 상관 분석이 실제 물리적 종속성을 제대로 반영하지 못할 수 있음을 시사하며, 데이터 변동률 기반 분석이 더 신뢰도가 높을 수 있다는 가설을 뒷받침한다.
실험 및 결과
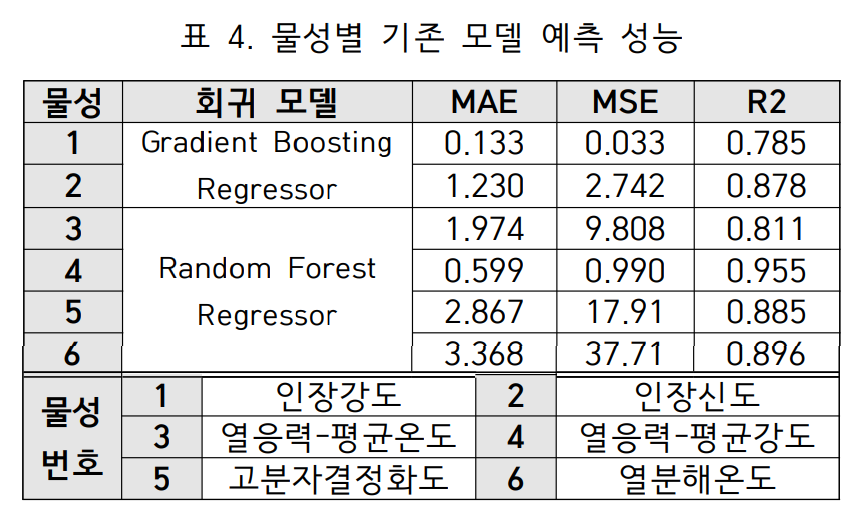
제안 방법의 유효성을 검증하기 위해, 주요 물성인 인장강도를 예측 대상으로 설정하고 다른 5개 물성을 각각 단일 체인으로 연결하여 모델 성능 변화를 측정했다. 전체 데이터셋은 5-fold 교차 검증을 통해 평가되었으며, 성능 지표로는 MAE, MSE, R²를 사용했다.
- 실험 절차:
- 체인으로 연결할 물성 A의 예측 모델을 먼저 학습시킨다(표 4).
- 인장강도 예측 모델을 학습시킬 때, 원료/공정 데이터와 더불어 물성 A의 실제 측정값을 추가하여 '인장강도 체인 모델'을 생성한다.
- 테스트 시, 먼저 물성 A 예측 모델로 테스트 데이터의 A 값을 예측한다.
- 이 예측된 A 값을 테스트 데이터에 추가한 뒤, '인장강도 체인 모델'을 통해 최종 인장강도를 예측한다.
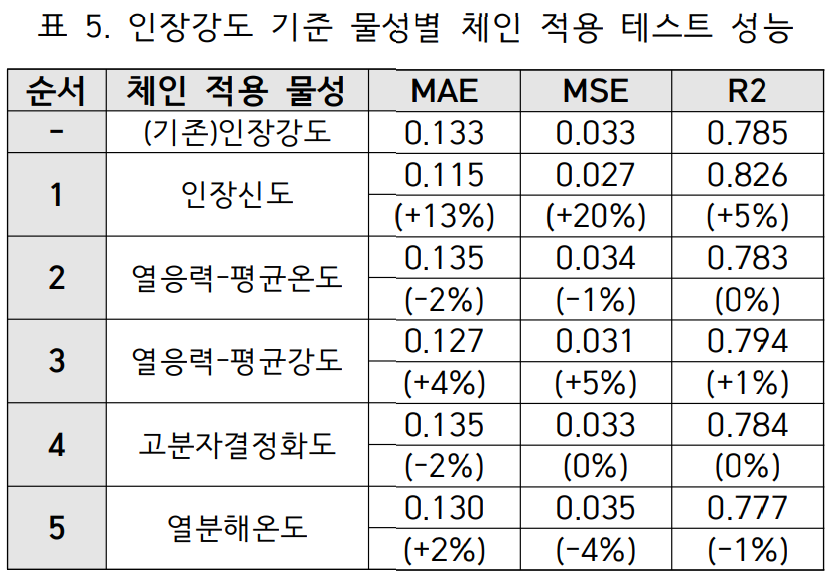
- 실험 결과 (표 5):
- (기존) 인장강도 단일 모델 성능: MAE 0.133, MSE 0.033, R² 0.785
- (체인 적용 1) 인장신도와 체인: MAE 0.115 (+13% 개선), MSE 0.027 (+20% 개선), R² 0.826 (+5% 개선)
- (체인 적용 2) 열응력-평균온도와 체인: MAE 0.135 (-2% 저하), MSE 0.034 (-1% 저하), R² 0.783 (유지)
실험 결과, 데이터 변동률 상관 분석에서 강한 종속성을 보인 인장신도를 체인으로 활용했을 때 예측 성능이 모든 지표에서 크게 향상되었다. 반면, 직접 상관 분석에서만 약한 종속성을 보였던 열응력-평균온도를 체인으로 사용했을 때는 오히려 성능이 저하되었다. 이 결과는 데이터 불균형이 심한 데이터셋에서는 직접적인 상관 분석보다 데이터 변동률 기반의 종속성 평가가 회귀 체인 모델의 성능 향상에 더 효과적임을 명확히 보여준다.
결론 (Conclusion)
본 논문에서는 데이터 분포가 불균형한 생분해성 섬유 원사 데이터의 물성 예측 성능을 높이기 위해, 기존의 상관 분석 대신 데이터 변동률을 이용해 물성 간 종속성을 평가하고 이를 회귀 체인에 적용하는 방법을 제안했다. 주요 물성인 인장강도를 대상으로 한 검증 실험 결과, 제안한 방법이 잘못된 종속성으로 인한 오류 전파 문제를 해결하고 예측 모델의 성능을 효과적으로 개선할 수 있음을 입증했다. 이 연구는 불균형한 산업 데이터에서 변수 간의 숨겨진 종속성을 파악하고 이를 모델링하는 데 새로운 접근법을 제시했다는 점에서 의의가 있다.